Système d'exploitations
Cours de B2 AKA OS
- Introduction
- Le langage C
- Introduction aux laboratoires
- Introduction au C
- Hello World
- Chaines de caractères (et tableaux)
- Génération d'aléatoire
- Les structures
- Les tableaux
- Les processus
- La mémoire
- Le système de fichiers
- Entrées sorties
- Sécurité
- Protection, domaine et matrice d'accès
- Sécurité contre les attaques
- Authentification
- Sécurité des applications, attaques et logiciels malveillants
- Protection contre les attaques
- Introduction et histoire de la cryptographie
- Cryptographie symétrique et asymétrique
- Signatures cryptographiques
- Résumé global
Introduction
Informations horarires, crédits, seconde sess
Les cours théoriques représentent 42h et les laboratoires représentent 35h. Le cours vaut 6 crédits ECTS et est fini en janvier. La seconde session est en septembre et il est préférable de ne pas devoir présenter le sdeux parties du cours pendant la même session vu le volume conséquent de matière !
Laboratoires
Les laboratoires permettent d'illustrer les nombreux concepts étudiés en cours et se réalisent dans un environment UNIX (Linux, macOS X, BSD, etc).
Répartition des points
Le cours de C est plus tôt bien réussi mais celui d'OS pas tellement.
- 40% de la note est consacrée aux laboratoires et aux interrogations durant l'année
- 60% de la note correspond à l'examen oral de 1er session en Janvier.
Si on a réussi le labo mais pas la théorie ou inversément, on doit uniquement représenter la partie ratée en seconde sess. Mais si on rate l'un des deux en seconde sess, on est obligé de représenter les deux l'année suivante.
Prérequis
- Notion d'architecture
- Notions de programmation
Contact
Pas de contact via Teams, il vaut mieux priviléger les mails et le forum sur Moodle.
Mind map
Une mindmap est autorisée pour répondre aux questions à l'oral. L'oral a des questions de base qui sont connues à l'avance auquel il faut se préparer. Les conditions sur ce qui peut se trouver sur cette mind map seront évoquées plus tard
Définition d'un système d'exploitation
Le système d'exploitation peut être vu sous deux aspects :
- Une extension du matériel, permettant de fournir des interfaces aux programmes vers le matériel.
- Le SE (Système d'Exploitation) est responsable de l'attribution de la gestion des différentes ressources (CPU, mémoire, etc)
Exemples de systèmes d'exploitations
- Windows
- macOS X
- Distributions Linux (Android, Debian, Arch Linux, Alpine, etc)
- OpenBSD, FreeBSD, NetBSD
- Solaris
- Novel netware (RIP)
- IBM OS2 (RIP)
Tour d'horizon
Systèmes Windows
- Les systèmes basés sur MS-DOS : DOS, Windows 3.1, Windows 95, Windows 98, Windows ME
- Les systèmes basés sur NT : Windows 7, Windows 10, Windows 11, etc
- Les systèmes mobiles : Windows CE, Windows Phone, Windows Embedded
Systèmes UNIX

Il existe énormément de systèmes UNIX qui se sont développé depuis les années 60, UNIX inclus entre autres macOS, Linux ou BSD. Si ça vous intéresse je vous invite à aller lire la page Wikipedia sur l'histoire de UNIX et la page Wikipedia sur UNIX.
Processeur
Le CPU est l'unité centrale de traitement de l'ordinateur.
Les registres sont des zones mémoires attachées au processeur
Il existe deux modes :
- Le mode protégé (ou mode noyau ou encore mode "kernel") qui permet d'avoir un accès complet à l'ensemble du matériel
- Le mode utilisateur qui le mode dans lequel les programmes sont lançés.
Les appels systèmes sont des moyens/fonctions mis en place par le SE pour permettre aux programmes utilisateurs de demander des services au système d'exploitation.
Les programmes n'ont jamais un accès direct au matériel et doivent toujours passer par le SE.
Appels systèmes
Les appels systèmes sont des mécanismes par lequel on demande au SE un service (open, close, read, write, printf, scanf, etc) sont des appels systèmes.
Le SE peut par exemple alouer des ressources (mémoire par exemple) ou encore gérer les périphériques (souris, clavier, écran, etc).
Multithreading
Le multithreading (ou même l'hyperthreading) permet de faire travailler plusieurs "morceaux de programmes" en même temps sur un processeur. Le fait d'avoir plusieurs actions simultannées s'appelle le paralélisme
Il y a aussi les processeurs multicoeurs qui ont plusieurs CPU au sein d'une même puce.
Vous pouvez en savoir plus sur le multithreading, l'hypethreading et le multicoeurs en lisant cet article.
Mémoire
C'est un élément essentiel de l'ordinateur, et pour qu'un programme s'exécute, il faut que toutes ses données soient en mémoire.
Il existe plusieurs niveaux de mémoire : les registres, la mémoire cache (niveaux 1,2,3), mémoire centrale/RAM.
La mémoire est volatile, une fois déconnectée, elle ne conteint plus aucune information.
La mémoire étant une ressource partagée, il faut qu'elle soit gérée efficacement (allocation adaptée aux besoins, nécessité de pouvoir satisfaires, ne pas gaspiller les ressources, etc).
La taille de la mémoire peut aller de quelques Ko à plusieurs Go.
Disque dur
Le disque dur est non-volatile et a des performances moins bonne que la RAM, cependant son coût est plus bon marché, avec généralement plus de stockage (allant de plusieurs Go à quelques To).
Il existe des technologies variées pour ce dernier : SATA, SCSI, SAS, SSD, etc.
Attention aux backups
Il faut bien faire des backups régulièrement autant de son ordinateur que des serveurs, les backups sont la dernière ligne de défense en cas de cyber attaque ou domage matériel.
Il faut également se rappeller que les clés USB ne sont pas un moyen fiable de stoquer de l'information, les clés USB peuvent servir à transférer de l'information mais pas de la stoquer à long terme.
Règle des trois
- 2 backups à des endroits différents
- 1 backup air-gapped (hors-ligne)
Backup en ligne
Une bonne méthode pour faire des backups plus souvent est de mettre ne place un système automatique pour faire des backups de son ordi/serveur sur des serveurs distants.
De plus pour protéger les données c'est une bonne idée de chiffrer les backups (ainsi même l'opérateur·ice du serveur ne pourra pas lire les données). Si on veut être 100% maître de ses backups on peut également héberger un serveur soi-même et utiliser rsync pour le backup.
Stockage
Le stockage est un enjeu d'avenir car la taille de l'information grandit, et une gestion efficace est nécessaire pour retrouver l'information souhaitée. Il faut donc stocker beaucoup de données tout en pouvant assurer une certaine performance et fiabilité en combinant par exemple plusieurs disques dans un système RAID (on réparti l'information sur plusieurs disques pour pouvoir améliorer la fiabilité et la performance).
Entrées sorties
Un ordinateur doit absolument pouvoir communiquer à l'extérieur aujourd'hui. L'ordinateur doit donc être capable de communiquer avec des périphériques extérieurs :
- Claviers, souris, écrans
- Cartes réseau, bluetooth
- Webcam
- Imprimante, scanner
Driver/pilote
Le SE dialogue avec un contrôleur sur lequel le périphérique est connecté, pour cela le SE doit utiliser un pilote (driver) adapté pour le matériel connecté qui va réaliser l'échange entre le controleur et le SE.
Ce dernier s'exécute en mode noyau (kernel) et est écrit par le fabriquant.
Virtualisation
La virtualisation est un concept inventé par IBM dans les années 70 qui permet de simuler un environmenet matériel différent (émulateur, virtualbox, etc).
Il permet d'exécuter plusieurs systèmes d'exploitations sur la même machine physique afin d'optimaliser l'utilisation des processeurs.
Il permet aussi de réduire les coûts des datacenter car il y a moins de machines physiques nécessaires.
On peut donc allouer la mémoire et le CPU en fonction des besoins (cloud computing, plus le besoin augmente, plus au augmente la mémoire allouéee)
Il existe des systèmes d'exploitations orientés VM comme VMWare-ESXhi, Hypr-V ou XEN.
La virtualisation est aussi pratiquée par des systèmes comme Docker.
On peut même faire en sorte de partager les ressources entre plusieurs serveurs (comme ça si il y a beaucoup de traffic, 2 serveurs peuvent répondre à la charge ou encore si un serveur est down, un autre peut prendre le relai). C'est notament le cas de VMWare-ESXhi ou Kubernetes (Docker).
Plan du cours
- Gestion des processsus (permettre à plusieurs programmes de s'exécuter en même temps sur le système)
- Gestion de la mémoire (répartition des ressources)
- Gestion du système de fichiers (gérer efficacement le système de fichiers)
- Gestion des entrées-sorties (dialogue entre les périphériques)
- Gestion de la sécurité (garantir la sécurité des informations avec le chiffrement)
Le langage C
Partie du cours d'OS sur le langage C
ATTENTION, ce chapitre n'est pas complet
Introduction aux laboratoires
Outils
- Linux (une machine virtuelle est disponible sur l’espace de cours)
- Clion (Jetbrains) est l’IDE recommandé pour le C et C++ (mais bon vim, emacs, helix et tout sont bien aussi hein)
Exam
L’examen de janvier se fait par deux interogation :
- Interogation C le 25/10
- Interogation OS le 20/12
La seconde session se fait en examen en session à l’interrogation OS. A savoir que les intérogations se font normalement à cours ouvert.
Ressourcess
- Vidéos de Swinnen sur le Swilabus
- Les PDF de théorie de chaque chapitre sur l’espace de cours
- Les séances de laboratoires pour avoir des informations complémentaires
Conseils
- Lire le document du chapitre avant le cours
- Regarder la vidéo de Swinnen qui corresponds
- Assister aux séances de labo pour avoir des informations complémentaires et faire les exercices en présence du prof et des autres élèves.
- Bien suivre le calendrier de cours disponible sur l’espace du cours
Note : Le labo 2 a été annulé
Setup
Virtual machine
Il est recommandé d’utiliser la machine virtuelle Fedora disponible sur l’espace de cours qui vient préinstallée avec l’IDE “Clion” de Jetbrains.
Pour l’ajouter vous devrez installer le logiciel gratuit (et open source) Virtual Box dans laquelle vous pouvrez ensuite importer la VM et la lancer.
Avec un IDE (clion)
Si vous êtes sur macOS ou Linux cependant, vous pouvez aussi simplement installer Clion car macOS et Linux sont des systèmes UNIX-like, ce qui signifie qu’ils sont compatibles.
Ensuite il ne faut pas oublier de suivre les étapes données sur l’espace de cours pour y inclure les flags de compilations (qui vont donner des règles supplémentaires et afficher des warnings lors de la compilation de vos programmes).
Manuellement
Si vous êtes sur Linux, WSL (Windows Subsystem for Linux) ou macOS, vous pouvez aussi ne pas utiliser d’IDE et installer gcc (version 13.2) et y inclure les flags de compilation.
Par exemple vous pouvez faire un alias de la commande gcc comme suit :
echo 'alias gcc="gcc -std=iso9899:1990 -Wpedantic -Wall -Werror"' >> ~/.bashrc
source ~/.bashrc
Vous pouvez avoir plus d’information sur l’utilisation de gcc en consultant son manuel d’utilisation (man gcc) ou en allant voir sur internet comment l’utiliser (vous pouvez aussi aller voir une cheatsheet ici).
Introduction au C
Qu’est ce que le C
Le langage C est un langage de bas niveau (contrairement à Java qui est plus un langage de haut niveau). Le langage C est de moins en moins utilisé directment mais de nombreux langages ont été fait à partir de C tel que C++, Java, PHP, Python ou PERL.
Paradigme impératif
Contrairement à Java qui fonctionne dans un paradigme orienté objet, C est un paradigme impératif, comme dans Java on manipule des données en indiquant instruction par instruction comment construire un résultat. Cependant à la différence de Java, il n’y a pas de notion d’objet, de polymorphisme, ou d’héritage (car cela est propre au paradigme orienté objet).
En C on manipule uniquement des types structurés (types très basique, comme des classes qui n’aurait aucune méthode), des fonctions, des tableaux, des chaines de caractères ou des pointeurs.
Histoire du C
Le C a été développé dans les années 70 dans le but de créer un langage plus adapté pour écrire la nouvelle version d’un système d’exploitation nomé Unix, qui sera le parent (indirect) des systèmes Linux, BSD ou encore macOS. Même si C a été développé il y a pas mal de temps, il continue toujours à évoluer aujourd’hui.
Utilisation du C
Le langage C est beaucoup utilisé pour tout ce qui touche au système d’exploitation, et également dans des ordinateurs qui n’ont que très peu de ressources tel que les Arduino ou les Raspberry Pi.
Objectifs du cours de C
Le but du cours sur le C n’est pas de devenir programmeur C mais bien de pouvoir créer de petites applications systèmes en C. Il est égalment important de faire un certain travail à domicile car les 14 heures de laboratoires ne seront pas suffisantes pour bien comprendre les concepts.
Environement de développement et configuration
Il existe de très nombreux environements de développement permettant de coder en C. Notament VS Code, vim, emacs, helix, clion ou encore Code Blocks. Les éditeurs recommandés pour le cours sont Code Blocks (gratuit et open source) et/ou clion (un éditeur de JetBrains propriétaire et payant, cependant des clés d’accès sont fournie par HELMo).
Quoi qu’il arrive, votre environement de développement doit être configuré pour :
- Utiliser
gcc 13.2 - Utiliser les flags de compilation suivants :
-std=iso9899:1990 -Wpedantic -Wall -Werror(plus d’information sur comment les configurer pour clion sont disponible sur la page du cours)
Hello World
/* Les lignes commençant par # sont des directives au préprocesseur C
Dans ce cas avec #include c'est une sorte d'import qui dit qu'il fait inclure une librairie. Dans ce cas on importe les librairies standard stdio et stdlib */
#include<stdio.h>
#include<stdlib.h>
/* Le programme principale exécuté se trouve dans la fonction main */
int main(void) {
/* Printf vient de la librarie stdio et permet d'afficher du texte dans la console */
printf("Hello World !\n");
/* A la fin de tous les programmes en C, il retourne un entier. 0 dans le cas d'un succès (qui est déjà présent dans la constante de stdlib EXIT_SUCCESS); ou 1 dans le cas d'un échec (constante EXIT_FAILURE de stdlib).
Cela permet d'indiquer à des programmes qui utiliserait celui-ci, si l'exécution s'est bien passée ou non */
return EXIT_SUCCESS;
}
Libraries standard en C
Le langage C définit un certain nombre de librairies standard. Parmis celles ci, en voici 5 qui seront beaucoup utilisée dans ce cours d’introduction au C :
| Librarie | Usage |
|---|---|
| stdio.h | Nécessaire pour les entrées sorties standard (gestion clavier et écran). A inclure dans tous les programmes |
| stdlib.h | Reprends les constantes et les fonctions importantes. A inclure dans tous les programmes également |
| string.h | Reprends les fonctions de manipulation de chaine de caractères (comparaison, copie, recherche, concaténation, etc) |
| math.h | Reprends les fonctions mathématiques (puissances, trigonométrie, etc) |
| time.h | Manipulation de la date et de l’heure |
Processus de compilation
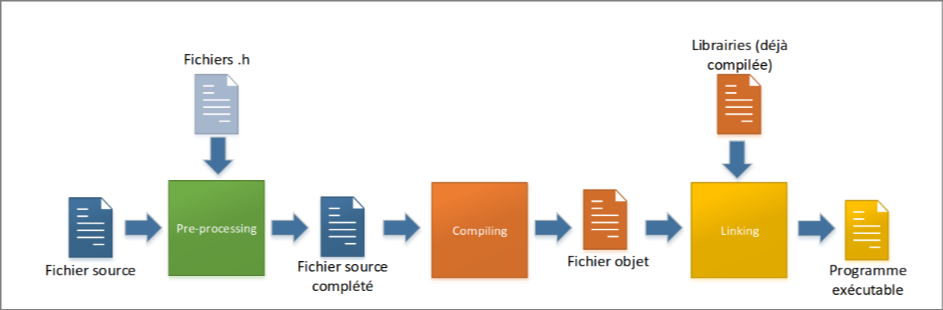
- Tout commence avec les fichiers source, c’est à dire les fichiers d’extension
.c. - Ensuite la phase de pre-processing va inclure les fichiers en-tête (sur lesquels on va revenir plus tard, mais ceux-ci contiennent les signatures des fonctions des libraries à importer). De cet étape de pre-processing, va résulter un fichier contenant tout le code source du projet + le contenu des fichiers en-têtes.
- Une fois la pre-processing finie, la compilation du fichier commence, ce qui résulte avec un fichier objet
.o. - Ensuite la partie suivante est le linking qui va lier les librairies au fichier
.opour donner le fichier exécutable final.
Déconstruire le processus de compilation en ligne de commande
Si vous voulez essayer (de le faire manuellement) par vous même, vous pouvez faire les commandes suivantes :
- Fichier .c : créer simplement un hello world comme montré plus haut dans un fichier
hello.c - Précompilation :
gcc -E hello.c - Compilation :
gcc -c hello.c - Linking :
gcc hello.o -o hello
Compilation manuelle et console
Si vous voulez compiler le code par ligne de commande vous n’avez pas besoin de taper plein de commandes. Il suffit juste de faire gcc \*.c cependant il faut faire attention à plusieurs choses :
- Toujours inclure tous les fichiers .c dans la commande gcc
- Faire attention à la version de gcc
- Ne pas oublier d’ajouter les flags de compilations (qui donne des instructions suplémentaires au compilateur) à la commande gcc pour les projets de l’école
Notions fondamentales
/* Tout d'abord on doit inclure les librairies stdio et stdlib dans tous les projets. On a déjà parlé de ce que fait le #include dans le bloc de code Hello World */
#include<stdio.h>
#include<stdlib.h>
/* On donne les signatures des méthodes présentes dans le fichier dès le début car le compilateur C va lire le fichier de haut en bas et doit pouvoir directement savoir quelles fonctions existent dans le fichier */
float ajoute(float, float);
float soustrait(float, float);
float multiplie(float, float);
float divise(float, float);
/* La fonction main est le programme principale, ce qui va être exécuté lorsque l'on lance l'exécutable compilé du code */
int main(void) {
/* Dès le début de la fonction on est obligé de déclarer nos variables */
float n1, n2, resultat;
char operation;
/* Printf vient de stdio et permet d'afficher du code dans la console. Le caractère \n sert à retourner à la ligne */
printf("Calculatrice simple\n");
printf("Entrez l'opération à réaliser :");
/* Scanf permet de récupérer un input d'un utilisateur dans la console. %f définissant un nombre flotant, %c un caractère et %*c servant à éliminer le denier caractère (le \n, soit le retour à la ligne) */
/* Ces 3 valeurs (2 nombre flotatnts et un caractère) seront donc stoqué dans 3 variables (on passe donc les ADDRESSES de n1, opération et n2 en préfixant les variables d'un &) */
scanf("%f %c %f%*c", &n1, &operation, &n2);
/* Le switch en C ne fonctionne qu'avec des valeurs entières. Par exemple ici '+' correspond à la valeur entière 43 dans la table ASCII. */
switch(operation) {
case '+':
resultat = ajoute(n1, n2);
break;
case '-':
resultat = soustrait(n1, n2);
break;
case '*':
resultat = multiplie(n1, n2);
break;
case '/':
resultat = divise(n1, n2);
break;
}
/* Le printf ici fonctionne avec le même type de syntaxe que le scanf vu plus tot */
printf("==> %f %c %f = %f\n", n1, operation, n2, resultat);
/* Enfin on retourne l'exit code du programme, ici un succès */
return EXIT_SUCCESS;
}
/* Les méthodes annoncées dans l'en-tête plus haut sont définie ici */
float ajoute(float nombre1, float nombre2) {
return nombre1 + nombre2;
}
float soustrait(float nombre1, float nombre2) {
return nombre1 - nombre2;
}
float multiplie(float nombre1, float nombre2) {
return nombre1 * nombre2;
}
float divise(float nombre1, float nombre2) {
return nombre1 / nombre2;
}
Types en C
Les types de C sont très basiques contrairement à ceux d’autres langages (de plus haut-niveau) tel que Java.
| Type | Explication | Codé sur | Représentation dans printf/scanf | Valeurs admissibles |
|---|---|---|---|---|
char |
Destiné à contenir un seul caractère. Il y a une conversion automatique char en type entier, ainsi ’c’ en char deviendra 99 (sa valeur ASCII) en entier | 8 bits | %c |
Tous les caractères codés sur 8 bits |
short |
Destiné à contenir des valeurs entières petites | 16 bits | %hi |
De $-2^{15}$ à $+2^{15} - 1$ |
int |
Destiné à contenir des valeurs entières | 32 bits | %i ou %d |
De $-2^{31}$ à $+2^{31} - 1$ |
unsigned int |
Destiné à contenir des valeurs entières non signées (strictement positives) | 32 bits (mais 16 bits minimum) | %u |
De $0$ à $+2^{32} - 1$ |
long int |
Destiné à contenir de grandes valeurs entières (cependant sous Unix, il est la même que int) |
32 bits minimum | %li |
De $-2^{31}$ à $+2^{31} - 1$ |
long long int |
Destiné à contenir des plus grandes valeurs entières | 64 bits | %lli |
De $-2^{63}$ à $+2^{63} - 1$ |
float |
Destiné à contenir des valeurs avec fraction décimale (précision simple) | 32 bits | %f |
|
double |
Destiné à contenir des valeurs avec fraction décimale (plus précis) | 64 bits | %lf |
C ne dispose pas de type booléen, cependant la valeur entière 0 est toujours considérée comme FAUX et tout autre valeur est considérée comme VRAI.
Plus de représentation printf et scanf
Caractères spéciaux
| Symbole | Signification |
|---|---|
\n |
Caractère de controle LF qui fait un retour à la ligne sous Linux |
\r |
Caractère de controle CR. \r\n provoque un retour à la ligne sous Windows |
\t |
Tabluatino vers la droite |
\\ |
Caractère \ |
%% |
Caractère % |
Autres types non élémentaires
| Symbole | Signification |
|---|---|
%s |
Chaine de caractère |
x |
Donnée unsigned int au format hexadécimal |
Précision de l’affichage
| Symbole | Signification | Valeur | Affichage |
|---|---|---|---|
%3d |
Donnée formattée sur 3 chiffres, les absences de chiffres sont remplacées par des espaces | 9 |
9 |
%03d |
Même chose mais les espaces sont remplacés par des 0 | 9 |
009 |
%.2f |
Permet de préciser le nombre de chiffres derrnière la virgule d’un valeur fractionnelle | 9.191 |
9.19 |
Fonctions et protoypes
Les signatures des fonctions comme mises au début du fichier de la calculatrice sont appellé des prototypes ou des signatures de fonction. Elles annoncent les fonctions qui vont être présentes.
Sauf qu’en vérité, ces signatures sont dans des fichiers séparés appellée en-têtes dans des fichiers .h.
Ces fichiers sont ensuite inclus dans le programme en utilisant #include "file.h".
Lorsque l’on inclu un code on inclu toujours le fichier en-tête et jamais le fichier .c. A noter que si on veut importer un fichier en-tête bien précis in peut specifier le chemin d’accès entre guillemets (exemple #include "file.h") mais lorsque l’on veut ajouter une librarie standard, on va la mettre entre chevrons (exemple #include <stdio.h>)
Lorsque l’on a plusieurs fichiers dans un projet C, il est important de bien garder la règle d’un seul dossier par projet, sinon ça risque fort de foutre la merde. Lorsuqe
Chaines de caractères (et tableaux)
En C il n'y a pas de type String, les chaines de caractères sont
simplement des tableaux de caractères. Sauf que puis ce que l'on ne sait
pas combien de la longueur du tableau a été replis, donc on met un
caractère de fin de chaine à la fin du tableau \0.
char ma_chaine[21] = "Hello World!\n";

Il est très important de toujours vérifier l'input des utilisateur·ice·s
car si la personne entre quelque chose de plus long que la taille du
tableau cela peut être une faille de vulnérabilité (car cela peut mener
à un BufferOverflow). C'est notament arrivé au programme sudo sous
linux. Si vous voulez en apprendre plus vous pouvez regarder cette
vidéo.
Lecture des chaines de caractères
Il existe par exemple gets(), scanf() ou encore fgets() pour
prendre un input de l'utilisateur·ice.
Cependant il ne faut pas utiliser gets() car il ne vérifie pas la
taille des données (ce qui peut donc mener à un BufferOverflow). Il faut
donc toujours utiliser scanf ou getf.
scanf
Voici par exemple comment récupérer les max 20 premiers caractères d'un input (le reste sera ignoré).
scanf("%20[^\n]%*c", ma_chaine);
Pour déconstruire un peu ce qu'il se passe ici :
-
%20signifique que l'on prends les 20 premiers caractères -
[^\n]signifie que l'on arrete de prendre des caractères quand l'utilisateur·ice fait ENTER -
%*csignifie que l'on ignore le dernier caractère (le retour à la ligne\n)Autre chose intéressante à noter ici, il n'y a pas de
&devant le nom de la fonction contrairement à avant quand on récupérait des caractère ou nombres uniques. Cela est dû au fait que&sert à passer l'addresse d'une variable (le pointeur) et qu'un tableau (comme une chaine de caractère) est déjà une addresse (pointeur).
fgets
fgets fonctionne assez différemment de scanf, voici comment on peut
faire quelque chose de similaire à l'exemple précédent en utilisant
fgets :
fgets(ma_chaine, 20, stdin);
Attention cependant que fgets compte \n comme un caractère et l'inclus
dans le résultat. Donc bien que la syntaxe de fgets soit plus simple, il
faut mieux utiliser scanf car elle s'occupe du caractère \n toute
seule.
Affichage des chaines de caractères
puts
L'exemple suivant va afficher la chaine de caractère en y ajoutant un
retour à la ligne automatiquement à la fin (c'est tout l'interet du
puts), c'est un peu comme le System.out.println en Java :
puts(ma_chaine);
fputs
Cet exemple fonctionne de manière similaire du puts sauf qu'il
n'ajoute pas de retour à la ligne. C'est un peu comme le
System.out.print en Java.
fputs(ma_chaine, stdout);
printf
Printf est surtout intéressant pour formatter l'affichage (c'est
l'équivalent du System.out.printf en Java).
printf("%s\n", ma_chaine);
Autres fonctions
Il existe une librarie string en C permettant d'intéragir plus
facilement avec les chaines de caractères. Attention cependant, il ne
faut pas la confondre avec le type String en Java, car en C "string"
n'est pas un type les chaines de caractères sont simplement des tableaux
de char
Pour importer la librarie string, il suffit d'ajouter la ligne suivante au dessus du fichier :
#include <string.h>
Maintenant voici une petite listes des fonctions les plus utiles de string :
| Fonction | Explication |
|---|---|
strlen(ma_chaine) |
Compte le nombre de caractères de la chaine jusqu'au \0 |
strncmp(chaine1, chaine2, n) |
Compare les n premiers caractères des chaines. Si les deux sont les même cela signifie que les deux sont identiques |
strncpy(dest, source, n) |
Copie les n premiers caractères de la source vers la destination (le \0 n'est pas ajouté) |
sprintf(dest, "%d + %d", 4, 5) |
Fait comme printf sauf qu'à la place de l'afficher, il le stoque dans une variable. C'est comme le String.format en Java |
sscanf(src, "%d + %d", &a, &b) |
Fait comme le scanf sauf qu'a la place de le demander depuis le stdin (standard input), il va le prendre depuis une chaine de caractère source |
memset(src, n, 0) |
Initialise les n premiers caractères de la chaine src avec le caractère mentioné (ici on remplace tout par \0) |
strchr(chaine, car) |
Recherche la première occurence d'un caractère dans une chaine et retourn eun pointeur vers celle-ci |
strstr(chaine, sous-chaine) |
Recherche la première occurence d'une sous-chaine donnée dans une chaine et retourne un pointeur vers celle-ci. |
Exemple de manipulation de tableau/chaines
/* Stoquer une chaine dans un tableau */
char ma_chaine[20+1] = "Hello, World!";
/* Accéder au 5e caractère de la chaine */
printf("Le 5e caractère est %c\n", ma_chaine[4]);
/* Modifier un caractère */
ma_chaine[4] = ' ';
/* On peut aussi mettre le \0 n'importe où pour couper une chaine */
ma_chaine[4] = '\0';
printf("La chaine est maintenant : %s\n", ma_chaine);
Génération d'aléatoire
La généréation d'aléatoire se fait via la fonction rand, cependant il
est important de se rappeller que l'aléatoire en informatique n'existe
pas, on parle ici de pseudo-aléatoire.
Le fonctionnement de la fonction c'est que rand va prendre un nombre de
départ (appelée seed qui par défault est 1) et va y faire des
opérations pour que le nombre ai l'air aléatoire.
Ensuite le nombre produit va être utilisée comme seed pour générer d'autres nombres aléatoires par la suite.
Ce qui veut dire que par défault, ce programme donnera toujours les même valeurs :
printf("%d\n", rand()); /* 1804289383 */
printf("%d\n", rand()); /* 846930886 */
printf("%d\n", rand()); /* 1681692777 */
Pour avoir quelque chose qui se rapproche un peu plus de l'aléatoire, on peut fixer le seed pour être autre chose au début du programme, typiquement, le temps (UNIX time, qui est le nombre de secondes depuis le 1/1/1970 00:00 UTC).
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
int main(void) {
srand(time(NULL));
printf("%d\n", rand());
printf("%d\n", rand());
printf("%d\n", rand());
return EXIT_SUCCESS;
}
Dans ce nouvel exemple on a fixé le temps comme étant le seed du rand, ainsi deux programmes ne s'exécutant pas dans la même seconde auront des résultats différents qui auront l'air aléatoire.
Les structures
Les structures en C permettent de créer des types personalisés, un peu comme les classes en Java mais sans méthodes (askip c'est possible de faire des méthodes mais c'est très peu commun et donc pas expliqué dans ce cours).
Il existe deux manière de faire une structure en C mais il vaut mieux toujours rester consistent sur la manière utilisée.
Voici une première manière de faire une structure en C :
struct etudiant {
int matricule;
char nom[50+1];
char prenom[50+1];
char adresse[200+1];
char telephone[15+1];
float moyenne;
};
Ensuite pour déclarer une variable :
struct etudiant un_etudiant;
Et voici la seconde manière de faire :
typedef struct {
int matricule;
char nom[50+1];
char prenom[50+1];
char adresse[200+1];
char telephone[15+1];
float moyenne;
} Etudiant;
Et ensuite pour déclarer une variable :
Etudiant un_etudiant;
Lecture et écriture des données
Etant donné qu'il n'y a pas de méthodes aux structures, il n'y a pas de
modificateur private sur les attributs, les attributs peuvent donc
être accédé et modifié sans limite.
/* Lecture d'un struct */
printf("%s %s\n", un_etudiant.nom, un_etudiant.prenom);
/* Ecriture d'un struct */
un_etudiant.matricule = 123456;
Partage des structures entre programmes
Pour partager les structures entre plusieurs programmes on peut
simplement mettre la déclaration du struct dans un fichier en-tête
(.h).
Les tableaux
Il est possible en C de déclarer un tableau contenant des données de types identiques qui sont ensuite rangées en mémoire dans des cases contigues.
Un tableau en C est une addresse mémoire (appelée pointeur) donc quand on demande le premier élément, on prends la première case au niveau du pointeur. Pour prendre le deuxième, on va une case plus loin et ainsi de suite.
Ce qui signifie que l'on peut aller plus loin que la taille réservée du tableau, lorsque l'on fait ça on dit que l'on "jardine en mémoire" ce qui est risqué car cela peut faire planter le programme et que les données en dehors du tableau peuvent être réécrites par d'autres variables dans le programme.
Définition d'un tableau
/* Définition d'un tableau de 10 entiers simple */
int suite[10];
/* Initialisation d'un tableau de 5 entiers */
int suite[10] = { 1,2,3,4,5 };
/* Lecture du troisième élément d'un tableau */
printf("%d\n", suite[2]);
/* Ecriture d'un élément du tableau */
suite[2] = 42;
Attention à l'initialisation des variables et tableaux
Cela veut aussi dire que si un tableau n'est pas initialisé, si on récupère une position qui n'a pas encore été définie on peut tomber sur d'anciennes valeurs encore dans la mémoire.
C'est pour cela qu'il faut généralement garder une variable
supplémentaire pour garder le compte du nombre de cases écrites du
tableau (cela n'est pas nécessaire pour les chaines de caractère car on
sait que la chaine se finit au caractère \0). La longueur des données
réelement dans un tableau est appellée "taille effective" tandis que la
talile en mémoire du tableau est appellée taille physique.
Pour ce qui est des variables c'est pareil, par défault les variables ne sont pas initialisées (bien que cela peut varier des OS et des compilateurs). C'est pourquoi il vaut toujours mieux intialiser les variables. Car les variables sont simplement des addresses mémoires, donc si on lit une variable non initialisée on va lire les données qui sont à cet endroit dans la mémoire (il peut donc y avoir un peu n'importe quoi).
Voici un exemple de code permettant de tester cela :
#include <stdio.h>
#include <stdlib.h>
int main(void) {
/* On crée une variable non initialisée */
int ma_variable;
/* On demande à sscanf d'initialiser la variable à partir de rien : spoiler il va pas l'initialiser */
sscanf("", "%d", &ma_variable);
/* On lit la variable non initialisée */
printf("Ma variable non-initialisée vaut : %d\n", ma_variable);
return EXIT_SUCCESS;
}
Tableaux et fonctions
On peut passer des tableaux en arguments de fonctions cependant étant donné que le tableau est un pointeur il ne sera pas copié car c'est bien sa référence qui sera passée à la fonction.
Une conséquence de ça c'est qu'une fonction en C ne peut pas retourner un tableau, pour traiter des tableaux il vaut mieux passer le tableau en argument, le modifier dans la fonction et retourner la taille effective du tableau sous forme de int.
Voici un exemple simple d'utilisation de tableaux dans des fonctions :
#include <stdio.h>
#include <stdlib.h>
int add_42(int tableau[], int taille_tableau);
int main(void) {
/* On crée un tableau avec une taille de 10 contenant 3 éléments */
int tableau[10] = {1,2,3};
/* On note la taille effective du tableau comme étant 3 (pour les 3 éléments) */
int taille_tableau = 3;
/* On passe le tableau et la taille dans la fonction qui va modifier le tableau et retourner la nouvelle taille */
taille_tableau = add_42(tableau, taille_tableau);
/* On affiche le nouvel élément de notre tableau */
printf("Le nouvel élément du tableau est %d\n", tableau[taille_tableau - 1]);
/* On ferme le programme */
return EXIT_SUCCESS;
}
/* On défini une fonction retournant un entier (nouvelle taille), un tableau de taille indéfinie, et la taille effective du tableau */
int add_42(int tableau[], int taille_tableau) {
tableau[taille_tableau] = 42;
return taille_tableau + 1;
}
Les processus
Les processus
Un processus est un programme en cours d'exécution.
Un programme est donc un élément passif (un ensemble d'octets sur le disque) tandis qu'un processus est un élément actif (un programme en cours d'exécution).
Que comporte un processus ?
- Le code du programme
- Le program counter (à quel instruction on est dans le programme, qui permet de savoir quelle sera la suivante) et les registres
- La pile (stack) et les données du programme
Informations concernant le processus
- PID (process ID) qui est l'identifiant du processus
- PPID (parent process id) qui est l'identifiant du processus parent
- Priorité du processus
- Temps CPU : temps consommé au CPU
- Tables des fichiers
- Etat du processus
Etat
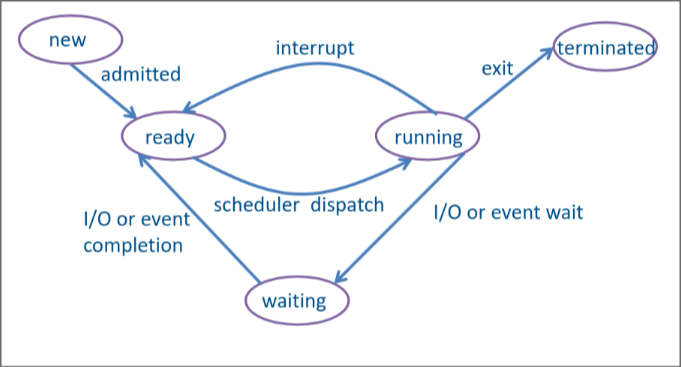
- new correspond à un programme qui a été sélectionné pour être démarré, ses instructions ont été recopiées en mémoire par l’OS et un nouveau processus y a été attaché mais pas encore exécuté, son contexte d’exécution et ses détails n’ont pas encore été préparés.
- ready le processus a été créé et dispose de toutes les ressources pour effectuer ses opérations
- running le processus a été choisi par le scheduler pour tourner, il va donc exécuter ses instruction jusqu’a écoulement du temps imparti. Si il a besoin de plus de ressource, il passe dans l’état waiting, si il a terminé son exécution il passe en état terminated sinon il peut encore passé en ready si un processus de plus haute priorité arrive.
- waiting le processus est en attente d’un évènement (exemple appui d’un bouton ou écoulement d’un certain temps) ou de ressources (exemple lecture de disque). Le processus ne peut rien faire pour l’instant.
- terminated une fois que le processus est terminé (ou a été tué), il libère la totalité des ressources qu’il a déténues.
Vous pouvez avoir plus d’information sur ce sujet en consultant ce site.
Pour exécuter plusieurs processus
Le système alterne très vite entre les différents états pour donner l'illusion que plusieurs processus s'exécutent en même temps.
En somme on garde en mémoire les processus, le scheduler va choisir les processus à exécuter; lorsqu'un processus est en attente un autre processus va être sélectionné pour être exécuté. Le but du scheduler est de maximiser l'utilisation du CPU.
Le scheduler
Le scheduler va sélectionner le processus à exécuter, c'est lui qui va alterner entre les différents états de chaques processus.
Le scheduler utilise un algorithme précis et il doit être le plus rapide possible.
Le scheduler classifie les processus selon leur type :
- Processus CPU (calculs)
- Processus E/S (I/O, entrée sortie)
On va toujours vouloir priviléger les processus entrée-sorties, qui sont ceux qui dialogues avec l'utilisateur et qui vont donner l'illusion que les choses d'exécutent en même temps.
Changement de contexte
Pour changer de processus on doit pouvoir sauvegarder le contexte (les données) du processus précédent.
Le système va donc sauvegarder toutes les informations du processus pour pouvoir le redémarrer plus tard.
Ensuite le scheduler va sélectionner un autre processus et en charger les informations/contexte pour le démarrer.
Il va ainsi faire cela tout le temps pour alterner entre tous les processus en attente, prêts et en cours pour maximiser l'utilisation du CPU et donner l'illusion que tout fonctionne en même temps.
Création d'un processus (fork)
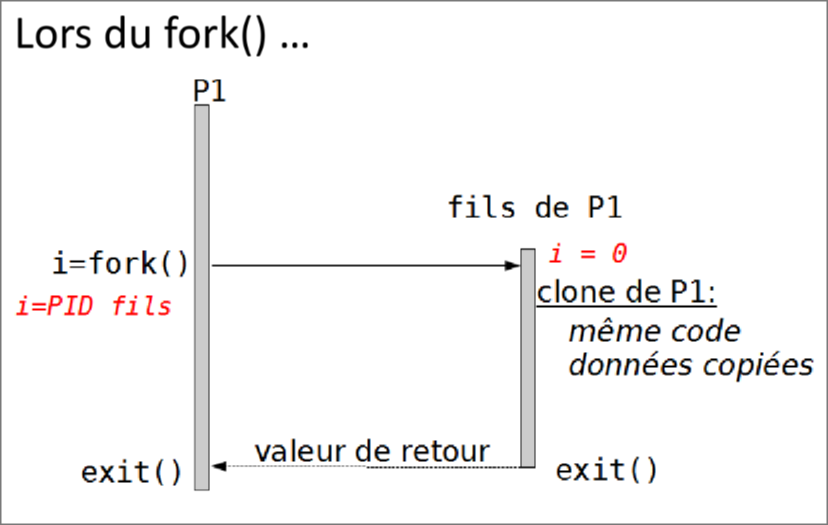
Pour créer un processus on utilise l'appel système fork. Le processus créé par un fork est appelé le processus fils, et le processus qui a créé le fils est appelé le père.
Le processus fils est un clone de son père, toutes les données du premier sont recopiées dans le fils.
La fonction fork() en C va retourner un entier :
-
-1si une erreur est survenue (comme souvent en C, une valeur négative veut dire qu'une merde s'est passée) -
0pour le processus fils - Le PID du fils pour le processus père
Exemples en C
Exemple simple
Voici un autre exemple :
#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>
#include <stdlib.h>
int main (void)
{
/* Variable pour stoquer la réponse du fork */
pid_t pid;
/* Fork et mise du résultat dans la variable */
pid = fork();
/* Si le pid est 0, alors c'est le fils qui lit l'info */
if (pid == 0) {
printf("Je suis le processus fils\n");
/* Si le pid est autre chose, alors c'est le père qui lit l'info */
} else {
printf("Je suis le processus père et mon fils est le : %d\n", pid);
}
/* Fin des deux processus */
return EXIT_SUCCESS;
}
Va retourner quelque chose comme :
Je suis le processus père et mon fils est le : 243328
Je suis le processus fils
Exemple plus complexe
#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>
#include <stdlib.h>
int main (void) {
/* La valeur de i par défault est 5 */
int i=5;
pid_t ret;
/* Ce code sera exécuté uniquement sur le père */
printf("Avant le fork() ... \n");
/* La valeur de retour sera 0 sur le processus fils, et le pid du fils sur le processus père */
ret = fork();
/* Le code à partir d'ici sera exécuté sur les deux processus */
printf("Après le fork() ... \n");
/* Sur le processus fils, i sera multiplié par 5 */
if(ret == 0) {
i*=5;
/* Sur le processus père, i sera additioné de 5 */
} else {
i+=5;
}
/* Le code ici sera exécuté sur les deux processus */
printf("La valeur de i est: %d\n", i);
/* On retourne la valeur de succès d'exécution ce qui va tuer les deux processus */
return EXIT_SUCCESS;
}
Va retourner :
Avant le fork() ...
Après le fork() ...
La valeur de i est: 10
Après le fork() ...
La valeur de i est: 25
Fin d'un processus
Un processus se termine quand il n'y a plus aucune instruction à
exécuter ou lorsque l'appel système exit(int) est appellé (cette
fonction permet de renvoyer une valeur entière au processus père).
wait et waidpid
Un processus père peut attendre la mort de son fils à l'aide des
fonctions wait() et waitpid() et peut ainsi récupérer l'entier
retourné par le exit(int) du fils.
La fonction wait() va simplement attendre la mort d'un fils (peu
importe lequel) tandis que la méthode waitpid() va attendre la mort
d'un processus fils déterminé.
Les fonctions wait et waitpid retourne le pid du fils, il faut donc
passer le pointeur d'une variable en argument pour récupérer les
valeurs. Voici un exemple :
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/wait.h>
#include <string.h>
int main(void) {
char chaine[100+1];
int compteur = 0;
pid_t pid_fils;
/* On crée un nouveau processus */
switch (fork()){
/* Si le résultat est -1 c'est qu'il y a eu un problème */
case -1:
printf("Le processus n'a pas été créé.");
exit(-1);
/* Si on est le processus fils, on demande d'entrer une chaine de caractères */
case 0:
printf("Entrez une chaine de caractères : ");
scanf("%100[^\n]%*c", chaine);
/* On retourne la longueur de la dite chaine en exit */
exit(strlen(chaine));
/* Si on est le processus père, on attends la mort du fils et on récupère la sortie du exit dans une variable */
default:
/* On stoque le retour du exit dans une variable ainsi que le PID du fils */
pid_fils = wait(&compteur);
/* On extrait la longueur de la chaine depuis la sortie du wait avec WEXITSTATUS */
printf("Enfant %d est mort. Compteur = %d", pid_fils, WEXITSTATUS(compteur));
}
return EXIT_SUCCESS;
}
execl
execl permet d'avoir de charger un autre dans le processus, une fois
cette fonction execl exécuté le code du processus remplacé est perdu.
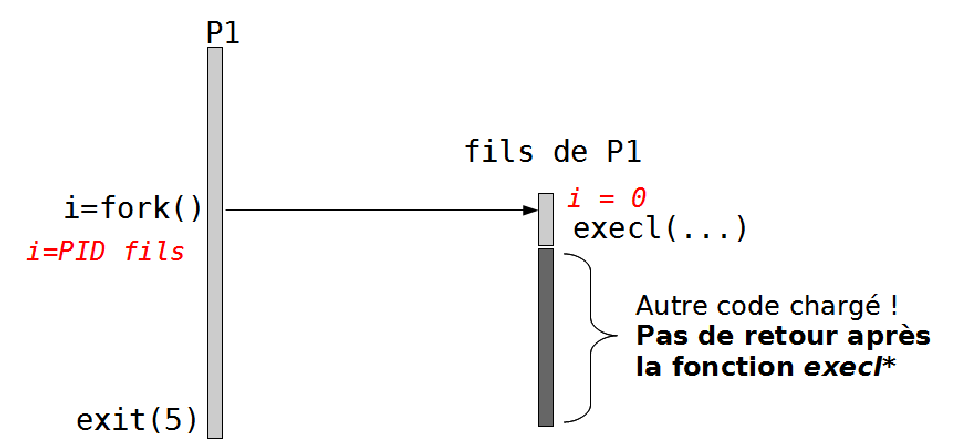
La fonction prends en paramètre, deux choses :
- Le chemin vers le programme
- Les arguments du programme ce qui commence par le chemin du programme (une deuxième fois) et qui termine par un NULL
Voici un exemple d'execl :
#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>
#include <stdlib.h>
#include <sys/wait.h>
int main(void) {
/* On crée un nouveau processus avec fork() */
switch(fork()) {
/* Si fork retourne -1 c'est qu'il y a eu un problème */
case -1: printf("Erreur fork()\n");
exit(-1);
/* Si fork retourne 0 c'est que c'est le processus fils, on va donc exécuter la commande ls avec execl */
case 0: printf("Je suis le fils\n");
/* Execl va lançer la commande "ls -l" */
/* Le premier paramètre est le chemin vers le programme */
/* Le deuxième paramètre est le chemin vers le programme qui va être passé en argument */
/* Le troisième paramètre est le flag "-l" qui sera passé en argument */
/* Le NULL termine la liste des arguments */
if(execl("/run/current-system/sw/bin/ls", "/run/current-system/sw/bin/ls", "-l", NULL)) {
/* Si le execl retourne -1, c'est qu'il y a eu une merde */
printf("Erreur execl()\n");
exit(-2);
}
printf("Ce code ne sera jamais exécuté car il est après le execl");
/* Pour le processus père, on va simplement attendre que le fils ai terminé */
default: wait(NULL);
printf("Mon fils a terminé\n");
}
return EXIT_SUCCESS;
/* Le switch n'a pas besoin de break car dans tous les cas, cela se fini par un exit, il ne peut donc rien y avoir après */
}
Choix des processus
Le scheduler du système d'exploitation doit sélectionner les processus à démarrer pour maximiser l'utilisation du CPU (généralement entre 40% et 90%) pour avoir un débit (le nmobre de processus terminés par unité de temps) important (si les processus sont trop long, le début sera faible).
Algorithmes
- FCFS (First-Come, First-Served), la file ici est une FIFO (first in, first out), c'est l'algorithme le plus simple à implémenter mais il peut être très long, car si le premier processus est long, il ralenti tous les processus qui suivent
- SJF (Shortest-Job First Scheduling), est une amélioration du précédent, il ordonne les processus selon leur durée, ainsi les processus les plus rapides viennent au début et les plus lents à la fin. Cet algorithme est seulement possible si on sait à l'avance la durée du processus, mais aujourd'hui c'est rarement le cas.
-
Priorité, on tient compte de la priorité d'un processus, ainsi les
processus avec la priorité la plus élevée (nombre le plus petit) sont
exécutés avant.
- Cet algorithme peut être préemptif ce qui signifie qu'un processus qui tourne (running) peut être mis sur pause (en état ready) si un processus de plus haute priorité arrivé.
- Cependant cela peut mener à de la famine car les si il y a
continuellement des processus de plus haute priorité qui arrive.
- Ce problème peut être résolu en combinant l'age et la priorité (ainsi les processus ayant attendu trop longtemps passe avant)
-
Round-Robin Scheduling (Tourniquet), les processus sont servi dans
l'ordre d'arrivée et chaque processus reçoit le CPU pour un temps
déterminé (appelé quantum), ainsi on va alterner entre chaque
processus avec un temps donné (c'est donc un algorithme préemptif)
- Si le quantum est trop grand, l'utilisateur·ice aura l'impression que le système lag car rien ne pourra être fait tant que le processus en cours est n'a pas fini son quantum
- Si le quantum est trop petit, alors on va perdre en efficacité du CPU car beaucoup de l'énergie de calcul sera mise dans le fait d'échanger tous les processus tout le temps.
- Multilevel Queue Scheduling, qui s'agit d'avoir de files différentes suivant la nature du processus, une priorité et un mécanisme de scheduling propre est attaché à chaque file, il est ainsi possible d'avoir FCFS et Round-Robin sur des files différentes.

-
Multilevel Feedback Queue Scheduling, les files sont plus
dynamique (un processus n'appartient pas à une file et migrent d'une
file à l'autre), chaque file a des caractéristiques précises (quantum,
algorithme scheduling, etc).
- Par exemple on peut dire qu'un processus va commencer dans une RR de quantum 8, si il n'a pas fini à la fin de son quantum il passe dans une autre file de priorité mois élevée avec un quantum de 16 et si il n'a toujours pas fini il passe dans une priorité encore mois élevée en FCFS.

Choix de l'algorithme
Il n'y a pas un seul bon algorithme car chaque algorithme sert à remplir un but précis.
On peut évaluer ces algorithmes selon une certaine utilisation en utilisant des modèles mathématiques, des simulations, des implémentations et des tests.
Quel algorithme utilisé dans l'OS ?
Sous Windows, c'est un système à 32 niveaux de priorités (préemptif).
Linux en revanche utilise un autre système de scheduling appelé CFS, vous pouvez en apprendre plus dans cette vidéo.
La communication IPC
Il est nécessaire que les processus communiquent entre-eux (pour le partage d'information, la répartition des calculs, la modularité et la facilité). La communication inter-process sont très courrant sous UNIX et servent à résoudre ce problème.
Différentes options
- Fichiers, cependant c'est très lent et difficile à synchroniser
- Tube nommé ou non-nommé
- Files de messages
- Mémoire partagée, qui a l'avantage d'être très rapide
- Socket (échanges via le réseau) qui est universel
Les tubes
Les tubes sont des petits fichiers géré en file circulaire, ils sont si petit qu'ils sont souvent en cache (ce qui est donc très efficace). Si le message devient trop grand, il sera alors découpé en blocs.
Tubes non-nommés
Les tubes non-nommés sont des tubes temporaires, ils sont alloué via
l'appel système pipe()
Il existe différents tubes standards :
-
stdintube de lecture (via le clavier, genrescanf) -
stdouttube de sortie (affichage à l'écran, genreprintf) -
stderrest un tube de sortie pour les messages d'erreurs
Il est ainsi possible de rediriger ces tubes.
Opérations
- Ecriture dans le tube avec appel système
write(int h, char* b, int s)(h étant le tube, s les premiers octets, et b le buffer) - Lecture dans le tube avec appel système
read(int h, char* b, int s) - Fermeture du tube via
close(int h)
Note les fonctions read et write retournent 0 si on tente d'écrire
ou de lire un tube sans qu'il n'y a pas de processus à l'autre bout du
tube.
Exemple
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/wait.h>
int main(void) {
int tube[2];
char buffer[255];
/* On crée le tube et on note les identifiant entrée et sortie dans le tableau */
pipe(tube);
/* On crée un nouveau processus */
switch(fork()) {
case -1:
printf("Erreur fork()\n");
exit(-1);
/* Pour le processus fils */
/* Le processus fils va lire le processus tube[0] pour avoir la lecture en écriture */
/* Le buffer va être la variable où les données vont être écrites */
/* Et enfin 's' est la taille que l'on va récupérer */
case 0:
/* Si le tube est vide, read va attendre que le tube soit rempli */
read(tube[0], buffer, 254);
printf("Message: %s\n", buffer);
break;
/* Pour le processus père : */
/* Ici on écrit "salut à toi" dans le tube en écriture (tube[1]), le buffer va donc contenir le message */
/* Le 's' va contenir la longueur du buffer */
/* Ainsi le message va être envoyé au fils */
default:
strncpy(buffer, "salut a toi", 12);
write(tube[1], buffer, strlen(buffer));
/* Ici on attends que le processus fils meurt, sinon le read du fils retournera 0 car il n'y aura plus le processus à l'autre bout car le programme sera terminé */
wait(NULL);
}
return EXIT_SUCCESS;
}
Redirections
Par défault les 3 tubes standard sont dirigé vers le stdout (ou stderr si configuré autremenet).
On peut également rediriger ces tubes, ainis ce qui était affiché à l'écran est alors dirigé automatiquement dans le tube ou peut être lu à partir d'un tube.
Utilisation en shell
# On liste les fichiers et on récupère toutes les lignes contenant "dia"
# grep prends comme entrée le résultat du ls
# C'est le shell qui va automatiquement rediriger le stdout du ls comme le stdin du grep
ls | grep "dia"
Fonctionnement
Voici un exemple de redirection :

Dans cet exemple :
- On crée un tube
- On ferme le stdout
- On copie notre sortie de tube comme étant le stdout
- On écrit dans le stdout → donc dans notre tube

Exemple en C
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/wait.h>
int main(void) {
int tube[2];
char buffer[255];
/* On crée notre nouveau tube */
pipe(tube);
switch(fork()) {
case -1:
printf("Erreur fork()\n");
exit(-1);
/* Pour le processus fils */
case 0:
/* On ferme le stdin */
close(0);
/* On copie l'entrée du nouveau tube pour remplacer le stdin */
dup(tube[0]);
/* On lit depuis le stdin (on lit donc depuis le tube) */
scanf("%[^\n]%*c", buffer);
/* On affiche le message stdout */
printf("Message: %s\n", buffer);
break;
/* Pour le processus père */
default:
/* On ferme le stdout */
close(1);
/* On copie la sortie du tube dans le stdout */
dup(tube[1]);
/* On print un message vers le stdout, qui a été redirigé vers le nouveau tube */
printf("salut a toi\n");
/* On force le printf a se faire maintenant */
fflush(stdout);
/* On attends que le processus fils meurre pour éviter de causer une erreur de lecture du tube */
wait(NULL);
}
return EXIT_SUCCESS;
}
Autre exemple (avec execl)
Lorsque l'on redirige un pipe, le pipe reste redirigé si on exécute un
autre programme par après avec execl, on peut donc passer l'output
d'un programme dans un autre programme. Voici un exemple de pipe qui
prends le résultat du ls et compte le nombre de lignes, c'est
l'équivalent de ls | wc -l. Notez cependant que les path de ls et wc
sont très certainement différent sur votre système, pour connaitre
le PATH réel faites la commande whereis ls et whereis wc.
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/wait.h>
#include <sys/types.h>
int main(void) {
int tube[2];
/* On crée un nouveau tube */
pipe(tube);
/* On crée un premier enfant */
if (fork() == 0) {
/* On ferme le stdout */
close(1);
/* On redirige la sortie du tube dans le stdout */
dup(tube[1]);
/* On ferme les tubes pour laisser uniquement le stdin et stdout */
close(tube[0]);
close(tube[1]);
/* On exécute le ls */
execl("/run/current-system/sw/bin/ls", "/run/current-system/sw/bin/ls", NULL);
/* Puis ce que rien n'arrive après un execl le reste du code ne s'exécutera pas */
}
/* On crée un deuxième enfant */
if (fork() == 0) {
/* On ferme le stdin */
close(0);
/* On remplace le stdin par le tube[0] */
dup(tube[0]);
/* On ferme les tubes pour laisser uniquement les stdin et stdout */
close(tube[0]);
close(tube[1]);
/* On exécute wc -l ça récupère le stdin du ls */
execl("/run/current-system/sw/bin/wc", "/run/current-system/sw/bin/wc", "-l", NULL);
}
/* On ferme le tube[0] et tube[1] pour laisser uniquement le stdin et stdout */
close(tube[0]);
close(tube[1]);
/* On attends la mort des fils pour mourrir aussi */
wait(NULL);
wait(NULL);
return EXIT_SUCCESS;
}
Tubes nommés
Les tubes nommés sont permanent via des fichiers spéciaux dans le filesystem.
On peut en créer un en utilisant mkfifo(const char* nom, mode_t mode)
(le nom préise le nom du tube et le mode précise les permissions).
Les processus non-només sont liés entre père et fils, tandis qu'ici les processus nommés peuvent être utilisé par des processus qui bien que sont complètement indépendant l'un de l'autre.
Un processus peut ouvrir un tube en utilisant
open(const char* nom, int flags) (qui est bloquant par défaut tant que
le tube n'est pas ouvert des deux cotés), les flags définissent le mode
d'ouverture (écriture, lecture ou les deux bien que cela ne soit pas
recommandé).
On peut écrire dans un pipe avec write(int fd, char* buf, int size) et
lire avec read(int fd, char* buf, int size)
On peut enfin fermer un tube avec close(int fd)
Mémoire partagée
La mémoire partagée est un moyen très commun pour partager des informations entre processus, la zone de mémoire est commune à plusieurs processus. La taille est complètement configurable (comme avec malloc) et après un fork, le processus fils hérite de la mémoire partagée.
Shmget - Allocation
L'allocation se fait via int shmget(key_t key, int s, int fl) où
- La clé est l'identifiant de la mémoire partagée
-
sest la taille en octets -
flest le flag de permission sur la zone
Petite note sur les permissions

Les permissions se font via un code tel que 0664 :
- Le premier
0indique que le nombre est en octal et non pas en décimal. Ainsi0644c'est110 110 100en binaire, et777est1 100 001 001en binaire. - Premier
6→ est le propriétaire signifie que le propriétaire peut lire et écrire(read (1) write (1) execute (0) = 110 = 6) - Deuxème
6→ est le groupe qui peut lire et écrire également (read (1) write (1) execute (0) = 110 = 6) - Enfin le
4→ les autres utilisateurs peuvent seulement lire (read (1) write (0) execute (0) = 100 = 4)
Shmat - Récupération de pointeur
L'appel shmat permet de récupérer un pointeur vers la zone mémoire
partagée. Sa signature de méthode est la suivante :
char* shmat(int shmid, char* addr, int flags) où
-
char*est le pointeur retourné -
int shmidest l'identifiant retourné par shmget -
char* addrest l'addresse souhaitée (généralement positionnée à 0 pour laisser le système choisir) -
int flagspour les paramètres de restriction (par exemple SHMRDONLY donne un pointeur en lecture seule)
Shmdt - Détacher la zone
L'appel shmdt (qui prends en argument le pointeur) va détacher la zone
mémoire sans pour autant la libérer.
Shmctl - Gérer la zone
L'appel int shmctl(int shmid, int cmd, struct shmid_ds* ds) permet de
gérer la zone de mémoire.
-
shmidest le descripteur de la zone retourné par shmget -
cmddétermine l'opération souhaitée (pour supprimer on utiliseIPC_RMIDmais il existe également IPCSTAT pour avoir des informations, IPCSET pour modifier les valeurs associées, etc) -
dscontient les données en rapport avec les commandes STAT et SET
Exemple
Disons que l'on veut faire 2 programme, 1 premier écrit dans la zone mémoire et le deuxième la lit :
- Premier programme :
#include <stdlib.h>
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/shm.h>
#include <string.h>
#define SHM_KEY 2324
#define K 1024
int main(void) {
int shmid;
char* ptr;
/* On alloue une zone de mémoire partagée avec l'identifiant 2324, une taille de 1024 octets, et une permission totale pour tout le monde */
shmid = shmget(SHM_KEY, K, 0777|IPC_CREAT);
/* Récupère un pointeur vers la zone de mémoire partagée */
ptr = shmat(shmid,NULL,0);
/* On copie une chaine de caractère dans la mémoire partagée */
strcpy(ptr, "Hello !\n");
/* On détache la zone mémoire (ce qui ne la libère pas mais permet qu'un autre processus l'utilise) */
shmdt(ptr);
/* On ferme le programme */
return EXIT_SUCCESS;
}
- Deuxième programme :
#include <sys/ipc.h>
#include <sys/shm.h>
#include <sys/types.h>
#include <string.h>
#include <stdlib.h>
#include <sys/msg.h>
#include <stdio.h>
#define SHM_KEY 2324
#define K 1024
int main(void) {
int shmid;
char *ptr;
/* On récupère la zone mémoire avec l'identifiant, la taille et le flag */
shmid = shmget(SHM_KEY, K, 0777);
/* Si le shmid retourné est < 0 alors c'est que la zone n'a pas été trouvée */
if (shmid < 0) {
printf("Erreur SHM\n");
exit(-1);
}
/* On récupère le pointeur de la mémoire partagée */
ptr = shmat(shmid, NULL, 0);
/* On print le contenu de la mémoire partagée */
printf("sa %d", IPC_CREAT);
printf("Contenu : %s\n", ptr);
/* On détache la mémoire du programme */
shmdt(ptr);
/* Le shmctl IPC_RMID va détruire la zone mémoire */
shmctl(shmid, IPC_RMID, NULL);
return EXIT_SUCCESS;
}
Commande ipcs pour lister les mémoires partagées
Si vous souhaitez voir la liste des zones partagées on peut utiliser la
commande ipcs.
[snowcode@snowcode:~]$ gcc mempar.c
[snowcode@snowcode:~]$ ./a.out
[snowcode@snowcode:~]$ ipcs
------ Message Queues --------
key msqid owner perms used-bytes messages
------ Shared Memory Segments --------
key shmid owner perms bytes nattch status
0x00000914 4 snowcode 777 1024 0
------ Semaphore Arrays --------
key semid owner perms nsems
Synchronisation
Lorsque plusieurs processus coopèrent, ils doivent souvent intéragir entre eux, ils doivent parfois attendre qu'une opération soit effectuée par un autre processus pour travailler.
Il faut donc avoir des mécanismes qui permettent d'envoyer des événements aux processus (un processus doit pouvoir attendre l'évènement).
Types de synchronisation
Sous UNIX, les mécanismes suivants sont mis en oeuvre pour la synchronisation :
- Les signaux
- Les sémaphores
On parlera de point de synchronisation lorsqu'un processus attend un autre.
Les signaux
Un signal est un événement capturé par un processus, c'est aussi un mécanisme simple utilisé par le système d'exploitation pour signaler aux processus une erreur (SIGILL, SIGFPE, SIGUSR1, SIGUSR2, etc).
Exemple
Voici par exemple un programme dont la fonction sighandler est
appellée lorsque le signal SIGUSR1 est déclenché :
#include <stdio.h>
#include <signal.h>
#include <unistd.h>
#include <stdlib.h>
void sighandler(int signum);
/*
Ce programme va lier la fonction sighandler au signal SIGUSR1
Ce qui signifie que lorsque l'on lance le programme (qui contient une boucle infinie), lorsque l'on lance le signal via "pkill -SIGUSR1 a.out" (par exemple)
La fonction sighandler va être appellée et "SIGUSR1 reçu" va donc s'afficher à l'écran.
*/
int main(void) {
/* Si on remplace ici SIGUSR1 par SIGINT et que l'on fait CTRL+C, on va appeller la commande sighandler */
if(signal(SIGUSR1, sighandler) == SIG_ERR) {
printf("Erreur sur la gestion du signal\n");
exit(-1);
}
while(1) {
sleep(1);
printf("Hello\n");
}
return EXIT_SUCCESS;
}
void sighandler(int signum) {
printf("SIGUSR1 reçu\n");
}
Opérations
Il existe plusieurs opérations différentes sur les signaux :
-
signaletsigsetqui lient un signal à une fonction.signalla lie une seule fois, tandis quesigsetla lie continuellement. -
alarmdéclenche le signal SIGALARM au processus courrant. -
pausesuspend le processus jusqu'a la réception d'un signal -
killenvoie un certain signal au processus dont le PID est donné.
Les sémaphores
Un sémaphore est une variable entière en mémoire qui excepté pour son
initialisation est accédée uniquement au moyen de fonction atomiques
(ne pouvant pas être décomposée) p() et v().
La fonction p(sem) va vérifier que la valeur est plus grande que zero,
si c'est le cas, la variable est décrementée et l'exécution continue, si
ce n'est pas le cas, alors il attend que ce soit le cas.
La fonction v(sem) va simplement incrémenter la variable de 1, et va
ainsi réveiller tous les processus qui attendrait ce sémaphore.
Ces foncitons ne sont pas présente dans C de base il faut importer les
fichiers semadd.h et semadd.c depuis l'espace de cours.

Exemple
Voici un exemple d'un programme qui communique avec un processus fils
via 2 sémaphores. Il est intéressant de noter que généralement un
processus ne va faire qu'une seule opération par sémaphore (par exemple
que des p() sur sem1 et que des v() sur sem2 ou inversément)
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
#include "semadd.h"
#define SEM1 12345
#define SEM2 23456
/*
Ce programme va créer 2 sémaphores et 2 processus (un père et un fils).
Le fils et le père vont tous les deux exécuter une boucle sauf qu'a chaque itération ils vont s'attendre l'un l'autre.
Ainsi le père attends le sémaphore du fils (sem2) qui est émit lorsque le fils a fini son itération
De même le fils va ensuite attendre le sémaphore du père (sem1) qui est émit lorsque le père a fini son itération
Si on exécute ipcs -s lors de l'exécution du programme, on peut voir la liste des sémaphores créés.
Contrairement aux signaux, on peut créer nos propres sémaphores tandis que les signaux eux sont défini par le système d'exploitation.
*/
int main(void) {
int sem1, sem2, i;
/* Création des sémaphores */
sem1=sem_transf(SEM1);
sem2=sem_transf(SEM2);
/* Création des deux processus */
switch(fork()) {
case -1:
printf("Erreur fork()\n");
exit(-1);
/* Boucle du fils */
case 0:
printf("Je suis le fils %d\n", getpid());
for(i=0;i<5;++i) {
printf("[FILS] Valeur de i : %d\n",i);
sleep(5);
v(sem2); /* Envois du sémaphore (2) au père */
p(sem1); /* Attente du sémaphore (1) du père */
}
/* Boucle du père */
default:
for(i=0;i<5;++i) {
p(sem2); /* Attente du sémaphore (2) du fils */
printf("[PERE] Je suis le père\n");
sleep(5);
v(sem1); /* Envois du sémaphore (1) au fils */
}
}
return EXIT_SUCCESS;
}
Semget - Allocation de sémaphores
L'allocation se fait via int semget(int key, int nb, int flag), où
- La valeur retournée est un descripteur "semid"
- La clé est la valuer qui identifie le sémaphore
- Les flags définissent les permissions, comme pour les mémoires
partagées
IPC_CREATpermet de demander la création des sémaphores
On peut aussi simplifier l'allocation à partir d'une clé en utilisant
int sem_transf(int key), cette fonction n'est pas officielle mais
le fichier est disponible sur HELMo Learn.
Semctl - Gestion de sémaphores
On peut gérer les sémaphores (nottament pour libérer la mémoire) en
utilisant int semctl(int semid, int semnum, int cmd, union semun attr)
où
- semid est le descripteur du sémaphore
- semnum identifie le sémaphore (généralement c'est 0 si il n'y en a qu'un)
- cmd identifie la commande (IPCSET, GETVAL, SETVAL, IPCRMID ou IPCSTAT).
-
union semun attrest une "union" (un type de structure où chaqun des éléments partagent la même zone mémoire, ainsi ce ne peut être qu'un seul élément à la fois, un peu comme une enum en Rust). Il faut généralement définir cette structure soi-même en revanche.
Semop - Faire les opérations sur les sémaphores
int semop(int semid, struct sembuf* sops, unsigned nsops) est la
fonction qui est derrière les fonctions p() et v().
- semid est le descripteur du sémaphore
- sops est un tableau de structures semfus (contenant l'opération)
- nsops est le nombre d'éléménts du tableau sops
Sections critiques
C'est bien beau la synchronisation sauf que la coopération entre plusieurs processus pose également des problème si deux processus concurrents souhaite modifier les même données au même moment.
Définition section critique
On peut donc mettre en place une section critique, c'est un ensemble d'instructions qui devraient être exécutées du début à la fin sans interruption.
Une section critique est indispensable lorsque l'on traite des données partagée afin qu'elle soit protégée et que ces données partagées ne deviennent pas incohérente.
Par exemple, si on fait par exemple une liste chainée, elle risque de ne plus être cohérente après plusieurs modifications.
On ne peut cependant pas empêcher la concurrence entre les processus. Pour cela on va mettre en place des protections avant toute modification pour s'assurer qu'un autre processus n'est pas déjà en train de modifier la zone partagée.
Variable partagée
Celle ci consiste à partager une variable entre plusieurs processus, qui est initiallement définie à 0. Avant d'entrer dans le processus, on boucle sur la valeur de cette variable.
Si la variable est différente de 0 on boucle (et on attends). Ensuite on place la variable à 1 avant de commencer la section critique puis on la remet à 0 une fois que cela est fini.
while (i != 0);
i = 1;
/* Section critique ici */
i = 0;
Problème
Un gros problème peut survenir si un processus reviens dans l'état ready
(par exemple avec la fin de son quantum de temps) entre l'instruction
while et l'instruction de i = 1.
Ainsi l'autre processus peut lui aussi entrer en section critique et peut lui aussi avoir son quantum de temps qui expire durant celui ci.
Ainsi on peut donc arriver dans une situation ou plusieurs processus sont dans une section critique en même temps (ce qui est justement la chose à éviter).
Ainsi, cette méthode de protection n'est pas fiable.
En plus de cela, utiliser une boucle while comme ceci consomme inutilement du CPU.
Pour plus d'infomration voir la vidéo de la séance 3 du cours d'OS 2020 à 2:25:50.
Par alternance
La protection par alternance consiste de manière similaire à la méthode précédente à avoir une variable partagée mais ou chaque processus attends une valeur différente.
Ainsi, par exemple un programme 1 pourrait avoir le code suivant :
while (tour != 0);
/* Section critique ici */
tour = 1;
Et un programme 2 pourrait avoir le code suivant :
while (tour != 1);
/* Section critique ici */
tour = 0;
Ainsi lorsque tour est à 0, le programme 1 peut exécuter sa section critique, une fois qu'elle a fini le programme 2 peut exécuter la sienne, et une fois que le progrmame 2 à fini, le programme 1 peut recommencer.
Problèmes
Cette méthode de protection est fiable, contrairement à la précédente. Cependant elle souffre tout de même d'assez gros problèmes…
Premièrement, elle est assez difficile à gérer, surtout si il y a plus de deux processus à synchroniser.
Et deuximèment, comme la précédente, elle est assez peu efficace car utiliser une boucle while ainsi consomme inutilement du CPU.
Pour plus d'infomration voir la vidéo de la séance 3 du cours d'OS 2020 à 2:33:20.
Par fichier
La protection par fichier consiste à ouvrir et créer un fichier (appellé "lock file") en mode exclusif (c'est à dire qu'un seul processus peut accéder au fichier à la fois) pour annoncer que la section critique commence.
Puis enfin à supprimer le fichier une fois que la section critique est terminée.
#include <fcntl.h>
#include <unistd.h>
#include <stdio.h>
#include <stdlib.h>
#define FIN_SECTION_CRITIQUE 1
#define DEBUT_SECTION_CRITIQUE -1
int quid(int op, char* nom, int essais) {
int i;
/*
* Quand on débute la section critique, on crée un fichier dit "lock file" en mode exclusif,
* si cela n'est pas possible c'est qu'une section critique est déjà en cours
*/
if(op == DEBUT_SECTION_CRITIQUE) {
for(i=0;i<essais;++i) {
/* Tenter d'écrire un fichier en mode exclusif (un seul processus a accès au fichier à la fois) et renvoyer 0 en cas de succès */
if(open(nom,O_WRONLY|O_CREAT|O_EXCL) >=0) {
return 0;
}
/* Si cela n'a pas fonctionné, réessayer dans une seconde */
else if(i<essais) {
sleep(1);
}
}
}
/*
* A la fin d'une section critique on supprime le lock file
*/
if(op == FIN_SECTION_CRITIQUE) {
/* Suppression du fichier et retourne 0 en cas de succès */
if(unlink(nom) == 0) {
return 0;
}
}
/* Retourne -1 en cas d'erreur ou dans le cas où tous les essais ont échoués */
return -1;
}
int main(void) {
printf("Attente section critique\n");
quid(DEBUT_SECTION_CRITIQUE, "program.lock", 5);
/* Section critique ici */
printf("Début section critique\n");
sleep(5);
printf("Fin section critique\n");
quid(FIN_SECTION_CRITIQUE, "program.lock", 5);
return EXIT_SUCCESS;
}
Problèmes
Cette solution est tout à fait fonctionnelle et fiable, cependant le fait de devoir gérer un fichier peut rendre les choses un peu compliquée, de plus cela ralenti les choses. Car pour chaque accès au fichier, le processus devra passer en état waiting, puis ready, puis de nouveau running.
Pour plus d'infomration voir la vidéo de la séance 3 du cours d'OS 2020 à 2:37:50.
Synchronisation hardware
La synchronisation hardware consiste à utiliser des instructions assembleurs pour protéger une section critique.
Voici un pseudo-code de démonstration :
boolean TestAndSet (boolean target) {
/* On copie la valeur de target */
boolean rv = target;
/* On met target à true */
target = true;
/* On retourne la copie de la valeur initiale */
return rv;
}
Ainsi pour l'utiliser il suffirait de faire ceci :
/* On attends que le lock (variable partagée initialement à false) soit mis à false pour continuer */
while (TestAndSet(lock));
/* Section critique ici */
/* On met le lock à false une fois terminé */
lock = false;
Ainsi lorsque lock est à false, TestAndSet va la mettre à true et retourner false ce qui va donc faire passer la boucle et entrer en section critique. Une fois cette dernière terminée, le lock retourne à false.
En revanche si lock est à true, TestAndSet va retourner true et par conséquent rester dans le while, en attente jusqu'a ce que la variable soit à false.
Problèmes
Cette méthode est fiable mais le problème avec celle ci c'est
l'utilisation du while qui va une fois de plus consomer du CPU pour
simplement attendre.
Il est toute fois bon de noter que cette méthode est utilisée par le système d'exploitation pour gérer d'autes systèmes de protection tel que les sémaphores.
Pour plus d'infomration voir la vidéo de la séance 3 du cours d'OS 2020 à 2:47:00.
Sémaphore
Les sémaphores permettent de très simplement protéger une section critique, voici un exemple :
#include "semadd.h"
#include "sys/sem.h"
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
#include <sys/wait.h>
#define KEY_SEM1 12345
#define KEY_SEM2 12346
int main(void) {
int sem1, sem2;
/* On crée 2 sémaphores */
sem1 = sem_transf(KEY_SEM1);
sem2 = sem_transf(KEY_SEM2);
/* On crée un nouveau processus */
switch (fork()) {
case -1:
printf("Quelque chose s'est mal passé lors de la création du processus...\n");
return EXIT_FAILURE;
/* Pour le fils */
case 0:
/* Attente du père */
printf("En attente du père\n");
p(sem1);
/* Section critique */
printf("Section critique du fils commence\n");
sleep(3);
/* Annonce au père qu'il a fini */
printf("Section critique du fils se termine\n");
v(sem2);
break;
/* Pour le père */
default:
/* Section critique */
printf("Début de la section critique du père\n");
sleep(3);
/* Annonce au fils qu'il a fini */
printf("Fin de la section critique du père\n");
v(sem1);
/* Attends le fils avant de supprimer les sémaphores */
p(sem2);
semctl(sem1, IPC_RMID, 0);
semctl(sem2, IPC_RMID, 0);
}
return EXIT_SUCCESS;
}
Comme vu précédemment, les p et v des sémaphores sont des actions unitaires, il n'y a donc pas de risque que le processus soit arreter au millieu. L'utilisation des sémaphores est la manière recommandée de gérer des sections critiques.
Pour plus d'infomration voir la vidéo de la séance 3 du cours d'OS 2020 à 2:52:00.
Les threads
Les processus que l'on a vu n'avait qu'un seul fil d'exécution (monothread) mais il est possible d'avoir un processus avec plusieurs fils d'exécutions (multithread).
Les threads sont en somme des sortes de "mini processus".
Avantages
Contrairement aux processus il est beaucoup plus rapide d'en créer un nouveau, également les threads d'un même processus partagent les informations. En plus sur un système avec plusieurs coeurs l'exécution des threads d'un même processus peut se faire en parallèle ce qui offre une performance intéressante.

Exemple
Par exemple on pourrait avoir un thread utilisé pour une saisie de texte, un autre thread pour l'affichage et encore un dernier thread pour vérifier les informations reçues.
Modèles d'implémentations
Les threads peuvent être implémentés à deux niveaux :
- Dans l'espace kernel, il est alors pris en charge nativement par le système d'exploitation au même titre que les processus
- Dans l'espace utilisateur, il est alors supporté au travers de libraries externe
Les threads peuvent être implémentés selon plusiuers modèles :
Plusieurs à un

Dans ce modèle les threads sont supporté par une librarie externe, le système d'exploitation n'en a donc aucune connaissance et ne vois que le processus.
L'avantage est que sa création est rapide, cependant les inconvénients sont que un seul thread (le processus) est vu par le système, le scheduler du système n'est donc pas adapté. Si un thread réalse une opération bloquante, cela risque d'empécher tous les autres threads de travailler.
Enfin cette implémentation n'est plus vraiment courrante car elle n'est pas adaptées aux CPU multi-coeurs.
Un à un

Dans ce modèle chaque thread utilisateur est attaché à un thread kernel. Ainsi les threads sont complètement géré au niveau du système d'exploitation.
Cela a l'avantage de créer un scheduling plus avantageux et d'être compatible avec les processeurs multi-coeurs.
Cependant ce modèle est couteux pour le système car c'est lui qui doit tout gérer.
C'est ce modèle qui est nottament utilisé dans Linux. Voici par exemple la liste des threads associés au processus Firefox sur mon système.

Plusieurs à plusieurs

L'idée du plusieurs à plusieurs est de créer un pool de thread au quel les threads utilisateurs vont être assigné à la volée au cours de l'exécution.
De cette façon cela combine les avantages des deux modèles précédents. Cependant ce modèle est assez peu courrant car il nécessite que le sysètme d'exploitation soit construit autour de ce modèle car il est plus complexe à gérer que les autres.
Problèmes
Il y a quelques difficultés à considérer pour les threads. Par exemple :
- Que se passe-t-il en cas de
fork()dans un thread ? Certains OS vont dupliquer tous les threads, d'autres ne vont pas le faire. - Et avec
execl()? L'appel execl remplace le code du processus pour charger celui d'un autre. Ainsi le code remplace tous les threads du processus - Pour terminer l'exécution d'un thread il y a deux possibilités, dans
tous les cas il faut faire très attention pour la libération des
ressources
- Le faire de manière asynchrone, un thread demande la terminaison d'un autre (cela est cependant rare)
- Le faire de manière différée, chaque thread vérifie régulièrement s'il doit continuer ou s'arrêter
- Quand un signal est envoyé à un processus, quels threads recoivent le signal ? Tous, certains ou un en particulier ? Cela dépends du type de signal et cela est encore une fois pas comment dans tous les OS.
Librarie
Pour créer des threads dans les systèmes UNIX il existe la librarie
standard pthread dont voici quelques fonctions intéressantes :
-
pthread_attr_initqui permet de fixer certains attributs, mais pas utile dans le cours -
pthread_createpour créer et démarrer un nouveau thread -
pthread_joinpour attendre la mort d'un thread -
pthread_exitpour terminer l'exécution d'un thread, cette fonction permet aussi de retourner une valeur de retour à pthread join via un pointeur génériquevoid*
Exemple
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
void* thread1(void* args) {
int i;
/* On trasforme le void* args en pointeur de int avec un cast */
int* resultat;
resultat = (int*)args;
for (i = 0; i < 10; i++) {
printf("[THREAD 1] %d\n", i);
/* On ajoute le nombre courrant au résultat, attention à ne pas oublier de déréferencer le pointeur */
*resultat += i;
}
return resultat;
}
void* thread2(void* args) {
int i;
/* On trasforme le void* args en pointeur de int avec un cast */
int* resultat;
resultat = (int*)args;
for (i = 0; i < 24; i++) {
printf("[THREAD 2] %d\n", i);
/* On ajoute le nombre courrant au résultat, attention à ne pas oublier de déréferencer le pointeur */
*resultat += i;
}
return resultat;
}
int main(void) {
pthread_t tid1, tid2;
/* On initialise les résultats à 0 */
int resultat1 = 0;
int resultat2 = 0;
/* Création des threads auquels on passe les pointeurs vers les variables resultat1 et resultat2 */
pthread_create(&tid1, NULL, *thread1, &resultat1);
pthread_create(&tid2, NULL, *thread2, &resultat2);
/* On attends que tous les tests se finissent */
/* Nous n'avons pas besoin ici de récupérer la valeur de retour car on a toujours accès aux variables dont on a passé les pointeurs plus tôt, surtout que cela rends les choses très compliquées de manipuler des void** (pointeur de pointeur de valeur de type inconnue) */
pthread_join(tid1, NULL);
pthread_join(tid2, NULL);
/* Nous pouvons ensuite simplement récupérer les valeurs des résultats */
printf("Résultat du thread 1 = %d\n", resultat1);
printf("Résultat du thread 2 = %d\n", resultat2);
return EXIT_SUCCESS;
}
Les interblocages
Les ressources (la mémoire, CPU, périphériques, etc) sont limitées, il faut donc gérer les ressources de manière efficace pour permettre au plus grand nombre de processus de s'exécuter.
Un interblocage peut survenir si un processus détient une ressource A qui est demandée par un autre processus détenant une ressource B qui est elle-même demandée par le premier processus.
Conditions d'un interblocage
Un interblocage survient lorsque ces 4 conditions sont réunies simultanément :
- L'exclusion mutuelle, c'est lorsque les processus utilisent des ressources qui ne peuvent pas être partagées.
- La détention et l'attente, les processus doivent à la fois détenir une ressource et attendre une autre ressource.
- L'impossibilité de réquisitionner une ressource, car c'est dégueulasse et que l'on ne peut pas savoir l'état de la ressource.
- L'attente circulaire, voir plus bas

Empécher un interblocage
Pour empécher un interblocage il faut empécher l'une des conditions d'arriver.
- L'exclusion mutuelle ? on ne peux pas empécher un processus de détenir des ressources non partageable
- La détetention et l'attente ? Il y a deux solutions pour faire en
sorte que la détention et l'attente n'arrive pas en même temps :
- Un processus pourrait demander toutes les ressources dont il pourrait avoir besoin dès le départ de son exécution
- Lorsqu'un processus demande une nouvelle ressource, il doit libérer toutes les autres puis récupérer toutes ces ressources, plus la ressource demandée. Ce qui signifie que le processus accumule toujours plus de ressources ce qui peut créer une famine parmis les autres.
- Impossibiilité de réquisitionner une ressource ? Il n'est pas possible de s'assurer que les ressources seront dans un bon état lorsqu'elle sont réquisitionnées
- L'attente circulaire ? On peut essayer de détecter un cycle et si un cycle arrive, on peut par exemple numéroté chaque ressource et imposer aux ressources de demander les ressrouces dans l'ordre croissant de leur numéro.
Eviter l'attente circulaire
Pour éviter l'attente circulaire il faut donc savoir la quantité de ressources disponibles et occupées ainsi que les besoins de chaque processus.
Le système est dit en état sûr s'il est capable de satisfaire tous les processus. Et tant que le système évolue d'état sûr en état sûr, aucun interblocage ne peut survenir. Ce pendant un état non sûr ne conduit pas nécessairement à un interblocage.
Algorithme du banquier
Compléter les informations que l'on a
Au total pour pouvoir appliquer l'algorithme du banquier il nous faut :
- La matrice des ressources existantes (E)
- La matrice des besoins des processus (B)
- La matrice des allocations courrantes (C)
- La matrice des ressources disponibles (A), qui correspond aux ressources existantes - les allocations courrantes (E-C)
- La matrice des demandes des processus (R), qui correspond aux besoins des processus - les allocations courrantes (B-C)
Les matrices que l'on va vraiment utiliser pour l'algorithmes sont celles des allocations courrantes (C), des demandes (R) et des ressources disponibles (A).
Vérfier si le système est dans un état sûr
- Pour chaque processus on va regarder si on peut remplir sa demande (R)
à partir des ressources disponibles (A).
- Si c'est possible, alors on marque le processus comme terminé et on ajoute aux resources disponibles (A) toutes les allocations du processus terminé (C).
- On fait cela en boucle jusqu'a arriver à un résultat où tous les processus (C) sont terminés. Si à la fin tous les processus ne sont pas terminé, alors l'état n'est pas sûr.
Pour allouer depuis un état sûr
- Pour un processus qui demande une ressource, on va hypothétiquement
diminuer les ressources disponible de la demande, on va augmenter ses
ressources allouées et diminuer ses besoins. C'est à dire que l'on va
faire :
- ressources disponibles -= demande
- besoins -= demande
- ressources allouées += demande
- On va ensuite effectuer l'algorithme précédent pour vérifier si ce système hypothétique est en état sûr, si c'est le cas, alors on peut allouer, sinon il faut attendre
Détecter un interblocage
Le problème avec la première solution est que l'on ne sait pas en avance ce dont les processus ont besoins. Et il est plus efficace de simplement détecter et corriger un interblocage que d'empécher un interblocage car les interblocages restent peu fréquent.
Cet algorithme de détection et de correction va se lancer lorsque le CPU n'est plus utilisé, ce qui signifie que les processus sont en état "waiting".
Détection d'un cycle d'attente dans l'allocation
Pour détecter un interblocage il suffit de simplement connaitre les ressources disponibles, les allocations courrantes et les demandes actuelles.
Pour chaque processus en cours on va vérifer si ses demandes actuelles peuvent être satisfaite avec les ressources disponibles. Pour chaque processus trouvé, on va incrémenter les ressources disponibles des allocations courrantes et on va définir le processus comme terminé.
Si à la fin il reste des demandes non satisfaite, il y a un interblocage.
Correction d'un interblocage
Pour corriger un interblocage on va tuer un processus qui pose problème et tenter de maintenir les ressources dans un état cohérent.
On peut donc faire un rollback vers le contexte où le système était avant pour s'assurer que les ressources ne sont pas dans un état dégueulasse, du moins si on sauvegarde le contexte du processus régulièrement.
La politique de l'autruche
Sur certains systèmes (tel que les systèmes UNIX), c'est à l'administrateur·ice de s'occuper de gérer un interblocage et le système d'exploitation s'en fout.
La mémoire
Introduction
La mémoire a toujours été une ressource indispensable d'un système. Elle est partagée entre tous les processus. La mémoire est une suite non structurée d'octets, le système d'exploitation ne connait donc pas la structure des informations en mémoire (qui dépendent de chaque processus).
Importance de la mémoire
Les instructions d'un programme peuvent contenir des adresses mémoires en argument, il est ainsi nécessaire qu'un processus se trouve entièrement en mémoire pour pouvoir s'exécuter. Une gestion efficace de cette mémoire est alors primordiale.
Types de mémoires
Registres
Les registres sont des zones mémoires attachées au processus, leur taille est généralement très réduite (de l'ordre de quelques Ko) mais sont extrêmement rapides, pouvant généralement être accédé en un seul cycle d'horloge du processeur.
Mémoire vive (RAM)
La mémoire vive est la mémoire principale du système. Elle est la ressource importante à gérer et est souvent présente en quantité (entre deux et 64 Go). Elle est standardisée aux normes DDR3 et DDR4. Elle est plus lente par rapport au CPU (il faut parfois plusieurs cycles d'horloge pour récupérer une information), le CPU doit donc attendre ou mettre la donnée en cache. Cependant, cette ressource reste beaucoup plus rapide qu'un disque (SSD ou HDD).
Mémoire cache
La mémoire cache a pour but d'améliorer les performances générales du système en planquant en mémoire plus rapide les données fréquemment demandées.
Il existe trois niveaux de mémoire cache, le premier niveau sert à stocker temporairement des instructions et données. Les deux autres niveaux sont présents entre la mémoire RAM et la mémoire cache de premier niveau.
Mémoire virtuelle
La mémoire virtuelle est une mémoire simulée par le système. Elle utilise le disque dur comme RAM additionnelle. Elle est seulement limitée par la taille du disque dur, mais elle est très lente.
Isolation de la mémoire
Il est essentiel que chaque processus ait une zone mémoire réservée pour éviter des problèmes de sécurité et d'intégrité des données.
Un processus ne peut donc pas écrire dans l'espace mémoire d'un autre. S'il essaye, on aura une "Segmentation Fault". La mémoire n'est de ce fait pas partagée entre les processus sauf lorsque cela est explicitement demandé. (Voir Mémoire partagée pour plus d'informations).
Translation d'adresse
Lorsqu'un programme est chargé, il est placé entièrement en mémoire à une adresse de départ. Son espace d'adressage est défini et les instructions du programme font référence à l'adresse 0.
La translation peut être effectuée à 3 moments :
- À la compilation (inexistant aujourd'hui), on met les adresses physiques dans le programme compilé ;
– Au chargement (l'adresse de départ est choisie lors du chargement du processus par le système d'exploitation) ;
- A l'exécution, lors de l'exécution des instructions, cela demande un hardware précis et est utilisé par la segmentation.
Types d'adresses
On parle d'adresse logique pour parler de l'adresse présente dans les programmes (qui se réfèrent à l'adresse 0).
On parle en revanche d'adresse physique pour parler d'une case mémoire adressable de la mémoire RAM.
La conversion entre l'adresse logique et l'adresse physique est faite par le Memory Management Unit (MMU) qui est un composant matériel spécialisé dans l'opération de translation.

Allocation
Le système d'exploitation, les processus systèmes et utilisateurs se trouvent dans la mémoire, il faut donc un mécanisme de protection pour isoler les processus. Ce mécanisme, c'est le MMU vu plus tôt.
Mono-programmation
Lorsqu'un seul processus s'exécute à la fois en même temps que le système d'exploitation, c'est le cas sur les systèmes très rudimentaires comme MS-DOS.
Étant donné qu'il n'y a qu'un seul processus à la fois, le système d'exploitation n'a pas beaucoup à faire, car il n'y a pas besoin d'isoler la mémoire (sauf pour la petite partie réservée au système d'exploitation).
Le BIOS réalise une gestion des périphériques.
Multi-programmation
Partitions fixes
On peut pré-découper la mémoire en morceaux de taille variable (les partitions). On va donc tenter de placer chaque processus dans la plus petite partition qui peut la contenir.
L'un des problèmes de ce système est qu'il va y avoir beaucoup de restes (fragmentation interne) car si un a besoin de quatre unités, mais que la seule partition que l'on peut prendre en contient 8, on a quatre unités non utilisées.
Partitions variables
On alloue l'espace selon les besoins des processus, on va créer des partitions en fonction des demandes faites par les processus.
Table de bits

La table de bits correspond à une cartographie de la mémoire découpe en blocs d'allocations de taille fixe. Pour chaque bloc, on va noter un 1 si c'est occupé, ou un 0 si le bloc est libre dans la table de bits.
Ainsi, il suffit de seulement stocker 1 bit par unité d'allocation. Cependant, le problème est que si les unités d'allocations sont petites, alors il la table sera grande, mais ce sera plus précis.
À l'inverse, si les unités d'allocations sont grandes, la table sera plus petite, mais sera moins précise (ce qui implique donc un plus grand gaspillage de mémoire).
Un autre problème est que plus la taille est grande, moins l'allocation sera rapide, car il faudra parcourir toute la table jusqu'à trouver le segment d'unités libre recherché.
Liste chainée

Une autre méthode correspond à conserver une liste chainée des partitions mémoire. Cette liste est généralement triée suivant les adresses des partitions libres, ainsi les partitions qui se suivent dans la mémoire se suivront dans la liste.
Chaque élément de la liste chainée n'a alors qu'à stocker quatre
informations : si le bloc est libre ou pas, la position du début de la
partition, la longueur de la partition et le lien avec la partition
suivante. Par exemple P86 signifie qu'il y a un processus sur la
partition en position huit d'une longueur de six unités.
Ce qui implique également de facilité la fusion de blocs libre, si un programme libère une partition, cette partition pourra être facilement fusionnée avec les éventuelles partitions libres adjacentes pour former une partition plus grande.
L'avantage est de rendre l'allocation beaucoup plus rapide, le désavantage est que cela crée de la fragmentation.
Pour en savoir plus, vous pouvez regarder sur ce site.
Choix de la partition
Lorsque l'on recherche la partition de mémoire qui pourra accueillir un programme, il y a plusieurs algorithmes possibles.
- L'algorithme first-fit qui correspond à prendre la première partition libre trouvée étant suffisamment grande pour contenir le programme. C'est souvent cet algorithme qui est utilisé, car il est très rapide.
- L'algorithme best-fit qui correspond à parcourir toute la mémoire à la recherche de la meilleure partition. Cependant, cette méthode est assez peu efficace et crée beaucoup de fragmentation externe en créant des bouts de partitions trop petites pour être utilisées
- L'algorithme worst-fit qui correspond à de nouveau parcourir toute la mémoire, mais cette fois-ci à la recherche de la plus grande zone disponible afin d'éviter de créer trop de fragmentation externe comme le best-fit. Cet algorithme est particulièrement rapide pour les listes triées par taille.
Fragmentations
- La fragmentation interne survient lorsque la mémoire est divisée en unité d'allocation de taille fixe. Elle provient de la mémoire allouée par le SE, mais pas demandée au processus. Le SE alloue donc un surplus de mémoire par rapport à la demande du processus.
- La fragmentation externe survient suite aux allocations et libérations successives, la mémoire ressemble alors à un gruyère.
Solutions à la fragmentation
Pour rassembler les zones mémoires et résoudre ce problème de fragmentation, on peut utiliser le compactage. Cela consiste à rassembler les zones mémoires occupées et les zones libres ensembles de façon à créer de grands espaces libres.
Cela est cependant uniquement possible dans le cas de la translation à l'exécution et c'est un mécanisme assez couteux en ressource.
Une autre solution est d'utiliser de la pagination que nous allons voir en détail dans la section suivante.
Swapping
Pour pouvoir s'exécuter un processus doit se trouver entièrement en mémoire, alors lorsqu'il y a beaucoup de processus en mémoire et peu de mémoire disponible, on peut mettre un processus qui ne s'exécute pas (état ready) sur le disque dur pour libérer de la mémoire (via une partition sur le disque dur ou via un fichier "swap file").
Un processus peut être swappé lorsque son quantum de temps a expiré (retour de running à ready), si le quantum est petit il y aura beaucoup de changement de processus et donc beaucoup d'accès au disque en revanche si le quantum est grand, il y aura moins de changements de processus et moins d'accès au disque.
Les performances de ce mécanisme sont de ce fait déterminées par le temps de transfert mémoire ⇆ disque.
On ne peut swap que les processus auquel on n'a pas besoin d'accéder à la mémoire, c'est-à-dire les processus en état ready car pour les processus en état waiting, le système d'exploitation doit pouvoir accéder à la mémoire du processus pour y faire les entrées-sorties.
La pagination

La pagination permet d'avoir un espace adressage en mémoire physique non contigu. Elle nécessite toute fois une modification du MMU pour intégrer la table des pages. Elle va avoir une "table des pages" pour savoir où sont les morceaux. Cette méthode est utilisée par tous les systèmes d'exploitations actuels.
Fonctionnement
On va donc diviser la mémoire logique en blocs de taille fixe (les pages), on va faire de même avec la mémoire physique (que l'on va appeler les frames). Ainsi une page correspond à une frame. De ce fait, la table des pages va lier chaque page à une frame. L'espace de stockage pour le swapping est également découpé en blocs de même taille que les frames.
Lorsqu'un processus démarre, on va donc calculer la taille nécessaire en nombre de pages, ensuite, on va regarder le nombre de frames disponibles. S'il y a suffisamment de frames disponibles le processus peut alors démarrer, sinon le processus ne peut pas démarrer. Par exemple, si on a un processus nécessitant 10 octets et que chaque page fait quatre octets, cela nécessitera 3 pages. Sauf que s'il n'y a que 2 frames disponibles le processus ne pourra pas démarrer.
Les frames sont gérées par le système d'exploitation, ce dernier va garder la liste des frames libres et occupées et le nombre de frames disponibles. Le SE doit aussi mettre en place une protection pour empêcher un processus de dépasser son espace d'adressage.
Effet sur la fragmentation
Ainsi, la fragmentation externe n'existe plus, car bien que l'adressage soit vu comme contigu au niveau du programme, elle ne l'est pas au niveau physique.
La fragmentation interne, elle sera d'en moyenne 1/2 page par processus, comme on ne peut pas assigner des demi-frames, donc si un processus nécessite 10 octets, mais qu'une frame fait 4 octets et que chaque page correspond à une frame (en conséquence chaque page fait 4 octets également), on devra alors assigner 3 pages pour le processus de 10 octets, ce qui laisse ensuite deux octets (soit une demi-page) non utilisée.
La segmentation
Un·e utilisateur·ice voit un programme comme un ensemble d'instructions, de données, de fonctions, etc. Bref, un ensemble de blocs distinct dont les données ne sont pas mélangées avec les autres.
Il convient donc de traduire cette vue à l'intérieur du système d'exploitation. Pour cela, on va diviser l'espace d'adressage du processus en segments. Chaque segment a un nom, un numéro et une taille.
Les différents segments
Ainsi dans une architecture Intel x86, on peut avoir :
- Le Code Segment (CS) qui désigne le segment qui contient les instructions du programme (lecture seule)
- Le Data Segment (DS) qui contient les données du programme
(variables globales, variables
static) - Le Stack Segment (SS) qui contient la pile du programme (variables locales, appels, etc)
- Le Extra Segment (ES) qui est un segment supplémentaire défini par le·a développeur·euse du programme
De manière plus descriptive, on peut définir la mémoire du point de vue d'un programme comme ceci. À noter cependant que, cela est surtout comme ça que fonctionnaient les anciens systèmes, mais comme on va le voir dans la suite ce n'est plus exactement comme ça que cela fonctionne.

Avec la segmentation comme ceci, une adresse logique devient ainsi
<segment-number, offset>.
Avantages
En utilisant la segmentation, le système offre ainsi une protection adaptée car chaque segment contient des données d'une même nature et ne peuvent donc pas intervenir dans d'autres données. On ne peut pas par exemple accéder aux instructions du programme depuis le data segment.
Également, les segments peuvent être partagés entre plusieurs processus (par exemple avec les libraires systèmes) et ainsi faire une économie d'espace.
Désavantages
Cela fait un retour à la fragmentation, étant donné que les segments sont de taille variables, on retrouve de la segmentation externe. C'est pour cela qu'il faut combiner la segmentation avec la pagination.
Segmentation et pagination
Pour combiner les avantages de la segmentation avec les avantages de la pagination, on va regarder à l'exemple du fonctionnement de l'architecture des processeurs Intel 32 bits.
Ce processeur peut gérer un maximum de 16 384 segments de maximum 4 Go. L'espace d'adressage est découpé en deux parts égales. Une partition pour les segments privés (par exemple, processus) et une autre pour les segments partagés (par exemple, librairie partagée).
Il y a également deux tables, la LDT (Logical Descriptor Table) pour la partition des segments privés, et la GDT (Global Descriptor Table) pour les segments partagés.
Conversion vers adresse physique
Pour passer de l'adresse logique à l'adresse physique, il va falloir passer par deux intermédiaires :

- L'unité de segmentation qui transforme l'adresse logique en adresse linéaire
- L'unité de pagination qui transforme l'adresse linéaire en adresse physique.
Unité de segmentation
L'adresse logique est composée d'un sélecteur et d'un déplacement. Le sélecteur est lui-même composé de 3 informations :
- Le numéro du segment (noté s)
- Si c'est un segment privé ou partagé (LDT ou GDT) (noté g)
- Des informations de protection (noté p)
À partir de cette adresse logique, l'unité de segmentation construit l'adresse linéaire.
Unité de pagination
L'adresse linéaire est composée de 3 informations,
- Le directory, qui indique la table des pages à utiliser parmi le répertoire des tables de pages du processus courant
- La page, qui indique la page dans la table des pages
- Le offset (déplacement), qui est le même que celui cité dans l'adresse logique.
À partir de cette adresse linéaire, l'unité de pagination construit l'adresse physique comme vu précédemment dans le chapitre sur la Pagination.
Mémoire virtuelle
Il a été dit précédemment qu'il faut qu'un programme soit entièrement en mémoire pour pouvoir s'exécuter comme processus, alors comment faire lorsque le programme est plus gros que la taille de mémoire vive ?
Ce qui est utilisé par les systèmes aujourd'hui c'est la mémoire virtuelle, il s'agit d'utiliser le disque dur comme mémoire supplémentaire à la RAM.
Cela est bien sûr plus lent, surtout si le stockage est un disque dur (et pas un SSD), mais il permet de faire tourner de très gros programmes (ou juste énormément de processus) avec peu de RAM.
Utilisation de la pagination

Cela tombe bien, car la pagination est justement très adaptée à cela, car il suffit de lier de l'espace sur le disque à la table des pages (memory map sur le schéma). Ainsi la mémoire virtuelle sur le disque va être divisée en pages.
La table des pages doit bien sûr être adaptée pour pouvoir disposer d'un bit indiquant si la page se trouve sur le disque ou sur la mémoire physique.
Et le stockage/disque doit avoir une partie prévue pour contenir la mémoire virtuelle, celle-ci est appelée "swap device". Il s'agit d'un fichier sous Windows (Pagefile.sys), et d'un fichier ("swapfile") ou d'une partition ("swap partition") sous Linux.
Fonctionnement
Avec la mémoire virtuelle, les pages du processus à exécuter se trouvent sur le disque dur. Lors du chargement du programme, seules les pages nécessaires sont placées en mémoire physique.
Le changement entre mémoire virtuelle et mémoire physique est effectué lorsqu'une page non chargée est demandée. Lors du chargement, le système alloue quelques pages et les charge depuis le disque.
Ainsi lorsqu'une page est demandée, on regarde dans la table des pages pour voir si elle est présente en mémoire (bit valide), si oui tout va bien et tout se passe comme d'habitude. En revanche si ce n'est pas le cas (bit invalide) alors, il s'agit d'un défaut de page.
Traitement d'un défaut de page
Quand un défaut de page survient, il faut le résoudre le plus vite possible pour ne pas impacter les performances du système :
- On vérifie si la page demandée est présente dans l'adressage du programme, si ce n'est pas le cas alors c'est un memory overflow ce qui provoque un arrêt du processus.
- Si la page existe, ainsi on trouve une frame libre en mémoire physique et récupère la page depuis le disque
- On ajuste la table des pages pour indiquer la page comme valide et indiquer sa position dans la mémoire physique
- On redémarre le processus à l'instruction qui a causé l'erreur
Les défauts de pages faisant des appels d'entrée-sortie au disque, il est important d'en avoir le moins possible afin de ne pas trop impacter les performances du système.
Que faire quand il n'y a plus de frames ?
Lorsqu'un défaut de page survient, mais qu'il n'y a plus de frame disponible sur la mémoire physique, il faut alors que le système en libère une.
Pour cela, il faut que le système choisisse quelle frame remplacer, l'écrivent sur le disque et mettent à jour la table afin de libérer une frame pour résoudre le défaut de page.
Algorithmes de choix des pages victimes
Il est important d'utiliser un bon algorithme pour choisir les pages qui seront mises en mémoire virtuelle, car sinon cela risque d'augmenter le nombre de défauts de page et donc de considérablement ralentir le système.
Voici une comparaison de plusieurs algorithmes :
- FIFO (First In, First Out) la page qui est sélectionnée est la page la plus ancienne. Cependant, la performance de cette méthode n'est pas très bonne, car ce n'est pas parce qu'une page est vieille qu'il ne faudra pas y accéder souvent.
- OPT (Remplacement Optimal), cela consiste à essayer d'avoir le taux de faut de page minimal en éliminant la page qui ne sera plus nécessaire avant longtemps. Cependant, ce mécanisme est dur à implémenter, car on ne peut pas savoir en avance ce qui sera nécessaire. Ce mécanisme sert uniquement de base théorique aux autres systèmes.
-
LRU (Least Recently Used) consiste à choisir la page la moins
récemment utilisée. Pour implémenter cela, il faut soit y ajouter une
timestamp (ce qui rendra la chose moins efficace), ou alors mieux
utiliser un système de pile, ainsi dès qu'une page est utilisée, on la
met en haut de la pile, comme ceci, on sait que la page la moins
utilisée sera forcément la dernière de la pile.
- LRU approximé est une des variantes du LRU. L'idée est de définir un bit de référence pour chaque page. Initialement le bit est à 0 pour tous, dès qu'une page est accédée, le bit est mis à 1. Lorsque tous les bits sont à 1, on met tout à 0 sauf la dernière. Ainsi lorsqu'un défaut de page survient, la page victime sera la première page avec un 0 (vous pouvez trouver plus d'information dans cette vidéo).
- LRU avec octet de référence, l'idée ici est d'utiliser la méthode précédente, mais à intervalle régulier collecter le bit de référence pour le placer dans un octet de référence. Ainsi lorsqu'il faut choisir quel page sera la victime, il suffit de prendre celle qui a l'octet de référence le plus bas. Et dans le cas où il y en a plusieurs avec la même valeur, prendre le premier.
- Algorithme de la seconde chance, l'idée est de stocker 2 bits par page, une pour le bit de référence (voir LRU approximé) et l'autre pour un bit de modification. Le bit de modification est mis à un si la page a été modifiée sur la mémoire physique, mais pas encore sur la mémoire virtuelle. À l'inverse, elle est mise à 0 si elle est égale à la mémoire virtuelle. Ainsi, on peut savoir si une page a été utilisée et si elle nécessite une écriture sur le disque. Le meilleur choix étant de choisir une page qui n'a pas été utilisée récemment ET qui n'a pas été modifiée.
- LFU (Least Frequently Used) consiste à compter le nombre de fois qu'une page est utilisée et à choisir la page avec le plus petit compteur. Le problème est que ce n'est pas par ce qu'une page a été très utilisée qu'elle le sera toujours. À l'inverse ce n'est pas par ce qu'une page n'a pas beaucoup été utilisée qu'elle ne va pas le devenir.
- MFU (Most Frequently Used) consiste, elle aussi, à compter le nombre de fois qu'une page est utilisée et à choisir la page avec le plus grand compteur en réponse à l'observation statistique du LFU. Cependant, ces deux algorithmes sont peu utilisés, car ils sont peu efficaces.
Amélioration des performances
Écriture retardée des pages
Pour améliorer les performances en cas de défaut de page, on peut garder un ensemble de page (appelée pool) qui sont toujours immédiatement disponibles. Ainsi, lorsqu'une page victime nécessite d'être sauvegardée (bit de modification à 1 dans l'algorithme de la seconde chance), il suffit de donner une page du pool au processus qui est donc utilisable directement. Ensuite, on sauvegarde la page victime dans la mémoire virtuelle et cette page intègre ensuite le pool.
Allocation des frames
Il faut avoir une allocation raisonnable de la mémoire physique (frames), si trop de frames sont alloués au processus, on risque de tomber vite à court de frame et ainsi faire beaucoup de défauts de pages. Si trop peu de mémoire frames sont allouées, alors on tombe vite dans des défauts de page.
Alors il faut trouver un moyen d'allouer les frames de manière à satisfaire le plus possible tous les processus.
- La première méthode est celle de l'allocation équitable, on divise le nombre de frames disponible par le nombre de processus actifs. Cette méthode n'est pas intéressante, car cela créera un gaspillage pour les petits processus et une mauvaise performance pour les plus gros.
- La deuxième méthode est celle de l'allocation proportionnelle, les frames sont allouées proportionnellement à la taille du processus. Il faut toute fois tenir compte de la multiprogrammation, si de nouveaux processus sont créé le nombre de frames par processus va diminuer et si des processus se terminent les frames sont de nouveau disponibles. Il faut aussi tenir compte de la priorité des processus, un processus de haute priorité doit s'exécuter vite, plus il a de ressources plus, il va s'exécuter vite et donc plus vite ces frames seront libérées.
Trashing
L'allocation des frames est ainsi un problème compliqué, si on n'alloue pas assez de frame à un processus, le processus va passer beaucoup de temps à transférer des informations. Le trashing c'est lorsqu'un processus n'a pas suffisamment de frames allouées pour s'exécuter correctement et passe ainsi plus de temps à récupérer des pages qu'à s'exécuter.
La cause de ce problème est que, comme on a vu avec les processus, pour utiliser au mieux le CPU lorsque ce dernier est peu utilisé, le système va augmenter le degré de multi-programmation, ce qui va diminuer le nombre de frames disponibles et donc augmenter le nombre de défauts de pages. Sauf que pour résoudre le défaut de page les processus concernés devront être mis dans l'état waiting en attente de l'entrée-sortie, ce qui va ainsi de nouveau réduire l'utilisation du CPU. Ainsi le cycle vicieux se répète.
Modèle de la localité
Une manière de résoudre ce problème est d'utiliser le modèle de la localité.
Une localité, c'est un ensemble de pages qui sont activement utilisées ensemble. Un programme est ainsi composé de plusieurs localités différentes qui peuvent se chevaucher. Lorsqu'un processus s'exécute, ce dernier va de localité en localité.
Par exemple, lorsqu'une fonction est appelée, cela définit une nouvelle localité et quand l'on quitte cette fonction, on entre dans une autre localité.
Ainsi si on arrive à identifier la localité en cours, on peut alors charger suffisamment de frames pour les accommoder, cela va créer des défauts de pages jusqu'à ce que toutes les pages de la localité jusqu'à ce qu'elle soit toutes en mémoire, ensuite elles ne feront plus aucun défaut de page jusqu'à ce qu'on change de localité.
Si on n'alloue pas suffisamment de frames par rapport à la localité courante le système va faire du trashing.
Le système de fichiers
Introduction et définition d'un fichier
Définition d'un fichier
Un fichier est une collection nommée d'information en relation. Pour l'utilisateur·ice c'est un moyen de conserver des informations.
Le contenu d'un fichier est défini par son type (et donc sa structure), le programme qui l'a créé et les informations placées par l'utilisateur·ice.
Il existe plusieurs médias qui peuvent être utilisés pour stocker des fichiers de manière "définitive". La qualité de ce dernier est importante, par exemple le stockage à long terme sur les disques optique est difficile à garantir.
Le système d'exploitations propose, grâce aux fichiers un moyen d'utiliser l'espace de stockage. Le fichier est une abstraction nécessaire qui permet la représentation informatique de concept existants, et cela, de manière uniforme et simple d'accès.
Un fichier a plusieurs attributs tel que, le nom, l'identifiant, le type, les permissions, la localisation, la taille, la date de création et le propriétaire.
Opérations sur les fichiers
Les opérations sur les fichiers sont,
- La création qui alloue de l'espace de stockage et stocke les informations concernant le fichier.
- La lecture qui est un appel système qui permet de lire le contenu d'un fichier et de stocker le résultat en mémoire.
- L'écriture qui est un autre appel système qui permet d'écrire dans un fichier des informations présente en mémoire.
- Le positionnement qui est un déplacement du pointeur de position centrale (pour pouvoir lire ou écrire à un certain endroit).
- La suppression qui correspond à supprimer le fichier ou une partie de celui-ci
Ouverture d'un fichier
L'ouverture d'un fichier est l'opération indiquant au système d'exploitation que le programme souhaite accéder à un fichier. Lors de cette ouverture le système mémorise les informations sur le fichier, vérifie si l'accès est autorisé et initialise les structures internes et place le pointeur de position au début.
Une fois que le traitement est fini, le fichier est fermé, ce qui va supprimer les structures internes.
Ce système d'ouverture et de fermeture soulage fortement le système d'exploitation, car sans ça il faudrait répéter toutes les procédures d'ouverture et fermeture à chaque opération sur le fichier, tandis qu'ici, on le fait qu'une fois.
Il est aussi bon de noter que plusieurs utilisateurs doivent pouvoir ouvrir les , il faut donc mettre une structure efficace en mémoire pour éviter les informations en double.
Informations à retenir sur les fichiers utilisés
Les informations à retenir sur le fichier sont, le mode d'ouverture (lecture seule, lecture-écriture, écriture seule, etc), l'emplacement vers le premier bloc du fichier, la position courante, et les permissions d'accès.
Type de fichier
Pour traiter le fichier correctement, il faut connaitre sa structure interne, et pour cela, il faut connaitre son type.
Le type est identifié par l'extension (sous Windows), par un Uniform Text Identifier (sous Mac OS X), par un "nombre magique" qui est la valeur des premiers octets (sous Unix) et avec des "attributs étendus" sous OS/2.
Méthode d'accès des fichiers
La méthode d'accès aux fichiers dépend du support physique, ainsi une bande magnétique aura un accès séquentiel alors qu'une clé USB ou un disque dur aura un accès aléatoire.

L'accès séquentiel correspond à un enregistrement en séquence, ainsi pour pouvoir lire le 10e élément, il faut d'abord passer sur les neuf premiers.
L'autre type d'accès est l'accès aléatoire ou direct qui correspond à des enregistrements de taille fixe, ainsi, on peut calculer directement l'adresse de l'élément auquel on veut aller sans avoir besoin de lire les précédents.
Il est aussi possible d'avoir un accès séquentiel indexé qui va créer un index permettant à la fois un accès séquentiel et un accès direct aux fichiers.
Structure du système de fichiers
Pour organiser le système de fichier, il y a deux structures principales,
La partition qui est une partie du disque dur. Ainsi, on peut découper le disque en plusieurs partitions (exemple, partition système, partition de données), ainsi cela peut permettre d'isoler des données du reste ou encore d'avoir plusieurs systèmes d'exploitations sur un même disque (dual-boot).
La deuxième structure est le répertoire (ou dossier), qui contient les informations sur les fichiers qu'il contient (nom, emplacement, taille, pointeur vers le premier bloc).
Ainsi, la structure interne d'un répertoire doit permettre de localiser, créer, supprimer, renommer, visualiser des fichiers ou encore aller dans un autre répertoire.
Organisation des répertoires
Les répertoires peuvent être à un niveau, deux niveaux ou sous forme
d'arbre (c'est ce qui est utilisé aujourd'hui). Le répertoire de départ
est appelé le répertoire racine (ou root directory), ainsi, on
va représenter ce répertoire racine par un / ou un \.
Ainsi, un fichier peut être défini soit par un chemin d'accès
absolu, c'est le chemin d'accès partant du répertoire racine
(exemple /home/snowcode/image.png).
On peut aussi définir un fichier par un chemin d'accès relatif,
c'est un chemin d'accès partant d'un autre répertoire. Voici par exemple
un chemin d'accès relatif au dossier /home : snowcode/image.png ou
encore ./snowcode/image.png.
La manière de supprimer un dossier qui contient des fichiers ou d'autres
dossiers dépendent du système d'exploitation. Par exemple, sous Linux,
pour supprimer un dossier, il faut faire rm -r mondossier le -r
signifiant qu'il va supprimer de manière récursive.
Fonctionnement des liens
Sous Windows, on utilise des raccourcis, les raccourcis sont
simplement des fichiers .lnk désignant un autre emplacement.
En revanche, sous Unix, on utilise des liens symboliques, c'est une entrée particulière (comme un fichier ou un dossier) qui désignent un emplacement différent.
À la différence de Windows, si un programme ouvre un lien symbolique, il va automatiquement ouvrir le fichier (ou le dossier) qui est pointé par ce dernier. C'est donc très intéressant pour faire apparaître un même fichier à plusieurs endroits.
Sous Linux, un lien symbolique peut être créé avec la commande
ln -s <chemin de fichier vers lequel pointer> <position du lien>
Opération de montage
L'opération de montage permet de rendre accessible un système de fichier. Il peut s'agir d'une autre partition, d'un autre média (DVD, USB, etc), et le format peut être différent de la partition actuelle (NTFS, FAT, ext4, etc).
Le format de systèmes de fichiers FAT, bien qu'ancien et un peu limité, a l'avantage d'être supporté par tous les systèmes d'exploitations. En revanche, NTFS est un système Windows, ext4 est un système Linux et APFS est un format de système macOS.
Durant cette opération de montage, le système vérifie la cohérence et donne accès aux informations.
Cette opération de montage peut être implicite (le système le fait automatiquement) ou explicite (l'utilisateur·ice doit lui demander spécifiquement de monter le système).
Ainsi dans Linux, si je connecte une clé USB et que je la monte dans un dossier, je pourrais aller dans le dossier et interagir avec les fichiers comme si de rien était alors qu'en vérité ces fichiers sont sur la clé USB.
Implémentation
Maintenant on va voir comment la structure vue précédemment est implémentée dans le système d'exploitation.
Informations stockées
Sur le disque on va stocker :
- Le boot control block, qui sont les informations nécessaires pour démarrer le système d'exploitation
- Le partition control block, qui contient les informations détallant les partitions en cours (nombre de blocs, taille, etc), le système le plus utilisé aujourd'hui est GPT, autrefois, c'était MBR.
- Le root directory qui est le répertoire principal pour le stockage des dossiers et fichiers
- Le file control block qui contient les informations (propriétaire, permissions, etc) sur les fichiers (sous Unix, on va parler d'i-nodes)
En mémoire, on va retenir :
- La table des partitions montée et des chemins d'accès (vous pouvez
aussi la voir dans
/proc/mounts) - Les informations sur les répertoires récemment visités, car s'ils sont récemment visités, ils ont de grandes chances de l'être souvent.
- La table générale des fichiers ouverts (TFO) qui décrit tous les fichiers ouverts sur le système. À savoir que si un fichier est ouvert par deux processus différents, il n'apparaîtra qu'une fois dans cette table.
- La table des fichiers par processus (TDF, table des descripteurs de fichiers), décrit les fichiers ouverts pour le processus courant en incluant des informations supplémentaires par rapport à la TFO tel que la position courante et le mode d'ouverture.

Ainsi, lorsqu'un fichier est créé, on va stocker un FCB (file control block ou i-node) pour y inclure les permissions, la date, le propriétaire, le groupe, la taille, le premier bloc, etc.
Ensuite le fichier va être enregistré dans la TFO (qui comprend les informations du FCB ainsi que le nombre de processus lié à ce fichier).
Le fichier va aussi être enregistré dans la TDF du processus pour inclure le mode d'accès et le pointeur de position courante.
Lorsque le fichier est fermé, on supprime l'entrée de la TDF du processus et on met à jour la TFO. On ne supprimera ce fichier de la TFO que si plus aucun processus n'utilise le fichier.
Implémentation des répertoires
Maintenant, il faut trouver une manière d'implémenter les répertoires de manière que leur gestion puisse être rapide et qu'il soit facile de retrouver l'information.
Plusieurs méthodes sont possibles, mais le choix dépendra de si on souhaite favoriser la rapidité ou l'espace disque.
Il faut donc pouvoir gérer le fait qu'un dossier peut contenir un autre dossier aussi bien que des fichiers.
Pour en savoir plus sur les deux solutions vu ci-dessous, vous pouvez consulter cet article.
Répertoires sous forme de liste

La première solution est simplement de considérer chaque répertoire comme une liste contenant les noms des fichiers avec un pointeur vers le début de ces fichiers.
Cela implique donc qu'il faudra faire une recherche séquentielle pour trouver un fichier dans un répertoire, de même cela implique qu'il faudra faire cette même recherche séquentielle pour créer le fichier (pour vérifier si le nom existe) ainsi que pour le marqué comme libéré.
Les inconvénients de cette méthode sont que le parcours séquentiel ralenti considérablement l'utilisation. Si on décide de faire une liste triée, le problème sera toujours là, car il faudra toujours maintenir la liste triée.
Note sur la libération de l'espace
Marquer l'espace comme libéré consiste à marquer l'entrée du répertoire comme inutilisée.
Il est important de se rappeler que lorsqu'on supprime un fichier ou un dossier, ce dernier n'est pas réellement supprimé, l'espace est simplement marqué comme étant libre. Il est donc tout à fait faisable de récupérer ces informations si on lit séquentiellement les espaces libres. Pour supprimer définitivement un fichier, on peut utiliser la commande
shred
Répertoires sous forme de table hashée

L'idée de cette deuxième solution est d'avoir une liste d'éléments, mais avec en plus une table de hash donnant directement le pointeur du fichier.
Ainsi, lorsque l'on cherche un fichier avec un certain nom, on va hasher le nom du fichier, ce qui va nous donner la clé dans la table. Ensuite, on va pouvoir trouver le pointeur vers le fichier directement en la récupérant depuis la table avec la clé.
Cette méthode a l'avantage d'être très rapide, car il n'y a pas besoin de parcourir quoi que ce soit pour trouver les fichiers. Il est toute fois important de noter qu'il faut trouver des solutions pour traiter les cas où plusieurs noms arriveraient au même hash (collision).
Un désavantage de cette méthode est que les tables hashées ont généralement une table fixe et que la performance de la fonction de hash est aussi dépendante de la taille de la table. C'est pourquoi il faut soit limiter la taille du dossier, ou bien étendre la table lorsqu'elle est pleine.
Allocation des fichiers
Maintenant, il va falloir trouver un moyen d'allouer efficacement les fichiers le plus rapidement possible.
On va parler ici de trois méthodes couramment utilisées, la méthode utilisée dépend du système d'exploitation.
Allocation contiguë
L'allocation contiguë signifie que chaque fichier occupe des blocs qui se suivent sur le disque. Ainsi, si quand un bloc est en cours de lecture, la lecture du bloc suivant ne requiert pas de mouvement de la tête de lecture, ce qui offre donc une performance intéressante.
Également, si on sait combien de blocs occupe le fichier et que l'on sait la position de son premier bloc, on peut calculer la position du dernier bloc du fichier, ainsi cela fait un accès séquentiel et direct, facile et rapide.
Problèmes
Le souci avec l'allocation contiguë est que l'on va se retrouver avec des problèmes de fragmentation externe à cause des allocations et libérations successibles. Pour résoudre ce problème, il faut donc utiliser le compactage (la défragmentation). C'est une opération qui peut être dangereuse si elle est interrompue ainsi que chronophage.
Un deuxième problème est de déterminer la taille initiale du fichier, car les fichiers ont tendance à croitre avec le temps. Si un fichier est suivi directement par un autre fichier, que faire si on veut faire croitre le fichier A ?
Si on veut copier le fichier à un autre endroit, cela va rendre le système beaucoup plus lent.
Si on prévoit un "buffer" pour permettre au fichier de croire, alors ça nous mène à de la fragmentation interne et externe.
Résolution du problème de la fragmentation sous Linux
Pour régler ces problèmes, cependant Linux (avec ext4) utilise une variante. À la place de placer chaque fichier à la suite des autres. Les fichiers sont éparpillés sur le disque de manière à maximiser les espace entre eux.
De cette manière, on s'assure que les fichiers ont toujours suffisamment de place pour grandir et quand les fichiers sont trop rapprochés, le système d'exploitation va les réarranger pour les espacer à nouveau.
Grâce à cette technique, la défragmentation est presque entièrement inutile sous Linux, car le taux de fragmentation reste toujours très bas.
Si vous voulez en savoir plus, vous pouvez consulter cet article Wikipedia sur ext4 ou cet article comparant la fragmentation sous Linux et Windows.
Allocation chainée
L'allocation chainée consiste à ce que chaque fichier soit une liste de blocs chainés entre eux. Ainsi, le répertoire contient un pointeur vers le premier bloc de la liste et chaque bloc contient un lien vers le bloc suivant.
Cela a l'avantage de ne pas avoir de fragmentation externe et le fichier peut croitre sans problème puis ce que le bloc peut être écrit n'importe où.
Problème
Le problème de cette méthode est que le contenu des fichiers va être éparpillé partout, la tête de lecture va donc devoir beaucoup voyager et donc ralentir la lecture et l'écriture.
Pour résoudre ce problème, le système FAT alloue des groupes de blocs (cluster) plus tôt que des blocs. Le problème toute fois avec cette méthode, c'est que cela crée de fragmentation interne si les clusters ne sont pas utilisés complètement.
Allocation indexée
Le principe de l'allocation indexée est de garder un bloc "index" pour chaque fichier. Le bloc va contenir les informations des positions de tous les autres blocs du fichier.
L'avantage principal de l'allocation indexée est qu'elle permet un accès direct aux différents blocs utilisés dans le fichier. Cela permet donc un accès au fichier beaucoup plus rapide si on veut accéder à un point précis.
Problème
Un problème avec cette méthode est que l'on ne sait pas d'avance la taille nécessaire de l'index. Ainsi, on peut soit lier les index entre eux (via une liste chainée) ou alors utiliser des index d'index (index à plusieurs niveaux).
Un autre problème est que cela empire le problème de tête de lecture de l'allocation chainée, car il faudra, en plus de devoir passer sur tous les blocs éparpillés, passer sur tous les blocs d'index.
Également, pour les très petits fichiers (2 ou 3 blocs), l'allocation indexée garde un bloc complet pour l'index, ce qui est donc beaucoup moins efficace au niveau de l'utilisation du disque.
Quelle méthode d'allocation choisir ?
La méthode d'allocation à choisir dépends donc de la façon dont le système sera utilisé, car chaque méthode montre des différences (niveau temps, gaspillage, etc) comme nous l'avons vu juste avant.
Une idée est donc de permettre différents types d'allocations différentes ou de mêler plusieurs méthodes.
Par exemple, certains systèmes utilisent l'allocation contiguë pour les petits fichiers et l'allocation indexée pour les fichiers plus gros ou grandissent.
Gestion de l'espace libre
Nous avons vu précédemment le fonctionnement de la gestion de l'allocation, cependant pour faire cela, il faut prendre un bloc libre et l'utiliser. Il faut donc avant tout trouver un moyen de trouver un bloc libre.
On peut donc utiliser les mêmes méthodes que celles utilisées pour la gestion de mémoire. C'est-à-dire l'utilisation de table de bits ou de liste chaînées.
En utilisant une table de bits (ou bitmap en anglais), on va garder une table qui mentionne pour chaque bloc s'il est libre ou occupé. L'avantage est que cette méthode est assez simple et efficace. En revanche, le désavantage est que pour des gros volumes cette table va prendre beaucoup de place. Par conséquent, cette méthode est intéressante pour des volumes faibles, mais devient embêtante pour des volumes plus grands.
L'autre solution est d'utiliser une liste chainée, ainsi chaque bloc libre connait le bloc libre suivant. On peut également faire en sorte de grouper les blocs libre de manière à pouvoir les allouer plus rapidement sans devoir tous les parcourir un à un.
ext2(précurseur de ext3 et ext4) utilisait une liste chainée pour stocker les blocs libres. Cependant, cela menait à plus de fragmentation, car les fichiers étaient collés les un aux autres (voir Résolution du problème de la fragmentation sous Linux pour comprendre pourquoi).Ensuite
ext3a commencé à utiliser une table de bit. Cependant, ce système faisait les choses bloc par bloc, alorsext4a remplacé ce système par un nouveau qui fait plusieurs blocs d'un coup ce qui améliore drastiquement les performances. De plus,ext4est optimisé de manière à séparer les allocations pour éviter la fragmentation.
Restauration des données
Vérification et correction
Le système de fichier peut devenir incohérent et des erreurs peuvent apparaitre à cause d'arrêt inattendu du système ou encore de problèmes matériels. C'est pour ces raisons que le système d'exploitation doit mettre en place des mécanismes pour vérifier la cohérence du système et corriger les erreurs.
La vérification consiste à parcourir les différents blocs des différents fichiers et à résoudre les problèmes qui pourraient survenir, par exemple :
- Un bloc est défini 2 fois comme libre, dans ce cas, il suffit de supprimer l'une des deux occurrences (ou lien si c'est une liste chainée)
- Un bloc est défini comme à la fois libre et à la fois occupé. Alors, on considère qu'il est occupé.
- Un bloc n'est défini ni comme libre, ni comme occupé. Alors, on considère qu'il est libre.
- Un bloc (ou une séquence de blocs) est défini comme occupé par deux fichiers différents. Alors, on duplique ces blocs communs dans les deux fichiers.
Sauvegarde et restauration
La sauvegarde consiste souvent en la copie de donnée, ailleurs. Elle est prévue pour une restauration rapide.
L'archivage consiste à sauvegarder des données plus longtemps, dans quel cas il faut également faire attention au média utilisé pour qu'il soit fiable, éprouvé, robuste et durable.
Il y a deux types de sauvegardes, les sauvegardes incrémentales et différentielle.
La sauvegarde incrémentale consiste à seulement sauvegarder les changements. Par exemple, la première fois, on fait une sauvegarde complète, la deuxième fois, on fait une sauvegarde de ce qui a changé depuis la première fois, et la troisième fois, on fait une sauvegarde de ce qui a changé depuis la deuxième fois.
La sauvegarde différentielle consiste à ne copier que les modifications ayant changé depuis la dernière sauvegarde complète. Par exemple, la première fois, on fait une sauvegarde complète, la deuxième fois, on fait une sauvegarde de ce qui a changé depuis la première fois, la troisième fois, on fait une sauvegarde de ce qui a changé depuis la première fois (ce qui inclut donc une redondance de ce qui était dans la deuxième sauvegarde), etc.
La taille de la sauvegarde différentielle va donc beaucoup plus augmenter que celle de la sauvegarde incrémentale, jusqu'à la prochaine sauvegarde complète.
La sauvegarde incrémentale est donc plus légère et plus rapide, mais sera plus complexe à restaurer (car s'il y a eu 17 sauvegarde, il faudra restaurer les 17 éléments) tandis qu'avec la sauvegarde différentielle, il suffira de restaurer la dernière sauvegarde complète et la dernière sauvegarde différentielle.
Système de fichiers journalisé
Le système de fichier est quelque chose de complexe et sa manipulation nécessite beaucoup d'opérations. Un problème peut arriver n'importe quand et si l'opération en cours ne peut pas se terminer, alors cela peut mener à un état incohérent dont la correction pourrait engendrer une perte de donnée.
Le système de fichier journalisé permet de limiter les dégâts en gardant un historique des opérations en cours, de cette manière le système peut défaire les opérations non terminées en cas de panne.
C'est un système qui est assez similaire à celui des transactions en base de données, il faut donc garantir l'atomicité (le fait qu'une action ne puisse pas être décomposée), la cohérence, l'isolation et la durabilité (ACID) pour chaque action du journal.
Entrées sorties
Introduction
Un système sans entrée ou sortie n'est pas très utile. Car s'il n'y a pas d'entrée-sortie, ça veut dire, pas de réseau, pas d'écran, pas de clavier, etc.
Il est donc très important pour le système d'exploitation de contrôler les périphériques. Par exemple, le SE doit pouvoir gérer les interruptions (évènements envoyés par les périphériques) ainsi que traiter les erreurs ou autres évènements qui pourraient survenir (exemple, on débranche la clé USB pendant une action de lecture).
Le SE doit aussi fournir une interface vers ces périphériques de la manière la plus uniforme possible pour rendre les périphériques faciles d'accès et universel.
Côté matériel
Au niveau matériel, on distingue plusieurs éléments :
- Le périphérique d'entrée-sortie, par exemple clavier, souris, écran, etc. On pourra le caractériser par sa nature ainsi que sa vitesse de transmission. Ces périphériques vont faire de la signalisation (ou interruption) pour signaler au système que sa tâche est terminée.
- Le contrôleur qui est l'interface entre le périphérique et le système d'exploitation. Le contrôleur permet au SE de contrôler le périphérique.
Périphériques E/S
Il existe plusieurs types de périphériques d'E/S, ici, on va parler de deux types principaux.
Il y a les périphériques blocs où l'information est stockée dans des blocs de taille fixes et adressables. Un exemple de tels périphériques est un disque dur.
Il y a aussi les périphériques caractères où l'information est un flux de caractère sans tenir compte d'une structure quelconque, elle est donc non adressable. Par exemple, la carte réseau, clavier, souris, etc.
Controlleur de périphérique

Le contrôleur est la partie électronique qui contrôle le matériel. Souvent, le périphérique dispose d'une partie mécanique et d'une partie électronique (exemple, un disque dur). Cependant, ce n'est pas toujours le cas, par exemple la carte graphique n'est pas attachée à l'écran.
Certaines cartes d'extensions sont même dissociées de la carte mère, c'est par exemple le cas avec les périphériques USB.
Contrôle/commandes
Le système d'exploitation commande le périphérique au moyen du contrôleur, il n'interagit jamais directement avec le périphérique lui-même.
Le contrôleur dispose fréquemment d'un microprocesseur hautement adapté au périphérique, de registres qui permettent de commander le contrôleur et de mémoire pour faire les échanges (par exemple pour faire des buffers).
Interruptions
Le matériel envoie des interruptions pour signaler que l'opération en cours est terminée. Le gestionnaire d'interruption du système d'exploitation va gérer l'interruption.
S'il n'y a qu'une seule interruption, le système gère l'interruption et choisit ensuite le processus suivant à démarrer.
S'il y a plusieurs interruptions, le système traite d'abord les interruptions urgentes en ignorant temporairement les autres.
Fonctionnement
Le CPU sauvegarde le contexte du processus en cours et lance une routine (une fonction indépendante du reste du système) adaptée à l'interruption reçue. La routine à lancer est renseignée dans le vecteur des interruptions où pour chaque interruption un pointeur vers la routine à exécuter est renseignée.
Dès que l'interruption est traitée, l'état du contrôleur du périphérique est modifié. Le gestionnaire des interruptions est alors prêt à traiter les interruptions suivantes.
Une fois toutes les interruptions traitées, le système d'exploitation choisit le processus suivant à lancer.
Dialogue via port d'E/S
Ce type de dialogue entre le système et le contrôleur consiste à échanger des données en écrivant ou lisant des données dans les registres du contrôleur.
Cette méthode n'est plus trop utilisée aujourd'hui.
Dialogue via E/S mappé en mémoire
Dans cette méthode, on va faire correspondre une zone mémoire (de la mémoire centrale) aux registres du contrôleur. Ainsi, lorsque l'on lit dans la zone mémoire, on lit et/ou écrit dans les registres du contrôleur.
L'avantage de cette méthode est que l'on a juste à utiliser des instructions habituelles d'accès à la mémoire pour contrôler les périphériques.
Grâce à cette méthode, il n'y a donc pas besoin d'instructions assembleur particulières et il n'y a pas non plus besoin de mettre en place des mécanismes de protection particuliers, car il suffit d'interdire ou d'autoriser l'accès à la zone mémoire.
Amélioration des performances via DMA
Si on utilise simplement le contrôleur d'un disque dur, lorsque l'on veut lire sur ce dernier, le contrôleur va lire un bloc à partir du périphérique, et le placer dans sa mémoire, ensuite, il va vérifier l'information, puis faire une interruption au système d'exploitation. Enfin, ce dernier va exécuter la routine adaptée et copier l'information dans sa mémoire centrale.
Le problème avec ce système est que le CPU est fort sollicité pour faire le transfert et ne peut donc rien faire d'autre. Une solution à cela est d'utiliser un contrôleur DMA (Direct Memory Access). C'est un microprocesseur spécialisé dans le transfert d'informations entre un contrôleur quelconque et la mémoire centrale.
Ce contrôleur DMA peut aussi bien se trouver sur certains périphériques que sur la carte mère.
Le contrôleur DMA possède, comme tout contrôleur, plusieurs registres. Les siens sont, l'adresse (pour indiquer où les informations doivent être écrites en mémoire), le compteur d'octets (pour indiquer quelle quantité doit y être écrite), le registre de contrôle (qui spécifie de quel périphérique il s'agit, si c'est une lecture ou une écriture et de l'unité du transfert (octet, mot, etc)).
Ainsi, en utilisant un contrôleur DMA, lorsque l'on veut lire sur un disque dur, le système d'exploitation va indiquer au DMA les données dont il a besoin, puis va demander au disque une lecture. Ensuite le contrôleur disque va lire et vérifier les blocs et c'est le DMA qui va se charger de transférer directement les informations dans la mémoire. Une fois le transfert terminé, le DMA fait une interruption au système d'exploitation.
De cette manière, le CPU peut faire d'autres choses durant le transfert
Vol de cycle
Attention toutefois, lorsque le DMA travaille, il se peut qu'il entre en conflit avec le processus, car les mémoires ne peuvent faire qu'un accès par cycle.
Le DMA ne pouvant pas attendre aussi longtemps que le processeur, parce qu'il risque de perdre des informations, il a donc priorité d'accès à la mémoire. On dit alors qu'il y a un vol de cycle du processeur.
Côté logiciel
La partie logicielle de l'entrée-sortie est une partie du système d'exploitation qui a pour but de fournir une interface vers les périphériques tout en assurant une indépendance par rapport au type de périphérique.
Par exemple, l'accès à une clé USB doit être, du point de vue des programmes, identique à l'accès sur un disque dur.
Cette partie du système d'exploitation est divisée en quatre couches, que l'on va adresser en partant du plus proche du matériel vers le plus haut niveau.

Le gestionnaire d'interruption
Le gestionnaire de périphérique (le pilote) qui lance l'opération d'entrée-sortie, va attendre une interruption.
Lorsque l'interruption survient, gestionnaire d'interruptions va avertir le gestionnaire de périphérique et celui-ci va terminer l'opération voulue.
Lorsqu'une interruption survient, le gestionnaire d'interruptions va sauvegarder le contexte du processus en cours, créer le contexte pour le traitement de l'interruption, se place en état "disponible" pour traiter les interruptions suivantes, exécuter la procédure de traitement (la routine dont on a parlé dans la section précédente).
Une fois les interruptions gérées, le scheduler choisit le processus à démarrer.
Gestionnaire de périphérique (pilote ou driver)

Le gestionnaire de périphérique, aussi appelé pilote ou driver, dépends de la nature du périphérique, ainsi un gestionnaire de disque fonctionne très différemment d'un gestionnaire de souris.
Le gestionnaire de périphérique, afin d'être utilisable, doit être chargé au cœur du système, dans le noyau, en mode protégé. C'est pour cela qu'un mauvais driver pour conduire à des plantages du système d'exploitation.
Mais en même temps, ces gestionnaires de périphériques, écrits par les fabricants, doivent pouvoir être inséré facilement dans le noyau (kernel) pour être utilisé.
Fonctionnement
Le système appelle des fonctions internes (open, read, write, initialize, etc) des pilotes afin de commander le périphérique. Les pilotes vont ensuite vérifier si les paramètres reçus sont corrects et valide et vont traduire certains paramètres en données physiques.
Par exemple, un pilote de disque dur va traduire un numéro de bloc en cylindre, piste, secteur et tête.
Ensuite, le pilote vérifie si le périphérique est disponible (sinon il attend), il vérifie également l'état du périphérique et le commande.
Pendant le travail du périphérique, le pilote s'endort, car il ne peut plus rien faire. Une fois qu'il est réveillé par le gestionnaire d'interruption, il vérifie que tout s'est bien passé et transmet les informations.
La couche logicielle indépendante
La couche de logicielle indépendante (aussi appelée interface standard)
Cette couche fournit une interface uniforme pour les drivers (la fameuse API dont on a parlé plus tôt), ainsi que du buffering, de la gestion d'erreur, de l'allocation et libération des périphériques.
Interface standard
Grâce à cette couche, on s'assure que les drivers sont appelés de manière uniforme.

A gauche, un système sans interface standard, à droite un système avec une interface standard
Uniformisation des noms
La désignation d'un périphérique doit être non ambiguë, sous Linux le
répertoire /dev contient des entrées pour chaque périphérique. Un
périphérique est donc traité au même titre qu'un fichier, il ne peut
donc pas en avoir deux avec le même nom.
Par exemple, un disque dur sera appelé /dev/sda, si on met un autre
disque dur, celui-ci sera appelé /dev/sdb.
Buffering
Afin d'améliorer les performances du système et d'éviter de faire beaucoup d'accès inutilement, on garde des buffers (tampons) dans le système d'exploitation et dans les contrôleurs. L'objectif étant de placer en mémoire les informations qui sont souvent accédées.
Gestion d'erreurs
C'est aussi à cette couche que revient la gestion des erreurs. L'utilisation de périphériques induit un certain nombre d'erreurs (temporaire ou permanentes).
Il y a deux types d'erreurs, les erreurs de programmation qui surviennent lorsque l'opération demandée est impossible (exemple, écriture sur un périphérique d'entrée), dans quel cas on rapporte l'erreur et on s'arrête.
Et les erreurs d'entrées sorties qui surviennent lorsqu'une opération se termine de façon anormale (par exemple, on déconnecte le disque, ou le périphérique est défectueux). Dans ce cas, le driver décide de soit tenter à nouveau l'opération ou alors de rapporter l'erreur.
Allocations et libérations des périphériques
Certains périphériques ne sont pas partageables, par exemple avec une imprimante, il est impossible d'imprimer plusieurs choses en même temps.
Il revient alors au système d'exploitation de vérifier si le périphérique est libre et s'il peut être alloué au processus.
La fonction open permet à un processus d'informer le système
d'exploitation qu'il souhaite utiliser un périphérique, le système
vérifie alors sa disponibilité.
Couche d'entrée-sortie applicative
Cette partie de la gestion de l'entrée sortie est faite au niveau de l'application, par exemple via les libraires systèmes liées aux programmes.
C'est là que l'on va par exemple trouver les appels systèmes de stdio
tel qu'open, printf, read, write, etc.
Cette couche va également fournir un système de spooling qui permet de créer une fille d'attente pour l'accès aux périphériques non partageables. Par exemple via une liste de jobs d'impression pour une imprimante.
Disque
Matériel
Un disque magnétique est composé de plusieurs disques physiques appelés les plateaux.
Le disque est découpé en cylindres, pistes et secteurs. Il y a autant de pistes que de positions différentes de la tête de lecture.

Un cylindre, c'est l'ensemble de pistes à une position donnée de la tête de lecture.
Une piste correspond à un cercle sur un plateau à une certaine position de la tête de lecture. Chaque piste est elle-même découpée en secteur.
Les secteurs sont des blocs de tailles fixes qui compose chaque piste.
Pour en savoir plus sur le fonctionnement des disques dur magnétiques, vous pouvez consulter cette page Wikibooks.
Les disques dur ont une interface qui permet au contrôleur d'utiliser des commandes de haut niveau. La géométrie du disque dur n'est pas nécessairement celle qui est annoncée, car le nombre de secteurs par piste n'est pas constant.

A gauche, véritable géométrie du disque. À droite, géométrie du disque simplifie pour rendre les accès plus simple
RAID
RAID est une technologie qui consiste à combiner plusieurs disques afin d'améliorer les performances (si on a plusieurs disques, on peut par exemple écrire sur plusieurs disques en même temps) et/ou la fiabilité (si on a plusieurs disques, on peut par exemple dupliquer les informations sur tous les disques, comme ça si un disque tombe en panne, on peut restaurer les données).
Le mirroring consiste à dupliquer toutes les informations sur un second. Ainsi, lors d'un accès en écriture, le contrôleur effectue la modification sur les deux disques simultanément et indique qu'il a terminé lorsque l'opération est achevée sur les deux disques.
Le stripping consiste à répartir l'information sur plusieurs disques. De cette manière, si on a huit disques, on peut distribuer les informations sur chaque disque de façon à écrire huit fois plus rapidement qu'avec un seul.
Il existe plusieurs niveaux de RAID, certains utilisent du mirroring, d'autre du stripping et d'autres les deux de manière à favoriser les performances et la fiabilité.
Si vous souhaitez en savoir plus sur les niveaux de RAID, vous pouvez consulter cet article Wikipédia et celui-ci.
RAID 0

Le RAID 0 fait uniquement du stripping. Il va donc construire un grand espace disque en combinant les disques. Ainsi, les données sont réparties entre des différents disques de manière à améliorer les performances.
RAID 1

Le RAID 1 fait exclusivement du mirroring, il faut donc doubler le nombre de disques. Cela améliore beaucoup la fiabilité de l'information, mais il est assez couteux.
RAID 3

Le RAID 3 fait du stripping au niveau des octets. Un bit de parité est gardé sur un disque séparé et les octets vont être réparti sur les différents disques.
L'avantage du RAID 3 est que si on perd un disque, on peut reconstruire l'information à la volée en utilisant le disque de parité.
RAID 4

Le RAID 4 fait du stripping au niveau des blocs. Les blocs de parités sont gardés sur un disque séparé.
Un avantage du RAID 4 est que la lecture d'un bloc ne nécessite l'accès qu'à un seul disque (contrairement au RAID 3), on peut donc également satisfaire la lecture de plusieurs blocs simultanément si ceux-ci ne sont pas localisés sur le même disque.
Il y a cependant un problème à l'écriture, étant donné que tous les bits de parité sont sur le disque de parité, on ne peut pas écrire des blocs en parallèle, car on ne peut avoir qu'un seul accès au disque de parité à la fois.
RAID 5

Le RAID 5 est une amélioration du RAID 4 qui va distribuer les informations sur la parité, de cette manière chaque disque contient des blocs de données et de parité. À chaque bloc de donnée correspond un bloc de parité stocké sur un disque.
Lors d'une écriture, il y a alors moins de problème, car plusieurs requêtes d'écriture peuvent être faites en même temps parce que tout dépend de la position de la donnée à écrire et de la localisation de l'information de parité.
RAID 6

Le RAID 6 permet de protéger de la perte de deux disques dur, elle utilise un algorithme de parité plus complexe et nécessite un CPU plus important pour le contrôleur.
Plus il y a de données, plus le RAID 6 est préférable au RAID 5.
RAID 0+1

Ce niveau utilise RAID 0 pour le stripping et RAID 1 pour le mirroring de tous les disques en stripping. Il est très utile si l'efficacité et la protection sont importantes, cependant il est assez cher.
Lequel choisir ?
Généralement, c'est le RAID 5 qui est choisi s'il y a plusieurs disques ou alors le RAID 1 s'il n'y a que deux disques. Sauf dans des cas où il y a des demandes plus particulières au niveau de la performance et/ou de la fiabilité du système.
Options particulières
Il y a des options particulières sur les différents systèmes, notamment la possibilité de faire du hot-swap ou d'avoir des disques spare.
Le hot-swap consiste à pouvoir retirer des disques pendant que ceux-ci sont connectés (du moment qu'il n'est pas actuellement utilisé).
Le spare consiste à avoir un disque présent inutilisé, mais prêt à l'emploi. Ainsi, si un disque dur tombe en panne, le disque spare peut alors être utilisé.
Autres considérations
Il est important de bien considérer que le système ait un débit important pour avoir les meilleures performances.
Mais surtout, il est important d'avoir une certaine diversité entre les disques dur. Il ne faut donc pas prendre tous les disques dur de la même marque au même moment, de la même génération. Car alors, il y a de grandes chances que les disques se fatiguent de la même manièrent et tombe en panne plus ou moins en même temps.
Formatage
Avant qu'un disque ne puisse être utilisé, il doit être formaté (formatage de bas niveau), cette opération consiste à écrire la géométrie du disque (secteur, cylindre, piste, etc).
Cette opération doit être réalisée par le fabricant. De cette manière, chaque secteur contient un préambule (informations décrivant le secteur tel que le numéro ou le cylindre), les données et un code ECC pour la gestion des erreurs.
Une fois l'espace créé, il est possible de mettre en place des partitions, c'est la première structure logique du disque.
Le disque est séparé en plusieurs partitions, et chaque partition est
vue par le système comme un espace séparé. Par exemple, un système Linux
va voir les partitions /dev/sda1 et /dev/sda2 comme deux espaces
complètements différents.
Le secteur zéro du disque contient la partition control block et le boot control block qui mentionnent comment le disque et découpé et comment le système peut démarrer.
Le formatage de bas-niveau est une opération de formatage réalisée par le système d'exploitation, elle consiste à donner une structure à la partition (un format de système de fichier).
Scheduling
Le disk arm scheduling est une opération faite par le système d'exploitation pour planifier les requêtes d'entrées-sorties.
En effet, plusieurs requêtes d'E/S peuvent arriver depuis plusieurs processus pendant que le disque est toujours en train de traiter une requête, donc les autres requêtes doivent attendre.
L'importance du scheduling (avec les HDD) est de minimiser le seek-time, c'est-à-dire minimiser les mouvements de la tête de lecture afin de pouvoir lire les informations plus vite.
Nous allons donc, voire plusieurs algorithmes de scheduling différents,
- Le FCFS (First Come First Served), soit les requêtes sont servies dans l'ordre dans lesquelles elles arrivent. Cet algorithme a l'avantage d'être équitable, mais a de mauvaises performances, car il ne fait rien pour améliorer le temps de réponse du disque.
- Le SSTF (Shortest Seek-Time First), autrement dit de servir toujours la requête la plus proche de la position courante. Cet algorithme a l'avantage de faire diminuer le temps de réponse du disque. Mais il a le désavantage de devoir calculer les positions et risque également de causer de la famine parmi les requêtes les plus éloignées.
- Le SCAN (ou algorithme de l'ascenseur), où le bras de lecture va toujours dans la même direction jusqu'à arriver à la fin du disque avant de retourner dans le sens inverse, aussi, il n'y a plus de famine, car quoi qu'il arrive, on avance.
- Le C-SCAN (SCAN circulaire), fonctionne comme le SCAN sauf qu'au lieu de partir dans l'autre sens lorsque la fin du disque est atteinte, elle retourne à l'autre extrémité du disque.
- Le LOOK est une variante du SCAN qui a la place de continuer jusqu'aux extrémités du disque, va s'arrêter lorsqu'il n'y a plus de requête dans la direction.
- Le C-LOOK (LOOK circuliare), comme le LOOK, excepté qu'à la place d'aller dans la direction inverse, il va directement à la première requête.
Vous pouvez découvrir d'autres algorithmes ou avoir plus d'explication et d'illustrations sur les algorithmes décrit ici en allant lire cette page.
Choix de l'algorithme
Le SSTF est courant et fournit un bon remplacement à FCFS.
Si le disque est très chargé, C-SCAN et C-LOOK sont intéressants.
Le plus souvent on va trouver du SSTF ou une variante de LOOK.
Aujourd'hui, le scheduling est réalisé à plusieurs niveaux, par exemple au niveau du système d'exploitation, mais également au niveau des contrôleurs.
Gestion des erreurs
Il peut y avoir beaucoup d'erreurs différentes sur un disque.
Par exemple, des secteurs défectueux peuvent survenir lors de la construction du disque dur, notamment lors du formatage de bas niveau, ou même survenir durant l'utilisation du disque.
C'est pourquoi le système d'exploitation doit pouvoir se souvenir des blocs défectueux afin de ne plus les utiliser dans le futur.
Horloge
L'horloge est un périphérique spécial et essentiel. Il sert simplement à déterminer la date et l'heure.
C'est une fonction essentielle, car c'est nécessaire pour maintenir des statistiques, calculer le quantum de temps des processus, etc.

Fun fact : la Raspberry Pi n'a pas d'horloge, la date et l'heure est synchronisés via le réseau au démarrage. Et s'il n'y a pas de connexion, l'horloge va commencer à compter à partir de l'heure à laquelle il s'est arrêté.
Les systèmes MS-DOS n'avaient pas non plus d'horloge, il fallait donc indiquer la date et l'heure manuellement au démarrage.
L'horloge fonctionne avec un quartz, un compteur et un registre. Le quartz, lorsqu'il est sous tension, génère un signal périodique très précis, ce signal peut ensuite être utilisé pour la synchronisation des composants. Le signal est ensuite fourni au compteur qui va décompter jusqu'à arriver à zéro.
Une fois arrivé à zéro, une interruption est émise vers le CPU et le gestionnaire d'horloge prend la main.
Ensuite, ici, il y a deux modes de fonctionnement. Il y a le mode one-shot, le système envoie l'interruption et attends une réaction. Sinon, il y a le mode square wave qui, une fois que le compteur arrive à 0, il recommence. On parle ici de ticks d'horloge.
Le système d'exploitation va ensuite maintenir l'heure en comptant le nombre de secondes depuis une date et heure de référence (par exemple, sous Linux/UNIX, on compte le nombre de secondes depuis le 1ier janvier 1970 00:00 UTC).
Pour synchroniser l'heure, il suffit donc de savoir le nombre de secondes depuis un point de référence.
Le logiciel d'horloge a ensuite pour but de maintenir l'heure, vérifier qu'un processus ne dépasse pas son quantum, compter l'utilisation du CPU, gérer l'appel système alarm, maintenir différentes statistiques, etc.
Par exemple, pour vérifier qu'un processus ne dépasse pas son quantum, le compteur d'horloge est initialisé par le scheduler en fonction du quantum. À chaque interruption, il est diminué et une fois arrivé à zéro le processus est remplacé.
Pour pouvoir gérer plusieurs évènements temporels en même temps, le système met en place une file d'évènements, qui agit comme une sorte d'agenda pour planifier des évènements.
Sécurité
Protection, domaine et matrice d'accès
Lorsque l'on parle de protection, on parle de l'ensemble des mécanismes mis en place pour l'accès, la gestion des ressources systèmes par les processus, etc. Cette protection doit être fournie autant par le système que par les applications.
La sécurité en revanche concerne un spectre plus large incluant les virus, les attaques et la cryptographie.
La protection a pour but de prévenir les violations d'accès et d'améliorer la fiabilité (en détectant des erreurs humaines par exemple).
Si une ressource n'est pas protégée, elle peut être mal utilisée par des utilisateur·ice·s autorisé·e·s (ou non).
Une politique de protection correspond à la définition de ce qui doit être protégé. Tandis qu'un mécanisme de protection indique comment protéger.
Zones de protections
Sur l'ordinateur, il faut pouvoir protéger les processus et les objets.
Les objets peuvent être autant matériel (CPU, mémoire, imprimante, disque, etc) que logiciel (fichiers, programmes, sémaphore, etc).
Pour ce qui est des processus, il faut s'assurer que chaque processus ne peut accéder qu'aux ressources auxquelles il a l'autorisation. Il ne doit accéder qu'aux ressources qui sont nécessaires pour terminer sa tâche.
Domaine de protection
Un domaine définit un ensemble d'objet et de type d'opération qui peut être exécutée sur les objets (la possibilité d'exécuter une action sur un objet s'appelle un droit d'accès).
Un domaine est donc finalement une collection de droits d'accès.
Chaque processus opère à l'intérieur d'un domaine de protection. Les mêmes objets peuvent être référencés dans plusieurs domaines.
Un domaine peut être créé de plusieurs manières (par utilisateur, processus, procédure, etc). Et des opérations pour changer de domaine sont prévues.
L'association entre un processus et un domaine peut être statique (ne change pas, les droits d'accès restent donc tout le temps les mêmes), ou dynamique (les droits d'accès peuvent changer).
Matrice d'accès
La matrice d'accès est une représentation des domaines et de leurs droits d'accès.
C'est un tableau à deux dimensions où chaque ligne représente un domaine (aussi appelé rôle ou sujet), et chaque colonne représente un objet (aussi appelé asset).
Voici un exemple de matrice d'accès :

La matrice d'accès permet de vérifier les politiques de protection voulues. Il faut donc définir les politiques pour chaque objet, assigner chaque domaine à l'exécution d'un processus.
Voyons maintenant quelques droits spécifiques,
Droit au changement de domaine

Pour représenter la permission de changer vers un autre domaine, il suffit de considérer les domaines aussi comme des objets. Ensuite pour permettre à D1 de pouvoir avoir les droits accès de D2, il suffit de mettre switch dans l'intersection de D1 et D2.
Droit à la copie de son droit
Le droit copy permet à un domaine de copier son droit pour un objet donné à un autre domaine.
Ce droit est représenté par une *.

Par exemple, ici, D2 peut copier le droit lecture de F2 sur un autre domaine que le sien.
Il existe aussi une variante du droit copy qui est le droit transfert (ou copie limitée). Si dans l'exemple précédent, il s'agit d'un droit de transfert, alors lorsque D2 passe son droit de lecture de F2 à un autre domaine, il perd le droit de lecture.
Droit à la modification des droits d'un objet
Le droit owner permet à un domaine de modifier n'importe quel droit pour un certain objet.

Dans cet exemple, D1 possède un accès total à F1. De cette manière, D1 peut par exemple s'accorder un droit d'écriture sur F1 ou encore accordé un droit de lecture de F1 à D2.
Droit au contrôle des droits d'un domaine
Le droit control permet à un domaine de supprimer des droits d'accès à un autre domaine.

Dans cet exemple, D2 peut par exemple supprimer le droit d'accès en écriture (F1) de D4.
Sous UNIX (setuid)
Sous UNIX, chaque domaine correspond à un utilisateur·ice, et lorsque qu'un exécutable est lancé, le processus prend le domaine de l'utilisateur·ice qui l'a lancé.
Sauf lorsque le bit setuid est mis. Ce bit est représenté par un s
lorsque l'on regarde les permissions d'un fichier. Lorsque c'est le cas,
l'exécutable va se lancer en tant que l'utilisateur·ice qui possède le
fichier, à la place de s'exécuter en tant qu'utilisateur·ice qui l'a
lancé.
Par exemple, avec le fichier sudo, lorsque l'on fait un ls -l dessus,
on peut voir les permissions à gauche.
-r-s--x--x 1 root root 63432 Jan 6 09:22 /run/wrappers/bin/sudo
On peut voir qu'il y a un s, cela signifie que lorsque j'exécute ce
fichier en tant qu'utilisateur snowcode, le fichier est réellement
exécuté en tant que root.
Implémentation
Utiliser une matrice d'accès dans le système ne serait pas très pratique, car prendrait beaucoup de place et ne pourrait pas être mise en mémoire centrale.
C'est pourquoi, on utilise des access list à la place. L'access list est une liste associée à chaque objet. Elle contient des pairs de domaines et de droits. Un objet dont le domaine n'a pas de droit n'est pas présent sur la liste.
Il est également possible d'étendre la liste avec des droits par défaut (dans quel cas, pour vérifier les droits d'une opération, on vérifie d'abord les droits par défaut avant de rechercher la paire correspondante au domaine).
Révocation des droits
Ensuite, chaque système doit aussi prévoir comment révoquer des droits. Par exemple pour définir si c'est immédiat ou décalé, pour tous les utilisateurs ou seulement certains, si cela est temporaire ou permanent, etc.
Chaque système définit les stratégies possibles et laisse le choix à l'utilisateur·ice.
Sécurité contre les attaques
Nous avons vu comment protéger le système et déterminer les droits d'accès. Maintenant, il faut trouver des mécanismes pour protéger le système contre le vol d'information, la modification/destruction non autorisée d'information et surveiller l'utilisation du système.
Les mécanismes de sécurité ont pour but d'empêcher ou de ralentir le plus possible toute violation du système, il faut que le cout pour pénétrer un système soit plus important que le gain que l'on peut en retirer.
Niveaux de protections
Il y a 4 niveaux de protections différents :
- Physique, protéger le matériel dans des endroits protégés
- Humains, surveillance pour l'accès au matériel
- Réseau, protection adéquate, firewalls, etc
- Système d'exploitation
Dangers d'une attaque
La sécurité est évidemment primordiale, les entreprises stockent toutes leurs informations sur des systèmes informatiques et les informations personnelles valent de l'or. Des informations perdues ou volées peuvent conduire une entreprise à la faillite.
Authentification
Les systèmes actuels ne fonctionnent que lorsque l'utilisateur·ice est authentifié·e.
Nous allons parler ici de plusieurs types d'authentification différents et de quelques bonnes pratiques pour chacun d'entre eux.
Identification par mot de passe
Le mot de passe est une méthode courante d'authentification, cependant elle n'est pas forcément très sûre, notamment, car elle dépend beaucoup de l'utilisateur·ice.
Comment un mot de passe peut être découvert
Un mot de passe peut être volé de plusieurs manières, soit en connaissant l'utilisateur et en devinant le mot de passe (c'est pourquoi il faut que les mots de passes soient aléatoires), ou de façon brutale (par dictionnaire ou énumération).
Il est aussi possible de voler un mot de passe en utilisant un keylogger, c'est-à-dire un programme ou appareil qui va enregistrer toutes les entrées clavier de l'utilisateur·ice.
Un mot de passe peut aussi être sniffé en écoutant tout ce qui se transmet sur le réseau, si le mot de passe n'est pas transféré de manière chiffrée, alors on peut récupérer le mot de passe.
Un mot de passe peut encore être découvert en analysant des bases de données d'anciens mots de passe découvert, car mal stocké par d'autres entreprises. En effet, comme beaucoup d'utilisateur·ice·s ne changent pas de mot de passe, il y a de grandes chances que ce dernier n'ait pas changé.
Enfin, le mot de passe peut encore être découvert à cause d'autres maladresses de l'utilisateur·ice·s, tel que tomber dans une attaque de fishing ou encore l'écrire sur un post-it sur son bureau.
Stockage d'un mot de passe
Si vous voulez en savoir plus sur les dangers et les différentes manières de stocker des mots de passes, regardez cette vidéo.
Plain text
La pire manière de stocker des mots de passes est de juste les stocker en base de donnée. Car lorsque l'on fait cela, ça signifie que toute personne ayant accès à la base de donnée a accès à tous les utilisateurs et mots de passes.
Pire encore, puis ce que les utilisateur·ice·s réutilisent souvent les mêmes mots de passes, pour beaucoup d'entre eux, cela donne accès à l'entièreté de leur vie en ligne.
Chiffré
Une autre manière est de chiffrer les mots de passes. Cela signifie que si quelqu'un a accès à la base de donnée, il ne pourra rien en faire. Cependant, cela signifie aussi que si quelqu'un a accès à la clé de déchiffrement, cette personne a toujours accès à tous les mots de passes. C'est donc également une chose à éviter.
Un autre problème avec cette méthode est que si certains mots de passes sont identiques, on pourra le reconnaitre, car on verra le même mot de passe chiffré dans la base de donnée plusieurs fois.
Hashing
Cette manière consiste à hasher (faire passer à travers une fonction de hashage) les mots de passes.
Une fonction de hashage est une fonction à sens unique, ainsi, on fait passer le mot de passe à l'intérieur, cela génère un texte, mais il est impossible de retrouver le mot de passe à partir du texte.
Ainsi, il suffit de stocker le hash dans la base de donnée, ainsi lorsque l'utilisateur·ice veut se reconnecter, on hash le mot de psase entré et on compare le hash dans la base de donnée avec celui qui vient d'être généré.
Le problème avec cette méthode est que plusieurs utilisateur·ice·s ayant le même mot de passe vont avoir le même hash. Par conséquent, on le saura directement dans la base de donnée.
Il y a notamment une attaque en particulier qui utilise cette faiblesse, c'est la rainbow table attack, à la place d'avoir une liste de mots de passes courants, les hasher et les essayer un par un contre chaque hash (ce qui est une attaque par dictionaire), on va avoir une liste de mots de passes pré-hashé et simplement comparer les hash. Ce qui fait que l'attaque est beaucoup plus rapide, surtout que beaucoup d'algorithmes de hashage sont volontairement lents afin de décourager les attaquants.
Hashing avec salt
Cette méthode est l'une des meilleures méthodes aujourd'hui. Elle consiste à utiliser un salt avec le hash pour se protéger contre les rainbow table attacks.
Un salt est une chaine de caractère aléatoire différente pour chaque utilisateur qui va être ajouté à chaque mot de passe. Le salt est ensuite présent juste à côté du hash en clair.
Donc, lorsqu'un·e utilisateur·ice se connecte, on va aller chercher le salt, l'ajouter à son mot de passe et le hasher. Ensuite, on compare ce hash avec celui dans la base de donnée.
Grâce à cette chaine aléatoire (le salt), les rainbow table attacks sont inutiles, car elles ne peuvent plus comparer les hash.
Cette méthode est d'autant plus puissante lorsqu'elle fonctionne avec des algorithmes de hashage lent, parce que l'attaquant n'a pas d'autre choix que de tester les mots de passe un par un et va perdre beaucoup de temps.
Ne pas stocker de mot de passe
Stocker des mots de passes est une grande responsabilité, il est possible que ce soit plus sûr de ne tout simplement pas les stocker et d'utiliser des mécanismes tel que OAuth pour à la place demander à des tiers de confiance de le gérer pour nous. Par exemple par Google ou Microsoft.
Ou encore d'utiliser des appareils physiques tels qu'une carte électronique ou un appareil FIDO2 (on va en reparler plus tard) à la place ou en plus du mot de passe.
Identification à plusieurs facteurs
Une première manière de faire de l'authentification à plusieurs facteurs est d'utiliser un système de code à usage unique tel que le TOTP. À savoir que certains de ces mécanismes peuvent aussi être utilisés seul, pas seulement en conjonction avec un mot de passe (par exemple une clé FIDO2 pour authentification SSH), on va en reparler dans l'identification password-less.
L'avantage d'utiliser l'identification à plusieurs facteurs est de palier la faiblesse du système de mot de passe en demandant à un autre système de générer un code ou de résoudre un problème (par exemple, envois de SMS, TOTP, hash chain, clé FIDO2, etc).
Hash Chain
Une autre manière de faire est d'utiliser à répétition la fonction de hashage.
Par exemple, on génère une valeur aléatoire de départ (le seed).
Ensuite, on exécute la fonction de hashage un certain nombre de fois (par exemple 1000 fois) sur ce seed, ce qui donne donc un hash de hash de hash de hash de … du seed. Le serveur fait de même et sauvegarde ce hash.
Lors de la première authentification, l'utilisateur·ice génère un code à usage unique en dérivant une fois de mois qu'avant le seed. Dans cet exemple, l'utilisateur va donc hasher le seed 999 fois. Le serveur peut alors vérifier que lorsqu'il hash le seed, il obtient bien le hash de départ, l'authentification est donc réussie. Le serveur défini alors ce nouveau hash (de 999 fois) à la place de l'ancien (de 1000 fois).
Ainsi le processus se répète jusqu'à arriver à zéro où dans quel cas il faut générer un nouveau seed.
TOTP (Time-based One Time Password)
Cette section est en bonus et n'est pas présente dans le cours
En somme, l'utilisateur·ice a un appareil (smartphone, digipass ou autre), qui partage un secret avec le serveur (token) ainsi que le temps (le temps doit être le même que sur le serveur).
Ainsi, après que l'utilisateur·ice a entré son mot de passe, on lui demande le code à usage unique. L'utilisateur·ice peut ensuite demander à l'appareil de générer ce code.
Ce code est généré en hashant le secret partagé (token) et le temps actuel. Ainsi, le mot de passe n'est valable que pour une certaine durée de temps.
En somme, en plus d'ajouter son mot de passe, l'utilisateur·ice va également
FIDO2
Cette section est en bonus et n'est pas présente dans le cours. Vous pouvez en apprendre plus sur FIDO2 en regardant cette vidéo.
Lorsque l'on veut s'enregistrer sur un site internet, la clé FIDO2 va créer une paire de clé (clé privée et clé publique, on va y revenir plus tard).
Une fois la paire de clé générée, la clé publique est envoyée au site avec un "handle", cet handle contient des informations uniques sur le site qui a demandé l'authentification.
Ainsi, lorsque l'on souhaite se connecter, le site va envoyer un message aléatoire à signer à la clé, la clé va ensuite vérifier que le handle correspond bien (que c'est le bon site, donc protection contre le fishing, le bon compte, sur la bonne clé).
Si tout correspond, la clé va signer le challenge envoyé par le site. Le site pourra ensuite vérifier que la signature est correcte avec la clé publique.
Ce mécanisme est donc très simple (uniquement un bouton) et très sécurisé (protection contre le fishing, aucune information personnelle à stocker).
Identification password-less
L'identification password-less repose sur l'idée que les mots de passes sont compliqués à gérer, assez faible et que l'authentification à plusieurs facteurs peut être compliquée.
L'identification password-less repose donc sur d'autres principes tels que la biométrie (empreinte digitale, reconnaissance faciale, etc), sur un code unique (par SMS ou application tierce, voir TOTP plus tôt), par lien magique (envois d'un lien de connexion par mail), par notification push, ou par clé FIDO2 (voir plus tôt) par exemple.
Si vous voulez en savoir plus sur l'authentification password-less, vous pouvez regarder cette vidéo.
Identification biométrique
L'identification biométrique a pour but d'authentifier sur base d'une propriété de l'utilisateur·ice (sa tête, ses doigts, ou autre).
Le scanner converti et numérise la propriété, la donnée numérisée est alors traitée comme un mot de passe et est hashée et salée.
Le problème de cette méthode est que la protection de ces données devient vraiment très critique, contrairement aux mots de passes, on ne peut pas changer sa tête ou ses empreintes digitales.
De plus, ces informations sont aussi des informations très confidentielles qui peuvent aussi avoir un impact politique important.
Sécurité des applications, attaques et logiciels malveillants
Écrire du code exempt d'erreur est difficile, et les erreurs peuvent conduire à des vulnérabilités qui permettent d'attaquer le programme.
L'attaque peut permettre d'obtenir des droits non accordés au départ, faire planter l'application, introduire des données incorrectes, etc.
Attaques courantes
-
Remote Code Execution (RCE), exécution de code à distance en
soumettant une donnée précise à l'application
- Un exemple qui a fait beaucoup de bruit est celui de la vulnérabilité log4shell dans le système de log Java "log4j" qui faisait qu'il était possible d'exécuter du code sur toute application utilisant la librairie. Cette vulnérabilité était si dangereuse qu'elle fut considérée par certains gouvernements comme l'un des problèmes de sécurité informatique la plus sérieuse des 20 dernières années.
- SQL Injection, injection de code SQL dans la base de donnée en soumettant des données précises.
- Format String vulnerabilities qui consiste à soumettre du code qui est compris comme une commande par l'application. Pour en savoir plus, des exemples de code en C sont donnés dans cet article.
- Cross-Site Scripting (XSS), qui est encore dû à une non-vérification des soumissions de l'utilisateur·ice qui peut mener à intégrer du code HTML dans une page. Ce qui signifie que l'on peut aussi injecter du code JavaScript dans la page qui seront exécutés par tous les visiteurs de celle-ci.
-
Username enumeration, si le système mentionne que le nom
d'utilisateur est introuvable, il est possible de tester plusieurs
noms d'utilisateurs pour savoir lesquels sont présents sur le système.
Il est parfois aussi possible de faire cela via l'API du site (genre
en regardant
/api/user/01et les énumérer comme ça). - Stack/buffer overflow, l'attaquant soumet une chaine de caractère spécifique qui provoque un débordement de la pile. Grâce à ce débordement, le code exécuté devient celui de l'attaquant, cela peut donc lui faire prendre le contrôle du code de l'application, et si l'application s'exécute dans le domaine administrateur, lui faire devenir administrateur (privilege escalation).

-
Déni de service (DoS), le fait de rendre inaccessible un système
en le bombardant de requêtes. Le système devient ainsi inaccessible
durant le temps de l'attaque, bien qu'aucun dommage ne soit opéré,
cela cause un problème en terme l'image pour l'entreprise et peut lui
faire perdre de l'argent à cause de l'inaccessibilité du site.
- Si une attaque DoS est fait depuis plein d'ordinateurs différents (ce qui fait qu'elle est plus compliquée à arrêter), on parle d'attaque de déni de service distribuée (DDoS). Chaque ordinateur est appelé un zombie et l'ensemble des ordinateurs infectés utilisé est appelé un botnet.
Programmes malveillants
Maintenant, on va parler de types de programmes malicieux,
- Cheval de troie (ou trojan), est un programme qui se fait passer pour ce qu'il n'est pas pour déclencher une action hostile. Cela peut par exemple être un faux anti-virus.
-
Backdoor (porte dérobée), le programme installe une porte d'accès
à l'utilisateur, il est ainsi possible de faire exécuter des commandes
à la machine à distance.
- C'est une méthode assez utilisée pour constituer des attaques DDoS, car la machine devient un zombie qui fait partie d'un botnet auquel l'attaquant demande de faire des requêtes à répétition sur un site.
- Cette méthode peut aussi être utilisée pour installer un cryptomineur qui va miner des cryptomonnaies pour l'attaquant sur toutes les machines victimes
- Les vers informatiques (ou WORMS) sont des programmes qui se
propagent par les réseaux informatiques. Les vers utilisent des
vulnérabilités d'autres systèmes pour se propager, ainsi chaque
machine infectée infecte les autres machines du réseau à son tour.
- Un exemple très connu de WORM est celui de WannaCry, un ransomware qui a infecté plus de 300000 ordinateurs sur plus de 150 pays différents et qui aurait causé des pertes de l'ordre de plusieurs centaines de millions de dollars. Ce WORM se propageait via une vulnérabilité dans un port de communication du système Windows.
- Les virus informatiques sont des ensembles d'instructions qui
utilisent un programme pour se reproduire. Ainsi, comme un virus
biologique, un virus informatique a pour principal but de se
reproduire en infectant un programme hôte. Certains virus ont
également une charge active qui attaque le programme à un moment
déterminé. Certains virus utilisent des techniques avancées pour se
cacher des systèmes de protection.
- Les virus script sont des virus écrit dans un langage interprété (par exemple le VBA, langage de programmation de Microsoft Office), le virus utilise un environnement tiers pour s'exécuter et se reproduire. Cela peut par exemple être sous la forme d'une macro d'un document Microsoft Office.

Protection contre les attaques
Pour se protéger contre des attaques, il est important de protéger le périmètre (tout ce qui est vers l'extérieur, tel que le réseau), en installant un firewall au niveau du réseau.
Ensuite, il est aussi important de protéger les machines en installant un firewall personnel et un anti-virus.
D'autres choses sont importantes telles que ne jamais travailler avec un compte administrateur.
Sécurité d'un parc informatique
Pour assurer la sécurité d'un parc informatique, on peut utiliser des scanners de vulnérabilités, ce sont des programmes qui vont regarder si le système est vulnérable à certaines attaques afin de pouvoir mettre à jour les composants qui en ont besoin.
Il faut aussi pouvoir assurer l'intégrité des programmes, on peut donc garder de manière sécurisée les empreintes de tous les programmes et vérifier celles-ci lors de leur lancement. Le seul souci, c'est qu'il faut tenir compte des mises à jour.
On peut aussi utiliser un système de détection d’intrusion (IDS), c'est un programme qui tente de repérer des activités anormales sur un système en se basant sur des plans d'attaque connus, en observant l'activité et les journaux systèmes.
Par exemple, fail2ban est un IDS qui bannit les adresses IP qui
réalisent un certain nombre de tentatives de connexions illicites.
Un IDS peut aussi analyser le comportement de l'utilisateur pour
détecter des comportements anormaux (exemple un secrétaire qui compile
un logiciel). Il faut cependant faire attention à configurer l'IDS
correctement pour éviter les faux positifs. Un autre exemple d'IDS est
Snort
Enfin, un denier élément important est l'analyse de fichiers journaux. Tous les systèmes d'exploitation consignent des informations sur ce qu'il se passe sur le système, on peut donc utiliser des outils pour analyser automatiquement ces fichiers journaux tel que Splunk, Grafana Loki ou encore Crowdsec.
Introduction et histoire de la cryptographie
La cryptographie consiste à cacher des informations en utilisant des algorithmes. Il ne faut pas le confondre avec la stéganographie qui consiste à cacher des messages dans d'autres messages.
Par exemple, si on prend un message tel que BONJOUR (texte en
clair), et que pour chaque lettre, on la décale d'un certain nombre de
positions dans l'alphabet (processus de chiffrement), ici, on va
choisir 13 positions, (13 sera ici la clé de chiffrement), on
obtient OBAWBHE qui est notre cryptogramme (message chiffré).
Pour déchiffrer le message, il suffit alors de faire le processus
inverse, ce processus inverse est donc le processus de déchiffrement
qui retournera BONJOUR (notre texte en clair).

Histoire
La cryptographie est utilisée depuis très longtemps par les militaires, diplomates et amants.
Avant l'avènement de l'informatique, la cryptographie était limitée aux capacités du cerveau humain, il fallait pouvoir changer de méthode de chiffrement si quelqu'un se faisait prendre.
Avec l'avènement de l'informatique est venu la capacité de calculer des résultats beaucoup plus complexe.
Substitution et transposition
La substitution et la transposition sont deux méthodes historiques de sécurisation des données. Ces méthodes ne devraient plus être utilisées aujourd'hui pour protéger des données.
En sécurité, il n'y a rien de pire que d'avoir l'illusion qu'on est protégé
Substitution
La substitution est un mécanisme par lequel chaque caractère du texte clair est remplacé par un autre caractère dans le texte chiffré. Cela signifie qu'on a une table de correspondance de chiffres, sons, mots ou autre à quelque chose. C'est par exemple le cas du code de césar dont nous avons parlé juste avant.
Voici, par exemple, la table de substitution du ROT13, qui est un code de César auquel la clé est à 13.

Le problème avec ce système est que l'on peut utiliser la linguistique et un contexte pour supposer la présence de certains mots ou la fréquence de certaines lettres.
Par exemple, si on sait que le texte est rédigé en français, on peut compter la lettre qui revient le plus souvent, supposer que c'est un E et compter la différence entre la lettre du cryptogramme et la lettre E pour obtenir la clé.
Transposition
La transposition consiste à mélanger les lettres d'une certaine manière.

Ici par exemple, on commence par mettre le texte dans une grille, puis on ajoute un premier mot clé au-dessus et on trie les colonnes par ordre alphabétique de la clé.
Ensuite, on transforme les colonnes en lignes et on met un deuxième mot clé au-dessus. On peut ensuite procéder de la même manière en triant les colonnes par ordre alphabétique de la clé. Le résultat de la grille donne donc le cryptogramme final.
Le problème avec cette méthode est similaire à celui de la substitution, on peut faire des inversions et tenter d'identifier des mots.
XOR (ou exclusif)
Le XOR est une opération de base du CPU, ce qui la rend très rapide.
L'idée ici est de faire une opération XOR entre un texte en clair et une clé de chiffrement. De la même manière, on peut déchiffrer le texte en faisant le cryptogramme XOR la clé.
Par exemple, si le message en clair est la lettre A, on convertit cela
en binaire, ce qui donne 00001010. Si notre clé est la lettre H que
l'on convertit en binaire 01001000. On peut faire un XOR dessus pour
obtenir le cryptogramme :
00001010 => A (texte en clair)
XOR 01001000 => H (clé)
--------
01000010 => B (cryptogramme)
Maintenant pour déchiffrer, il suffit de prendre le cryptogramme et la clé et de refaire un XOR
01000010 => B (cryptogramme)
XOR 01001000 => H (clé)
--------
00001010 => A (texte en clair)
Le problème avec cette méthode est que si on connait un exemple dans lequel on a à la fois le texte clair et le cryptogramme, on peut retrouver la clé en utilisant le même mécanisme.
De la même manière, on peut facilement trouver la clé en faisant de l'analyse par fréquence sur base de la longueur de la clé.
Cependant, si la clé est complètement aléatoire et de la même longueur que le message, il s'agit alors d'un "one-time pad" ou "masque jetable" et c'est théoriquement un code incassable.
Masque jetable
Un masque jetable est une technique de chiffrement se basant sur une longue liste non répétitive et aléatoire de lettres (le masque). Chaque lettre est utilisée pour code une lettre du texte clair.
Par exemple, on peut additionner le rang de la lettre du masque avec celui du texte clair modulo 26 pour obtenir le rang de la lettre du texte chiffré.
Ou alors, on peut procéder en utilisant un XOR comme précédemment.
Puis ce que la clé est de la même longueur que le message et qu'elle est entièrement aléatoire, il est impossible de la déchiffrer. Cependant, cette technique a le gros désavantage d'avoir des clés très longues et peu pratiques.
Niveaux de chiffrements
Le niveau de chiffrement sera établi en fonction des groupes de personne contre lesquels on désire se protéger. Le niveau sera différent si on souhaite se protéger contre ses concurrents ou de la NSA.
C'est également une question de longueur de clé. Plus la clé est longue, plus ce sera sécurisé. Par exemple, un cadenas à trois chiffres aura 1 000 combinaisons possibles tandis qu'un cadenas à six chiffres aura 1 000 000 combinaisons possibles.
Algorithme comme garant de la sécurité
L'algorithme qui est utilisé pour faire de la cryptographie est le garant (avec la ou les clés) de la sécurité des messages.
Un bon algorithme doit être public (pour être vérifiable), sûr (éprouvé pendant plusieurs années et par des experts) et indépendant (sans coopération avec des organismes ayant des intérêts contradictoires tels que la NSA).
Dans un algorithme sûr, que l'espion ne soit qu'avec du texte chiffré, avec des correspondances texte en clair et texte chiffré ou même avec du texte clair choisi, l'espion ne peut pas trouver la clé.
Cryptographie symétrique et asymétrique
Entre les deux extrêmes que nous venons de voir (code de césar d'un côté et le one-time pad). Divers mécanismes ont été développés.
Crypto système à clé secrète (cryptographie symétrique)
Une clé secrète est partagée entre toutes les personnes qui doivent communiquer.
Les systèmes historiques correspondent à cette catégorie, mais aujourd'hui, on a également des manières plus sécurisées telles que AES.
Bien que ce crypto système ait été le standard pendant plusieurs siècles, il a quelques problèmes.
Par exemple, les clés doivent être distribuées et rester sûr, si la clé est compromise, tous les messages sont compromis. Et si une clé différente est utilisée par paire d'utilisateur, le nombre de clés nécessaires pour rester sûre devient très élevé.
Crypto système à clé publique (cryptographie asymétrique)
À la place d'avoir une clé secrète partagée par tout le monde, on va avoir une clé qui ne peut faire que du chiffrement (la clé publique), et une clé de déchiffrement (la clé privée).
La clé publique, comme son nom l'indique, peut être partagée partout. De cette manière, si on veut communiquer avec 100 personnes, à la place d'avoir 100 clés, on va avoir une seule clé publique partagée partout.
N'importe qui peut chiffrer un message avec cette clé publique, mais seule la clé privée pourra permettre de la déchiffrer.
Cela règle donc les problèmes de la cryptographie asymétrique, cependant ce système a le désavantage d'être beaucoup plus lourd et de demander beaucoup de calcul (ce qui est la raison pour laquelle il est si récent).
Il reste tout de même un problème, celui de la confiance. Comment pouvons-nous être sûrs que la personne qui donne la clé privée est bien qui elle prétend être ?
Pour cela, on peut utiliser des tiers de confiance déjà connus à l'avance qui pourront certifier des clés (c'est par exemple le cas de l'entreprise Let's Encrypt qui permet de certifier les clés TLS pour le HTTPS).
RSA
Pour apprendre et comprendre le fonctionnement de RSA, allez voir cette playlist, pour avoir des détails sur le calcul uniquement, vous pouvez consulter cette vidéo et si vous voulez utiliser quelque chose de plus simple que l'algorithme d'Euclide étendu, vous pouvez utiliser le théorème de Bachet-Bézout à la place.
Voici comment calculer les clés publiques et privées en RSA,
- Tout d'abord, on choisit deux nombres premiers, que l'on va appeler $ p $ et $ q $. Par exemple $ p = 3 $ et $ q = 5 $.
- Ensuite, on fait le produit de ces deux nombres, que l'on va appeler $ n $, soit $ n = pq = 3 * 5 = 15 $
- Ensuite, on calcule la fonction phi tel que $ \Phi (n) = (p - 1)(q - 1) = (3 - 1)(5 - 1) = 2 * 4 = 8$
- Ensuite, on choisit un entier $ e $ dont le PGCD avec $ \Phi (n) $ vaut 1; autrement dit, il faut trouver un nombre $ e $ tel que $ e $ et $ \Phi (n) $ soient premiers entre eux (aucun facteurs premiers communs)
- Enfin, il faut trouver le nombre de déchiffrement $ d $ tel que
$ ed \mod \Phi (n) = 1 $, soit $ ed - kn = 1 $.
- On peut ici utiliser le théorème de Bachet-Bézout qui dit que si deux nombres ($ a $ et $ b $) sont premiers entre eux, alors on peut trouver des entiers $ x $ et $ y $ tel que $ ax + by = 1$. Ici, on a $ e $ et $ \Phi (n) $ qui sont premiers entre eux, par conséquent on peut appliquer l'algorithme. En considérant $ x $ comme étant $ d $ et $ y $ comme étant $ k $. Note: si la valeur de d est négative on peut faire $ d + \Phi (n) $ pour avoir une valeur positive utilisable.
- La clé publique est $ { e, n } $ et la clé privée est $ { d, n }$.
On peut donc maintenant chiffrer un message $ m $ (qui doit être inférieur à $ n $) en faisant $ m^e \mod n = c $. Et on peut déchiffrer un message en faisant $ c^d \mod n = m $. $
De même on peut signer un message en "déchiffrant" un texte en clair, $ m^d \mod n = s $ et on peut le vérifier en "chiffrant" la signature, $ s^e \mod n = m $.
Les chapitres ci-dessous sont optionnels pour le cours, mais aident à mieux comprendre le fonctionnement de RSA.
Exponentiation modulaire
Pour pouvoir avoir une clé pour déchiffrer et une clé pour chiffrer, il faut pouvoir trouver un moyen de faire une opération facilement (chiffrement avec clé secrète) mais de rendre l'opération inverse très compliquée (déchiffrement) si on ne connait pas une valeur supplémentaire (clé privée).
Cette fonction pour RSA c'est l'exponentiation modulaire, l'idée est que si on fait $ m^e \mod n = c $, cela demande beaucoup d'essai-erreur pour pouvoir en partant de e, n et c revenir à m.
Cependant, si on a un autre exposant (d) on peut l'inverser simplement en faisant $ c^d \mod n = m $.
Si on applique e et d ne même temps, le message ne change donc pas, ainsi $ m^{ed} \mod n = m $, cela sera important pour plus tard.
Factorisation de nombres premiers
Maintenant, il faut trouver un moyen de trouver e, d et n de manière à rendre tout cela possible. Pour cela, il faut trouver une autre fonction qui simple à faire dans un sens et compliquée à faire dans l'autre.
Cette fonction dans RSA c'est la factorisation de nombres premiers (pour rappel, un nombre premier est un nombre qui ne peut être divisé entièrement que par un ou lui-même). On sait que tous les nombres ont exactement une factorisation de nombres premiers, cependant, cette factorisation de plus en plus compliquée en fonction de la grandeur du nombre.
Cette propriété fait que la factorisation est un très bon candidat, car si on utilise des nombres premiers assez grands, il sera impossible de le factoriser avec nos moyens actuels.
Ainsi, on peut trouver deux nombres premiers très grands et les multiplier ensemble. Le produit de ces deux nombres premier sera très simple à calculer, mais très difficile à inverser parce que la multiplication est simple, mais la factorisation est elle très complexe.
Maintenant, il faut trouver une fonction qui dépend de la connaissance de la factorisation de n.
Indicatrice d'Euler, fonction Phi
Cette fonction, c'est indicatrice d'Euler que l'on va ici appeler phi. Ainsi la fonction $ \Phi (n) $ donne le nombre d'entiers positifs plus petit que $ n $ qui ne partagent pas de facteurs premiers avec $ n $. Par exemple $ \Phi (8) = 4 $ car huit ne partagent pas de facteurs communs avec 1, 3, 5 et 7, mais partagent des facteurs communs avec 2, 4 et 6.
Cette fonction est donc très compliquée à calculer pour des grands nombres, mais vraiment simple à calculer pour des nombres premiers. Puisqu'un nombre premier ne peut être divisé que par 1 ou lui-même, la fonction phi revient à dire $ \Phi (n) = n - 1 $.
De même la fonction est multiplicative, donc si $ a $ et $ b $ sont premiers, $ \Phi (a*b) = (a-1)(a-1) $.
Il faut maintenant trouver un moyen de lier la fonction phi à l'exponentiation modulaire.
Théorème d'Euler
le théorème d'Euler indique que $ a^{\Phi (n)} \mod n = 1 $ si a et $ \Phi (n) $ sont premiers entre eux.
On sait qu'un exposant peut être multiplié par n'importe quel nombre car cela ne changera pas le résultat du modulo. Donc $ a^{k \Phi (n)} \mod n = 1$ est vrai également. Une autre propriété est que si on incrémente l'exposant, alors cela devient $ a^{k \Phi (n) + 1 \mod n = a $.
Cela donne donc une forme similaire à $ m^{ed} \mod n = m $. On peut donc en déduire que $ ed = k \Phi (n) + 1 $, que l'on peut reformuler sous la forme $ 1 = ed + k \Phi (n) $, ou $ 1 = ed \mod \Phi (n) $.
Il suffit alors de trouver une valeur e qui soit premier avec $ \Phi (n) $ et trouver d en utilisant l'algorithme d'Euclide étendu ou le théorème de Bachet-Bezou.
Signatures cryptographiques
Une signature permet d'identifier que quelqu'un a bien écrit quelque chose. Une signature doit être authentique, non falsifiable, non réutilisable. De même, un document signé ne peut pas être modifié et une signature ne peut pas être reniée.
Il faut pouvoir faire toutes ces propriétés dans les signatures numériques (cryptographiques).
Avec de la cryptographie symétrique
Pour faire un système de signature avec une seule clé secrète, il faut trois acteurs, le signataire, le destinataire et un tiers de confiance. C'est le tiers de confiance qui donne toute sa sécurité à la structure.
Chaque acteur partage une clé avec le tiers de confiance. Ainsi lorsque le signataire va partager le document avec sa clé au tiers de confiance.
Le tiers de confiance peut donc confirmer la signature puisque qu'il connait la clé secrète. Le tiers de confiance peut donc ajouter une certification sur le document et le signer en utilisant la clé partagée avec le destinataire.
Le destinataire peut donc ensuite valider que le tiers de confiance a authentifié la signature et donc considérer la signature comme correcte, car le tiers de confiance a utilisé sa clé.
Le problème ici est que toute la sécurité du système réside dans le tiers de confiance, donc si le tiers de confiance est compromis, toutes les signatures sont compromises.
Avec de la cryptographie asymétrique
Avec de la cryptographie asymétrique, on a uniquement besoin du signataire et du destinataire. Le destinataire connait la clé publique du signataire. Le rôle d'un potentiel tiers de confiance ici est seulement d'authentifier le propriétaire de la clé (cela n'a donc besoin d'être fait qu'une seule fois).
Nous avons vu que lorsque quelque chose est chiffré avec une clé publique, seule la clé privée peut la déchiffrer. Mais à l'inverse, lorsque quelque chose est signé avec une clé privée, elle peut être validée par les clés publiques.
La procédure de signature équivaut globalement à appliquer l'algorithme de déchiffrement sur le texte à signer. Ainsi, il suffira au destinataire de chiffrer le résultat pour retrouver le texte d'origine.
Systèmes de confiances
Certificats numériques X509
Les certificats numériques x509 lient une clé publique à une identité (nom de domaine, adresse email, etc) en utilisant une signature cryptographique.
Toute personne faisant confiance au tiers connait la clé publique de ce dernier afin de pouvoir vérifier les certificats. C'est notamment cela qui est utilisé sur internet pour vérifier les connexions HTTPS. Le navigateur possède une liste de clés publiques de tiers de confiances pour vérifier les certificats.
Certains tiers de confiances offrent leurs services de vérification gratuitement, c'est par exemple le cas de "Let's Encrypt", cependant la vaste majorité sont payants, mais ont l'avantage d'offrir une vérification beaucoup plus rigoureuse.
Let's Encrypt ne fait que vérifier que la demande de certificat est bien faite depuis une machine sous le nom de domaine demandé, alors que d'autres tiers de confiance vont aller se renseigner sur l'entreprise et l'appeler pour avoir une confirmation de l'authenticité de la demande.
Système de PGP (Pretty Goog Privacy)
C'est un système à clé publique sans tiers de confiance. L'identité des personnes est garantie de manière transitive.
Ainsi, si Alice connait Bob, elle peut certifier sa clé publique en la signant. Bob peut alors partager la clé signée par Alice. De cette manière, toute personne faisant confiance aux fréquentations d'Alice pourra faire confiance à Bob en vérifiant la signature.
Résumé global
Question 1 (processus)
Définissez le concept de processus, décrivez les mécanismes de communication entre les processus et détaillez les algorithmes de CPU scheduling
Définition du concept de processus
Un processus est un programme en cours d'exécution. Il comporte le code du programme, le program counter (qui indique à quel instruction du programme, on est et quelle est la suivante), la pile et les données du programme.
La création d'un nouveau processus est faite via l'appel système fork
Un processus est caractérisé par :
- Un PID, identifiant du processus
- Un PPID (l'identifiant du processus père qui a créé le processus actuel)
- La priorité du processus
- Le temps consommé au CPU
- La table des fichiers ouverts
- L'état du processus
Voici les différents états des processus et leurs relations :

- new, correspond à un programme qui a été sélectionné pour être démarré. Ses instructions ont été copiées en mémoire, mais son contexte d'exécution et ses détails n'ont pas encore été préparés.
- ready, le processus a été créé et dispose de toutes les ressources pour effectuer ses opérations
- running, le processus a été choisi par le scheduler pour tourner. Il va s'exécuter jusqu'à écoulement du temps imparti ou qu'un processus de plus haute priorité arrive, dans quel cas il retourne en ready. S'il demande des ressources, il ira en état waiting et s'il a fini son exécution ou qu'il est tué, il ira en état terminated.
- waiting, le processus est en état d'attente d'un évènement (par exemple, appui d'un bouton) ou de ressources (par exemple, lecture d'un fichier).
- terminated, une fois le processus terminé ou tué, il libère la totalité des ressources qu'il a détenues.
Pour pouvoir exécuter plusieurs processus et donner l'impression que les processus s'exécute simultanément, le scheduler (un élément du système) va alterner très vite entre les différents états de chaque processus.
Le scheduler va classifier les processus selon s'ils sont des processus de calcul (CPU) ou des processus d'entrée-sortie. Il va toujours privilégier les processus d'entrée sortie, car ce sont eux qui donnent l'interactivité du système et qui donne l'illusion que tout s'exécute en même temps.
Pour changer de processus, le système va sauvegarder le contexte (les données) du processus en cours. Puis charger le contexte du processus à exécuter.
Différents algorithmes de CPU scheduling
Le scheduler a pour but de maximiser l'utilisation du CPU pour avoir un débit (nombre de processus terminé par unité de temps) le plus important possible.
C'est pour cela que le scheduler doit utiliser un algorithme pour pouvoir choisir quels processus lancer afin de maximiser l'utilisation CPU.
Comme algorithmes, on a par exemple,
- FCFS, First Come First Served, premier arrivé, premier servi. Simple à implémenter, mais si un des premiers processus est lent, toute la file est ralentie.
- SJF, Shortest-Job First, ordonne les processus selon leur durée pour mettre les processus les plus rapides au début. Cet algorithme est seulement possible si on sait à l'avance la durée des processus, ce qui est rarement le cas aujourd'hui.
-
Priorité, trie les processus par ordre de priorité, ainsi les
processus de plus haute priorité seront exécutés avant. De plus, cet
algorithme peut aussi être préemptif, donc si un processus de plus
haute priorité arrive, le processus en cours peut être mis en état
ready (mis en pause) pour lui laisser place. Cependant, cela peut
mener à de la famine parmi les basses-priorité si des processus de
plus haute priorité arrivent tout le temps.
- Le problème de famine peut être résolu en combinant l'age et la priorité, ainsi les processus ayant trop attendu passe devant
-
Round-Robin Scheduling, Tourniquet, les processus sont servis dans
l'ordre d'arrivée, chaque processus reçoit le CPU pour un temps
déterminé (quantum). Lorsque qu'un processus épuise son quantum,
il est remplacé (c'est donc préemptif).
- Il faut toute fois faire attention, si le quantum est trop grand cela donnera une impression de lenteur et de lag à l'utilisateur
- En revanche, si le quantum est trop petit, cela diminue l'efficacité du CPU à cause des changements de processus à répétition
- Mutlilevel Queue Scheduling, avoir des files différentes suivant la nature du processus. Une priorité et un mécanisme de scheduling propre est attaché à chaque file.
- Multilevel Feedback Queue Scheduling, comme le précédent, sauf que les processus n'appartiennent plus à une file et peuvent migrer vers d'autres files. Chaque file possède des caractéristiques spéciales (quantum, algorithme, etc).
Description des mécanismes de communication entre les processus
Il est nécessaire que les processus puissent communiquer entre eux pour se partager des informations, répartir les calculs, etc.
La communication inter-process (IPC) représente les mécanismes de communication entre les processus.
Voici différentes options,
- Par fichiers, cependant, cela est très lent et difficile à synchroniser
- Par tubes, qui sont des petits fichiers gérés en file circulaire
qui sont souvent mis en cache (ce qui les rend donc très efficaces),
si le fichier devient trop grand, on peut alors le découper en blocs.
- Les tubes non-nommés sont des tubes temporaires tels que
stdin,stdoutoustderr. Il est possible de rediriger les différents tubes. Les tubes non-nommés sont liés entre père et fils. - Les tubes nommés sont permanents via des fichiers spéciaux sur le système. Les tubes nommés ne sont pas liés entre père et fils et peuvent être utilisé par des processus complètements indépendants.
- Les tubes non-nommés sont des tubes temporaires tels que
- La mémoire partagée est un moyen très commun pour partager des
informations. Il s'agit d'une zone mémoire commune à plusieurs
processus, la taille est entièrement configurable (comme avec
malloc) et après unforkle processus fils hérite de la zone mémoire partagée.- Lorsque l'on alloue une zone de mémoire partagée via
shmget, on lui indique une clé (identifiant de la zone), une taille en octet et les permissions de la zone. - Une fois allouée, on peut récupérer un pointeur vers la zone de
mémoire avec
shmatauquel on passe l'identifiant retourné parshmget, l'addresse dans la zone (généralement 0), et des flags tel que read only (souvent NULL). - Une fois qu'on a terminé, on peut ensuite détacher la zone mémoire
avec
shmdtet éventuellement la supprimer avecshmctl
- Lorsque l'on alloue une zone de mémoire partagée via
Question 2 (processus)
Détaillez les problèmes de synchronisation entre processus, définissez et détaillez le fonctionnement des threads et le problème et les solutions à un interblocage
Les problèmes de synchronisation entre processus
Lorsque plusieurs processus coopèrent, ils doivent fréquemment interagir entre eux et ils doivent parfois attendre qu'une opération soit effectuée par un autre processus pour travailler. Lorsqu'un processus attend un autre, on parle de point de synchronisation.
C'est pourquoi il faut avoir des mécanismes pour envoyer et attendre des évènements, des processus.
Sous UNIX les deux mécanismes les plus importants sont les signaux
(évènements capturés par un processus permettant de signaler aux
processus une erreur tel que SIGINT pour un CTRL+C par l'utilisateur
dans le terminal) et les sémaphores.
Un sémaphore est une variable entière en mémoire qui n'est accédée qu'au
moyen de fonction atomiques p() et v(). La fonction p va attendre
que la valeur soit plus grande que 0 pour la remettre à zéro et
continuer. Et la fonction v va incrémenter la variable, ce qui va
réveiller tous les processus qui l'attendait.
Section critique
La communication entre processus pose également d'autres problèmes, par exemple pour la modification d'une donnée commune comme de la mémoire partagée par exemple. Pour résoudre cela, il faut mettre en place des sections critiques, il s'agit d'un ensemble d'instructions qui doivent être exécutées du début à la fin sans interruption. Cela assure donc que la donnée n'est pas modifiée en cours de route et que les données ne deviennent pas incohérentes.
Pour faire une section critique, on peut,
- Utiliser une variable partagée ainsi, on attend que la variable
soit à 0, lorsqu'elle est à 0, on la met à 1, on fait la section
critique et on la remet à 0.
- Le problème avec cette méthode est qu'elle n'est pas fiable, dans le
cas où le processus se ferrait mettre en pause entre le
while(attente) et la mise de la variable à 1. De plus cette méthode utilise du CPU pour rien pour faire unwhile
- Le problème avec cette méthode est qu'elle n'est pas fiable, dans le
cas où le processus se ferrait mettre en pause entre le
- Utiliser une méthode par alternance, on associe chaque processus à
un tour, ainsi le processus un va attendre que le tour soit à 0, et
l'autre va attendre que le tour soit à 1. Ensuite, ils font leur
section critique et inverse la variable.
- Cette méthode ne souffre pas du problème de fiabilité précédent,
cependant elle est beaucoup plus compliquée à gérer, surtout s'il y
a plus de deux processus à synchroniser. Aussi, elle consomme
également du temps CPU pour juste un
while
- Cette méthode ne souffre pas du problème de fiabilité précédent,
cependant elle est beaucoup plus compliquée à gérer, surtout s'il y
a plus de deux processus à synchroniser. Aussi, elle consomme
également du temps CPU pour juste un
- Synchronisation par fichier, consiste à créer un fichier (lock
file) en mode exclusif (donc un seul processus peut y accéder), donc
on tente de créer le fichier (jusqu'à ce que ça fonctionne), on fait
la section critique et on supprime le fichier.
- Cela a cependant l'inconvénient d'être fortement ralenti par le système de fichier, car pour chaque tentative d'accès au fichier, le processus doit être mis en état waiting, ready puis de nouveau running.
- Synchronisation hardware, consiste à utiliser des instructions
assembleurs pour protéger une section critique. Lorsque l'on veut
entrer dans une section critique, on inverse une variable booléenne
"lock", si elle était initialement à true, on attend et on recommence
l'opération en boucle. Si elle était initialement à false, on entre en
section critique. Une fois la section critique finie, on remet à
false.
- Cette technique est utilisée par le système d'exploitation pour
implémenter certains mécanismes de protection comme les sémaphores.
Cependant, elle a quand même le désavantage du
whilecité précédemment.
- Cette technique est utilisée par le système d'exploitation pour
implémenter certains mécanismes de protection comme les sémaphores.
Cependant, elle a quand même le désavantage du
- Synchronisation par sémaphore, cette méthode de synchronisation est celle à priviléger, avant d'entrer en section critique, on attend sur le sémaphore correspondant à l'autre processus. Ensuite, on fait la section critique et une fois fini, on met notre propre sémaphore à 1 pour indiquer à l'autre processus qu'il peut y aller.
Fonctionnement des threads
Un thread est une sorte de mini-processus, chaque processus peut avoir plusieurs files d'exécutions (il est alors multithreads). L'avantage d'un thread est que c'est beaucoup plus rapide et léger à créer qu'un processus complet. On peut par exemple avoir un thread pour la saisie de texte, un thread pour l'affichage et un thread pour la vérification.
De plus, les threads d'un même processus partagent les informations et un système à plusieurs cœurs peut exécuter les threads d'un même processus sur plusieurs cœurs différents pour améliorer les performances.
Les threads peuvent être implémentés à deux niveaux, au niveau noyau (kernel) où il est alors pris nativement en charge par le SE, ou au niveau utilisateur où il doit alors être supporté au travers de libraires externes.
Les threads peuvent donc être implémentés selon plusieurs modèles :
- many-to-one, soit entièrement en espace utilisateur avec des libraires externes. Le SE ne voit alors que le processus. La création de thread sous ce modèle est rapide, mais le scheduler du système ne peut pas bien optimiser les performances. Donc si un thread fait une activité bloquante, cela risque d'empêcher tous les autres threads de travailler. Ce modèle n'est plus adapté aux CPU multicœurs.
- one-to-one, soit tout en espace kernel. Les threads sont complètement gérés au niveau du SE. Le scheduling est donc plus avantageux et est tout à fait compatible avec les CPU multicœurs. Cependant, ce modèle est couteux pour le SE qui doit tout gérer. C'est par exemple ce modèle qui est utilisé sous Linux.
- many-to-many, soit l'utilisation d'un pool de threads auquel les threads utilisateurs sont assignés à la volée. Cela combine les avantages des deux modèles précédents, cependant il est assez complexe et le SE doit avoir été construit autour de ce modèle.
Il y a également quelques problèmes à considérer avec les threads. Par exemple, que se passe-t-il lors d'un fork ou d'un execl ? faut-il dupliquer tous les threads ? Faut-il écraser les threads ?
Ou encore pour terminer un thread, faut-il qu'un thread demande la terminaison d'un autre (libération asynchrone) ? Ou alors chaque thread vérifie lui-même s'il doit continuer (libération différée) ?
Lorsqu'un signal est envoyé au processus, quel thread doit le recevoir ? Tous certains ou un seul ?
Toutes ces décisions dépendent beaucoup de l'OS utilisé.
Problème et solutions d'interblocages
Les ressources (mémoire, périphérique, CPU, etc) sont limitées, il faut donc gérer les ressources de manière efficace pour permettre au plus grand nombre de processus de s'exécuter.
Cependant, un interblocage peut survenir si un processus détient une ressource A qui est demandée par un autre processus détenant une ressource B qui est elle-même demandée par le premier processus.
Pour empêcher un interblocage, il faut pouvoir empêcher au moins une de ses conditions :
- L'exclusion mutuelle, lorsque les processus utilisent des ressources non partageables. On ne peut pas empêcher cela.
- La détention et l'attente, lorsqu'un processus détient une
ressource et demande une autre ressource en même temps. Pour empêcher
cela, il faudrait
- Soit, que les processus demandent toutes les ressources dès le départ. Seulement, on ne connait généralement pas cette information.
- Soit, dès qu'un processus demande une nouvelle ressource, il doit libérer toutes les autres puis toutes les récupérer en plus de la ressource demandée. Cependant, cela peut mener à l'accumulation de ressources qui peut mener à une famine parmi les autres processus.
- L'impossibilité de réquisitionner une ressource, il est impossible de réquisitionner une ressource, car on ne peut pas savoir si elle sera dans un état cohérent quand elle sera réquisitionnée.
- L'attente circulaire, on peut détecter un cycle d'attente et si un cycle survient faire certaines actions.
Pour éviter complètement l'attente circulaire, il faut savoir la quantité de ressources disponibles et occupées ainsi que les besoins de chaque processus. Le système est dit en état sûr s'il est capable de satisfaire tous les processus. Tant que le système évolue d'état sûr en état sûr, on est sûr qu'un interblocage ne surviendra.
Utilisation de l'algorithme du banquier
Pour vérifier si on est en état sûr, on peut utiliser l'algorithme du banquier. On doit calculer la matrice des allocations courantes (C) correspondant aux besoins - les demandes, des demandes (R) correspondant aux besoins - allocations courantes et des ressources disponibles (A) correspondant aux ressources existantes - allocations courantes.
Pour chaque processus, on regarde si on peut remplir sa demande à partir des ressources disponibles. Si oui, on marque le processus comme terminé et on ajoute ses ressources aux ressources disponibles.
On répète cela en boucle jusqu'à ce que tous les processus soient terminés, si cela n'est pas possible, alors l'état n'est pas sûr.
Pour allouer depuis un état sûr, lorsqu'un processus demande une ressource, on va hypothétiquement diminuer les ressources disponibles (et les besoins), et on va augmenter les ressources allouées. On effectue ensuite l'algorithme de vérification pour voir si l'état qui arriverait après l'allocation est sûr.
S'il l'est alors, on peut allouer, s'il ne l'est pas, il faut attendre.
Détection d'un interblocage
Le problème d'éviter un cycle d'attente, c'est qu'il faut connaitre à l'avance les besoins des processus, ce qui est souvent inconnu.
Alors si on veut simplement pouvoir détecter et traiter un interblocage lorsqu'il survient. On peut savoir qu'un interblocage arrive si l'utilisation du CPU est trop faible et que les processus sont en état waiting.
Correction ou non d'un interblocage
Pour corriger l'interblocage, il faut alors tuer un processus qui pose un problème et tenter de maintenir les ressources dans un état cohérent.
Si possible, il faut faire un rollback vers le contexte où le système était avant pour s'assurer que les ressources ne sont pas incohérentes. Cela nécessite toute fois que le contexte ait été sauvegardé.
Certains systèmes cependant ne corrigent pas les interblocages (par exemple UNIX) car les interblocages ne surviennent pas fréquemment, c'est alors à l'administrateur·ice de le corriger.
Question 3 (mémoire)
Détaillez le fonctionnement de la mémoire, expliquez l’allocation, la pagination et la segmentation en concluant par une description de l’utilisation conjointe de ces deux mécanismes.
Fonctionnement de la mémoire
La mémoire est une ressource indispensable et est partagée entre tous les processus. C'est une suite non structurée d'octets.
Un processus doit se trouver entièrement en mémoire afin de s'exécuter, cela nécessite donc de trouver une gestion efficace de la mémoire pour permettre à tous les processus de s'exécuter.
Chaque processus doit disposer de sa propre zone mémoire pour éviter des problèmes de sécurité ou d'intégrité des données. Si un processus essaye d'accéder à quelque chose en dehors de sa zone mémoire, on a une "segmentation fault" qui fait crash le programme. La mémoire peut cependant être partagée ente les processus si cela est explicitement demandé.
Types de mémoires
Il existe différents types de mémoire, les registres qui sont des zones mémoires attachées au processeur, leur taille est généralement très réduite (quelques Ko) mais sont très rapides, car pouvant être accédés en un seul cycle d'horloge du processeur.
La mémoire vive est la mémoire principale du système, souvent présente dans des quantités de l'ordre de quelques Go, elle est toute fois plus lente par rapport au CPU, mais reste beaucoup plus rapide qu'un disque.
La mémoire cache a pour but d'améliorer les performances du système en mettant en mémoire plus rapides les données fréquemment utilisée. Il existe trois niveaux de mémoire cache, le niveau 1 stocke temporairement les instructions et données tandis que les niveaux 2 et 3 sont présentes entre la mémoire vive et celle de premier niveau.
Enfin, il y a la mémoire virtuelle qui est une mémoire simulée par le système et qui utilise le disque dur comme mémoire supplémentaire. Elle peut être de l'ordre de plusieurs To si on le souhaite, mais elle est très lente. Il faut donc l'utiliser pour stocker des données peu utilisées.
Translation d'adresse
Lorsqu'un programme est chargé, il est placé entièrement placé en
mémoire à son adresse de départ. Les instructions du programme font
référence à l'adresse 0 qui est l'l'adresse logique du début du
programme.
Il faut donc traduire l'adresse logique en adresse physique, c'est-à-dire en une position particulière dans la mémoire RAM.
Cette conversion peut être faite, soit à la compilation, l'adresse physique est alors hard-codée dans le programme, ce qui n'est plus du tout d'actualité aujourd'hui, au chargement où l'adresse de départ est choisie au moment du lancement du processus ou à l'exécution cependant cela demande un hardware précis est utilisé par la segmentation.
Cette conversion se fait par le Memory Management Unit (MMU) qui est un composant matériel spécialisé dans cette opération.
Allocation de la mémoire
Pour allouer la mémoire à chaque processus, il y a différentes méthodes dépendant du type de système.
En mono-programmation, où un seul processus s'exécute en même temps que le système d'exploitation (genre MS-DOS), le processus a toute la mémoire pour lui, sauf pour une petite partie réservée au SE. Le BIOS réalise une gestion des périphériques.
En multiprogrammation, on peut soit diviser la mémoire en partitions fixes de taille variable pour ensuite associer chaque processus dans la plus petite zone qui peut la contenir. Cela a cependant le problème de gaspiller beaucoup de ressources (par exemple, un processus de quatre unités qui est dans une partition de sept unités).
Ou alors, on peut utiliser des partitions variables qui sont allouées selon les besoins des processus. Pour pouvoir allouer, il suffit donc de créer une partition de la taille adaptée.
Cela peut être fait avec une table de bits qui est une cartographie de la mémoire divisée en blocs (petits blocs = plus précis, mais plus lent à parcourir), on note un 1 si le bloc est occupé ou un 0 s'il est libre. Il suffit alors juste de trouver un espace avec suffisamment de zéro consécutif pour allouer une zone. Cela a cependant le désavantage que la table peut prendre beaucoup de place et donc être longue à parcourir.
Sinon, on peut utiliser une liste chainée où chaque élément de la liste correspond à une partition et sait si la partition est libre, la position de début de la partition, sa longueur et le lien avec l'élément suivant de la liste. Cela a l'avantage de pouvoir être parcouru beaucoup plus rapidement et de faciliter la fusion de blocs libres lorsqu'un programme libère une partition. Cela a cependant le désavantage de mener à de la fragmentation interne (bouts de mémoire non utilisé parmi la zone allouée à un processus).
Pour choisir quelle partition allouer au processus, il y a le choix entre plusieurs algorithmes.
- Le first-fit, qui consiste à prendre la première zone assez grande. C'est souvent cette méthode qui est utilisée, car elle est très rapide.
- Le best-fit qui consiste à parcourir toute la mémoire jusqu'à trouver la meilleure partition, cela est cependant une mauvaise idée parce que c'est lent et ça crée beaucoup de fragmentation externe (bouts de mémoire non utilisable puisque trop petit en dehors des zones allouées) en créant des bouts de partitions trop petites pour être utilisées.
- Le worst-fit qui consiste à parcourir la mémoire pour prendre la partition la plus grande possible pour éviter d'avoir trop de fragmentation externe. Cet algorithme est très rapide pour les listes triées par taille.
Pour résoudre les problèmes de fragmentation, il faut pouvoir rassembler les zones mémoires, pour cela peut utiliser le compactage qui consiste à rassembler les zones occupées et les zones libres ensemble. Cela est cependant couteux en ressource et lent. Une autre solution est d'utiliser la pagination.
Pagination
La pagination permet d'avoir un espace d'adressage en mémoire physique non contigu tout en ayant un espace d'adressage en mémoire logique contigu.
Pour cela, la mémoire logique est divisée en blocs de taille fixe (les pages), on fait de même avec la mémoire physique où les blocs sont appelés des frames. Chaque page correspond à une frame via la table des pages.
Lorsqu'un processus démarre, on va donc calculer le nombre de pages nécessaires pour son exécution, ensuite, on regarde le nombre de frames disponible. S'il y a suffisamment de frames disponibles, on peut lier les pages aux frames et les allouer au processus, sinon il faut attendre.
Grâce à ce système, la fragmentation externe n'existe plus et la fragmentation interne sera en moyenne d'une demi-page par processus.
Segmentation
L'utilisateur·ice voit un programme comme un ensemble de blocs distinct dont les données ne sont pas mélangées avec les autres (genre, code du programme, données, pile, etc). C'est pourquoi on va diviser l'espace d'adressage logique du processus en segments. Chaque segment a un nom, un numéro et une taille.
On peut par exemple avoir un segment pour les données du programme, un segment pour la pile, un segment pour le code.
Cette division de la mémoire permet au système d'offrir une protection adaptée pour ne pas mélanger les différentes données, on ne peut donc pas écrire sur le code du programme en modifiant les données.
Cela permet aussi de pouvoir partager certains segments entre plusieurs processus (ex. libraires systèmes) pour économiser l'espace mémoire.
Utiliser uniquement de la segmentation peut mener à un retour à la fragmentation externe, car les segments sont de taille variable. C'est pourquoi il faut la combiner avec de la pagination.
Pagination avec segmentation
On va prendre pour exemple ici l'architecture des processeurs Intel 32 bits.
Pour convertir l'adresse logique en adresse physique, il faut d'abord faire passer l'adresse logique à l'unité de segmentation qui va extraire le numéro de segment, le type de segment (privé ou partagé), les informations de protection et le décalage.
À partir de ces informations, elle va construire l'adresse linéaire, qui est composée du directory (table des pages à utiliser parmi le répertoire des tables de pages), la page et le déplacement.
Enfin, l'unité de pagination n'a plus qu'à prendre les informations de l'adresse linéaire pour trouver la bonne frame.
Question 4 (mémoire)
Détaillez le fonctionnement de la mémoire virtuelle (y compris les algorithmes de remplacement des pages).
Puis ce qu'il faut qu'un programme se trouve entièrement en mémoire pour s'exécuter, il faut trouver un moyen d'exécuter de très gros programmes (plusieurs Go), ou beaucoup de petits programmes.
Pour cela, on peut utiliser la mémoire virtuelle qui est une mémoire sur le disque, qui bien que peu rapide est très abondante.
Pour l'implémenter, on peut utiliser la pagination, dans lequel on va lier des espaces sur le disque à la table des pages, la mémoire virtuelle est donc elle-même divisée en pages. La table des pages est adaptée pour inclure un bit indiquant si la page se trouve sur le disque ou sur la mémoire physique.
Il faut donc également que le disque ait un endroit réservé pour avoir la mémoire virtuelle, cela peut être un fichier ou une partition.
Fonctionnement
Seules les pages nécessaires sont placées en mémoire physique. Le changement (swap) entre mémoire virtuelle et mémoire physique est effectué lorsqu'une page non chargée est demandée.
Lorsqu'une page est demandée, on va voir dans la table des pages si elle est présente en mémoire physique (bit valide), si ce n'est pas le cas alors, il s'agit d'un défaut de page.
Il est important de minimiser les défauts de pages pour ne pas trop impacter le système.
Tout d'abord, on vérifie si la page demandée est bien présente dans l'adressage du programme, si oui, on trouve une frame libre et on récupère la page depuis le disque. Ensuite, on ajuste la table des pages pour indiquer la page comme valide et indiquer sa position en mémoire physique. Enfin, on peut redémarrer le processus à l'instruction qui a causé le défaut de page.
S'il n'y a plus de frames disponible, il faut trouver une page victime qui sera replacée dans la mémoire virtuelle pour libérer une frame.
Algorithmes de choix des pages victimes
Il est important de choisir un bon algorithme afin de minimiser les défauts de pages.
- FIFO (First In, First Out), on sélectionne la page la plus ancienne. La performance est mauvaise, car ce n'est pas parce qu'une page est vieille qu'elle n'est plus utilisée.
- OPT (Remplacement Optimal), éliminer les pages qui ne seront plus nécessaires avant longtemps. Cela est cependant seulement une base théorique et est difficile à implémenter puisqu'on ne peut pas savoir quand une page sera utile à nouveau.
-
LRU (Least Recently Used), éliminer la page qui a été utilisée la
moins récemment. Pour cela, il faudrait ajouter une timestamp pour
chaque page, ce qui serait assez peu efficace. Sinon, on peut aussi
utiliser une pile ou l'un des autres algorithmes dérivés du LRU.
- LRU approximé, chaque page possède un bit de référence (par défaut à 0), dès qu'on accède à la page, on la met à 1, lorsque tout est à 1, on met tout à zéro sauf la dernière. La page choisie en cas de défaut de page est la première page avec un bit 0.
- LRU avec octet de référence, même chose que LRU approximé, mais à intervalles réguliers, on collecte les bits de références pour les mettre dans des octets de référence. La page victime sera la page avec la valeur d'octet la plus petite.
- Algorithme de la seconde chance, on stocke 2 bits par page, un bit de référence (comme LRU approximé) et un bit de modification. Le bit de modification est mis à un si la page est modifiée sur la mémoire physique, mais pas encore sur la mémoire virtuelle. La page victime idéale sera la page avec un bit de modification à 0 et un bit de référence à 0, car pas besoin de E/S.
- LFU (Least Frequently Used), éliminer la page utilisée la moins souvent, on ajoute donc un compteur pour chaque page et on sélectionne celui qui a le plus bas. Pas un bon algorithme parce que ce n'est pas parce qu'une page n'a pas encore beaucoup été utilisée qu'elle ne le sera pas.
- MFU (Most Frequently Used), inverse du LFU pour palier à la critique précédente. Cependant, cela reste un mauvais algorithme.
Amélioration des performances
Pour améliorer les performances, on peut garder un pool (ensemble) de page qui sont toujours immédiatement disponibles. Ainsi, lorsqu'un défaut de page survient, on alloue une page du pool immédiatement, on sauvegarde la page victime un peu plus tard et on ajoute la page victime dans le pool.
Allocation des frames
L'allocation des frames au processus est quelque chose de complexe, s'il n'y en a pas assez, beaucoup de défauts de pages. S'il y en a trop, plus assez de frames disponibles, donc beaucoup de défauts de pages.
Si on fait simplement le nombre de frames divisé par le nombre de processus (allocation équitable), il y aura beaucoup de gaspillage, car des petits processus auront beaucoup de mémoire et les gros pas assez.
Si on fait une allocation proportionelle à la taille des processus, il faut tenir compte que les processus à plus haute priorité doivent avoir plus de frames pour s'exécuter plus vite. Il faut aussi tenir compte de la multiprogrammation, soit beaucoup de processus = moins de frames par processus.
Si on n'alloue pas assez de frames au processus, le processus va passer beaucoup de temps à transférer des informations. Le trashing c'est quand un processus n'a pas suffisamment de frames allouées et passe plus de temps à récupérer ses pages qu'à s'exécuter. Sauf que puisque l'utilisation CPU diminue, le système va augmenter la multiprogrammation, donc augmenter le nombre de processus, ce qui va diminuer encore plus le nombre de frames et donc causer encore plus de défauts de pages.
Pour résoudre le problème de trashing, il faut utiliser le modèle de la localité, il faut arriver à identifier les pages qui sont utilisées ensemble (localité), cela assure donc que tant que le programme utilise le même groupe de page, il n'y aura pas de défaut de page.
Question 5 (fichiers)
Expliquez le support des fichiers dans le SE, la structure du système de fichier et évoquez les problèmes d’allocation
Support des fichers dans le SE
Un fichier est une collection nommée d'informations en relation. C'est pour l'utilisateur·ice, un moyen de conserver des informations. Le système doit permettre aux programmes de créer, lire, écrire, changer la position du curseur et supprimer un fichier.
Lorsqu'un processus souhaite accéder à un fichier, il demande une ouverture du fichier, le système va alors mémoriser les informations sur le fichier (mode d'ouverture, emplacement du premier bloc, position courante et permissions d'accès), vérifier si l'accès est autorisé, initialiser les structures internes et placer le curseur de position au début.
Une fois le traitement fini, le fichier est fermé, le système peut donc supprimer les structures internes. Ce système d'ouverture et de fermeture soulage beaucoup le système d'exploitation.
Le type du fichier (qui indique sa structure interne) est identifié par l'extension (sous Windows), un "uniform text identifier" (sous macOS), par les valeurs des premiers octets (sous Linux) ou avec des attributs étendus (sous OS/2).
Un fichier peut être accédé via plusieurs méthodes. De manière séquentielle, c'est-à-dire que l'on lit tout du début à jusqu'à la position voulue (par exemple sur une bande magnétique), direct où on va directement à la position voulue ou séquentielle indexée qui permet un accès séquentiel et un accès direct.
Structure du système de fichiers
Structures
Il y a deux structures principales du système de fichiers, la partition qui est une partie du disque dur qui permet d'isoler des données du reste.
Le répertoire qui contient des fichiers ou d'autres répertoires. Il faut donc que cette structure puisse localiser, créer, supprimer, renommer, visualiser des fichiers et se déplacer dans un autre répertoire.
Le répertoire contenant tout sur le système est le répertoire racine (root directory). Un chemin d'accès est dit absolu s'il part de la racine et relatif s'il part d'un autre dossier.
Pour supprimer un dossier, cela dépends des systèmes, sous Linux les fichiers sont supprimés récursivement.
Il est possible de créer des liens vers des fichiers à d'autres
emplacements, sous Windows, c'est simplement un fichier binaire .lnk,
sous Linux, c'est un fichier spécial qui pointe un autre fichier.
Accéder à un lien sous Linux revient donc exactement à accéder au
fichier. Cela permet de faire des économies de place.
Il est aussi possible de monter d'autres systèmes de fichiers d'une autre partition ou d'un autre média (dvd, usb, etc), le format peut aussi être différent du format actuel (ntfs, fat, ext4, etc).
Lors d'un montage, le système vérifie la cohérence et donne accès aux informations en le faisant apparaitre dans le système de fichier. Le montage peut être implicite (automatique) ou explicite (demandé manuellement).
Implémentation
Le système retient la liste des partitions montées, les informations sur les répertoires récemment visités, la table générale des fichiers ouverts (qui décrit tous les fichiers ouverts sur le système) et la table de fichiers par processus (qui décrit les fichiers ouverts pour le processus courant, en incluant des informations supplémentaires par rapport à la TFO tel que le mode d'ouverture ou la position courante).
Pour implémenter les répertoires, le système peut le faire sous forme de liste (le problème est qu'il faut alors un accès séquentiel). Ou alors sous forme de table hashée en plus de la liste (hashmap), cela permet alors un accès direct et séquentiel aux fichiers. Il faut tout de fois faire attention aux collisions (deux fichiers pour un seul hash) et à la grandeur variable de la table, il faut donc pouvoir la faire grandir.
Problèmes d'allocation des fichiers
Pour allouer l'espace, il faut trouver un moyen de savoir où écrire les fichiers sur le disque.
La première méthode est l'allocation contiguë, chaque fichier occupent des blocs qui se suivent sur le disque. Ce qui rend donc la lecture très simple. Cela peut aussi permettre un accès direct aux positions du fichier si on connait la position et le premier bloc. Le problème est que cela amène de la fragmentation externe à cause des libérations successives, il faut alors compacter (défragmenter) ce qui est dangereux et chronophage. Également il faut pouvoir faire le fichier, si on y crée un buffer pour le permettre de grandir, alors on se retrouve avec de la fragmentation externe et interne.
La deuxième méthode est l'allocation chainée, chaque fichier est une liste de blocs chainés entre eux. Cela a l'avantage de ne pas avoir de fragmentation externe et de pouvoir faire croitre le fichier, car les blocs peuvent se trouver n'importe où. Cela crée toutefois beaucoup de voyage de la tête de lecture. Pour résoudre ce problème, certains systèmes allouent des groupes de blocs (cluster), plus tôt que des blocs, ce qui crée donc de la fragmentation interne.
La troisième méthode est l'allocation indexée, on garde un ou plusieurs bloc(s) "index" pour chaque fichier qui pointe les blocs du fichier. Cela permet un accès direct aux différents blocs, tout en permettant aux blocs de se trouver n'importe où. Cependant l'index peut devenir très grand, le problème de voyage de la tête de lecture est toujours là et maintenant, il va en plus falloir passer sur les blocs d'index.
La méthode d'allocation à choisir dépends de la façon dont le système est utilisé, certains systèmes utilisent plusieurs méthodes. Par exemple allocation contiguë pour les petits fichiers et allocation indexée pour les plus gros.
Pour pouvoir allouer, il faut aussi pouvoir trouver les blocs marqués libres pour cela, on peut utiliser une table de bit (cependant elle peut grandir beaucoup) ou une liste chainée (qui a aussi l'avantage de pouvoir fusionner les espaces libres).
Le système de fichier peut devenir incohérent, il faut donc que le SE mette en place des systèmes pour vérifier la cohérence et corriger des erreurs (par exemple vérification qu'un bloc ne soit pas deux fois comme libre, deux fois comme occupé, les deux en même temps ou rien du tout).
Pour restaurer les données, on peut aussi utiliser la sauvegarde (copie pour but de restauration rapide) et l'archivage (copie dans le but de les garder longtemps).
Il y a deux types de sauvegarde, la sauvegarde incrémentale (on enregistre que ce qui a changé depuis la dernière sauvegarde) ou différentielle (on enregistre que ce qui a changé depuis la dernière sauvegarde complète). La différentielle prend donc plus d'espace et est plus lente à faire, mais est plus simple à restaurer.
Si un problème survient durant des opérations sur le système de fichier, le système peut utiliser le journal (une historique de toutes les opérations en cours) pour défaire des opérations non terminées ou en panne. Ce système est similaire à celui des transactions en base de données et les opérations respectent le principe ACID (Atomicité, cohérence, isolation, durabilité).
Question 6 (E/S)
Présentez la gestion des E/S dans le SE (matériel, logiciel ainsi que les différentes couches).
Gestion des E/S au niveau matériel
Au niveau matériel, on distingue les périphériques d'entrées-sorties (clavier, souris, écran, etc) des contrôleurs (interface entre le SE et le périphérique), permet au SE de contrôler le périphérique et permet d'envoyer des interruptions au SE.
Il existe deux types principaux de périphériques d'E/S, les périphériques blocs, les données sont adressables et dans des blocs de taille fixes (exemple disque dur), et les périphériques caractères où l'information est un flux sans structure (carte réseau, clavier, souris, etc).
Un contrôleur est la partie électronique qui contrôle le matériel, soit sur la carte mère, soit externe (clé USB par exemple).
Le SE commande le périphérique via les registres du microprocesseur du contrôleur du périphérique.
Le dialogue entre le SE et le contrôleur être soit fait via les ports d'E/S en écrivant ou lisant des données dans les registres (plus d'actualité aujourd'hui). Ou alors en mappant une zone mémoire mappée aux registres du contrôleur, cela a donc l'avantage de devoir simplement utiliser les mécanismes de protection de la mémoire et des opérations de base (pas besoin d'instructions assembleur particulières).
Lors d'une lecture sur le disque, le contrôleur va enregistrer un bloc dans sa mémoire, le vérifier et faire une interruption au SE. Le SE va ensuite exécuter une routine adaptée pour copier l'info en mémoire.
Cela signifie que le SE est constamment sollicité durant le transfert. Pour permettre le soulager le SE, on peut introduire un contrôleur DMA qui va directement copier les informations en mémoire. Ainsi, lorsque l'on veut lire un bloc, on dit au DMA ou stocker les infos en mémoire, et on dit au contrôleur du disque de lire le bloc. Le bloc est ensuite passé au DMA qui va directement mettre les infos en mémoire. Une fois que toutes les infos sont en mémoire, il fait une interruption.
Cependant, lorsque le DMA travaille, il ne peut pas attendre pour écrire les données, car sinon il risque d'en perdre. C'est pourquoi le DMA passe en priorité par rapport au CPU en cas d'accès à la mémoire. C'est ce qu'on appelle un vol de cycle.
Gestion des E/S au niveau logiciel
La partie logicielle a pour but de fournir une interface unifiée vers les périphériques, aux programmes. L'accès à une clé USB ou un disque doit donc être vue comme la même chose du point de vue du programme. Cette partie du système est divisée en plusieurs couches.
Le gestionnaire d'interruption, dès qu'une interruption survient depuis le périphérique, le gestionnaire d'interruption va sauvegarder le contexte du processus en cours, créer le contexte pour le traitement de l'interruption, se placer en état disponible pour traiter les interruptions suivantes, exécuter la routine (procédure de traitement) adaptée à l'interruption. Une fois toutes les interruptions gérées, le scheduler choisit le processus à démarrer.
Le gestionnaire de périphérique (ou pilote ou driver), dépends de la nature du périphérique. Les pilotes doivent être chargés au cœur du système (dans le noyau/kernel en mode protégé) pour pouvoir agir directement sur les périphériques (c'est pourquoi un mauvais driver peut faire crasher le système). Lorsqu'il doit faire une action, le gestionnaire de périphérique traduit les informations données en informations physiques, ensuite, il s'endort jusqu'à être réveillé par le gestionnaire d'interruption.
La couche logicielle indépendante (ou interface standard) sert à uniformiser l'accès aux périphériques. Il possède donc une API qui doit être respectée pour tous les pilotes pour pouvoir accéder aux pilotes de la même manière partout. Cette couche va également uniformiser les noms des périphériques, mettre en place des buffers (tampons) pour améliorer les performances, gérer les erreurs (de programmation ou entrée-sortie, si c'est le deuxième cas, c'est le pilote qui réessaye).
C'est aussi cette couche qui s'occupe de l'allocation et la libération des périphériques non partageables (genre une imprimante). Lors d'une ouverture, cette couche vérifie la disponibilité.
La couche d'entrée-sortie applicative gère les entrées sorties au
niveau de l'application, par exemple via des libraires systèmes liées
aux programmes (genre stdio) et fournir un système de spooling qui
est une file d'attente pour l'accès aux périphériques non partageables
(exemple, liste de jobs d'impression).
Question 7 (E/S)
Illustrez la gestion des E/S dans le SE en détaillant le fonctionnement du disque et de l’horloge
Disque
Un disque magnétique est composé de plusieurs disques physiques (plateaux), le disque est découpé en cylindres, pistes et secteurs.
- Un cylindre correspond à l'ensemble des pistes qui correspondent à une certaine position de la tête de lecture.
- Une piste correspond à un cercle sur le plateau qui correspond à une certaine position de la tête de lecture. Chaque piste est elle-même découpée en secteurs.
- Les secteurs sont des blocs de tailles fixes qui composent chaque piste.
La géométrie du disque dur n'est pas forcément celle annoncée, car le nombre de secteurs par piste n'est pas constant. La géométrie du disque du point de vue du SE est donc une simplification.
Afin de pouvoir être utilisé, un disque doit être formaté (formatage de bas niveau par le fabricant) qui consiste à écrire la géométrie du disque (chaque secteur contient un préambule concernant le numéro du secteur, du cylindre, etc) avec des données telles qu'un code ECC pour la gestion d'erreur.
Ensuite, on peut mettre en place des partitions qui seront vues comme des espaces séparés par les systèmes d'exploitations.
Il peut y avoir beaucoup d'erreurs différentes sur un disque, notamment des erreurs qui peuvent survenir lors de la construction ou du formatage de bas niveau. Il faut donc que le système d'exploitation stocke les blocs défectueux afin de ne pas les utiliser par la suite.
Le disk arm scheduling est une opération faite par le SE pour minimiser le seek time (déplacement de la tête de lecture) lorsqu'il faut traiter plusieurs requêtes. Il y a donc plusieurs algorithmes différents :
- Le FCFS, premier arrivé, premier servi. Simple, mais pas efficace.
- Le SSTF, toujours servir les requêtes les plus proches. Fait diminuer le temps de réponse, mais nécessite de calculer les positions tout le temps et risque de créer de la famine parmi les requêtes les plus éloignées.
- Le SCAN, le bras de lecture va toujours dans la même direction jusqu'à arriver à la fin du disque et retourner dans le sens inverse. Plus de famine, car on avance toujours.
- Le C-SCAN, comme le SCAN sauf qu'a la place de revenir dans l'autre sens, il va directement à l'autre extrémité et recommence
- Le LOOK, comme le SCAN sauf qu'a la place d'aller à l'autre bout du disque, il s'arrête à la dernière requête.
- Le C-LOOK, comme le C-SCAN, mais s'arrête à la dernière requête.
Le C-SCAN et C-LOOK sont intéressants pour les disques très chargés. SSTF est un bon remplacement à FCFS. Et c'est souvent un SSTF ou une variante du LOOK que l'on va trouver sur les systèmes.
Aujourd'hui le scheduling est aussi réalisé au niveau des contrôleurs en plus du SE.
RAID
RAID est une technologie qui consiste à combiner plusieurs disques afin d'améliorer les performances et/ou la fiabilité. Elle fonctionne à l'aide du mirroring et du stripping.
Le mirroring consiste à dupliquer les informations d'un disque sur un autre. Lors d'un accès en écriture, on effectue la modification sur les deux disques en même temps.
Le stripping consiste à répartir les informations sur plusieurs disques. Cela peut permettre de lire huit fois plus vite, car on peut lire sur tous les disques en même temps.
Les différents RAIDs sont répartis en niveaux,
Le RAID 0 fait simplement du stripping, cela permet d'avoir un grand espace en combinant les deux disques.
Le RAID 1 fait uniquement du mirroring, cela permet d'avoir une plus grande fiabilité en dupliquant les données.
Le RAID 3 fait du stripping au niveau des octets et garde un bit de parité sur un disque séparé. Si on perd un disque, on peut ainsi reconstruire l'information à la volée avec le bit de parité.
Le RAID 4 fait du stripping au niveau des blocs, les blocs de partiés sont gardés sur un disque séparé. Contrairement au RAID 3, une lecture de bloc ne nécessite l'accès qu'à un seul disque, ce qui est donc plus rapide. On ne peut cependant pas écrire en parallèle, car tous les bits de parités sont sur le même disque (pas d'accès concurrent au disque de parité).
Le RAID 5 est une amélioration du RAID 4 qui consiste à distribuer les bits de parités sur tous les disques afin de permettre un accès concurrent en écriture. Généralement, c'est ce modèle qui est choisi.
Le RAID 6 est une amélioration du RAID 5 qui ajoute un bit de parité dans le but de protéger contre la perte de deux disques dur. Ce modèle est cependant plus complexe et nécessite que le contrôleur RAID ait un CPU plus important.
Le RAID 0+1 consiste à utiliser deux RAID 0 (stripping) qui sont dupliqués par un RAID 1 (mirroring). Cela est cependant assez cher.
RAID permet aussi des options particulières comme le hot-swap, qui consiste à permettre d'enlever des disques pendant que le système tourne, ainsi que l'option spare qui consiste à avoir un disque présent inutilisé, mais prêt à l'emploi en cas de perte d'un disque.
Pour faire un RAID réussi, il faut pouvoir maximiser le débit de lecture et écriture ainsi que de favoriser une diversité parmi les disques dur afin qu'ils ne tombent pas tous en panne en même temps.
Horloge
L'horloge est un périphérique spécial qui sert simplement à déterminer la date et l'heure du système. Cette fonction est essentielle pour maintenir des statistiques, calculer le quantum de temps des processus, etc. Certains systèmes ne disposent pas d'horloge et synchronisent leur temps via le réseau ou en le demandant à l'utilisateur·ice au lancement du système.
L'horloge fonctionne avec un quartz, un compteur et un registre. Le quartz lorsqu'il est sous tension génère un signal périodique très précis qui peut être utilisé pour la synchronisation des composants. Le signal est ensuite fourni au compteur qui va décompter jusqu'à arriver à zéro. Une fois à zéro une interruption est émise vers le CPU et le gestionnaire l'horloge prend la main.
Ensuite, ici, il y a deux modes de fonctionnement. Soit le mode one-shot, une interruption est envoyée et on attend une réaction. Ou alors le mode square wave qui, une fois que le compteur arrive à zéro, recommence. On parle ici de ticks d'horloge.
Le système va ensuite maintenir la date et l'heure en comptant le nombre de secondes depuis une référence (exemple, sous UNIX 1er Janvier 1970 00:00:00 UTC). Pour synchroniser l'heure, il suffit donc de savoir le nombre de secondes depuis un point de référence.
Ensuite, le logiciel d'horloge va maintenir l'heure, vérifier qu'un
processus ne dépasse pas son quantum, compter l'utilisation CPU, gérer
l'appel système alarm, etc.
Pour vérifier qu'un processus ne dépasse pas son quantum, le compteur d'horloge est initialisé par le scheduler en fonction du quantum, à chaque interruption, il est diminué jusqu'à arriver à zéro ou il est alors remplacé.
Pour pouvoir cependant gérer plusieurs évènements temporels sans pour autant avoir plusieurs horloges dans le système, le système va créer une file d'évènement qui agit comme une sorte d'agenda pour planifier des évènements.
Question 8 (sécurité)
Définissez la protection (y compris la matrice d’accès). Présentez la sécurité et les mécanismes pour l’assurer à l’intérieur du SE.
Définition de la protection
La protection est un mécanisme mis en place pour l'accès à la gestion de ressources du système par les processus. La sécurité est un spectre plus large incluant les virus, les attaques et la cryptographie.
La protection a pour but de prévenir les violations d'accès et d'améliorer la fiabilité (en détectant des erreurs humaines par exemple). Une politique de protection définie ce qui doit être protégé et les mécanismes de protection sont les moyens de protéger.
Il faut pouvoir protéger les processus et les objets, les objets peuvent être ressources matérielles (CPU, mémoire, etc) ou logicielles (fichiers, sémaphores, programmes, etc).
Il faut s'assurer que chaque processus ne peut accéder qu'aux ressources auxquelles il a l'autorisation.
Un domaine de protection définit l'ensemble d'objet et d'opération qui peuvent être exécutés sur ceux-ci. La possibilité d'exécuter quelque chose s'appelle un droit d'accès, un domaine est une collection de droits d'accès et chaque processus opère à l'intérieur d'un domaine de protection.
L'association entre un processus et un domaine peut être statique (ne change pas, les droits d'accès restent tout le temps les mêmes) ou dynamique (les droits d'accès peuvent changer).
La matrice d'accès
La matrice d'accès est une représentation des différents domaines, objets et droits d'accès. Chaque ligne correspond à un domaine et chaque colonne représente un objet. Chaque case représente les droits d'accès (lire, écrire, exécuter, etc) pour un domaine par rapport à un objet précis.
Pour pouvoir changer de domaine, il suffit de représenter les domaines comme des colonnes également et d'utiliser le mot switch dans la colonne du domaine vers lequel on peut aller.
Une autre permission spéciale est celle de pouvoir copier son droit à un
autre domaine. Ce droit est représenté par une *. Il y a aussi la
permission de transfert qui est comme celui de la copie sauf que
lorsqu'un transfert se fait, le domaine perd le droit d'accès.
Il y a aussi le droit à la modification des droits d'accès d'un objet, c'est le droit owner qui permet de modifier n'importe quel droit pour un objet donné.
Enfin, il y a le droit de contrôle d'un domaine qui permet de supprimer des droits d'accès à un autre domaine. Ce droit est le droit control.
Sous UNIX, chaque domaine correspond à un utilisateur·ice, lorsqu'un
exécutable est lancé, le processus prend le domaine de l'utilisateur·ice
courant·e. Excepté lorsque le bit setuid est mis, dans quel cas le
processus est lancé dans le domaine du propriétaire de l'exécutable.
Utiliser une matrice d'accès comme implémentation de la protection ne serait pas très pratique, car prendrait beaucoup de place. C'est pourquoi on utilise des access list à la place, pour chaque objet, elle contient des pairs de domaines et de droits (si un domaine n'est pas lié à un certain objet, alors il n'a pas de droit sur l'objet).
Le système doit aussi prévoir comment révoquer des droits, si c'est immédiat ou décalé, pour quels utilisatuer·ice·s, temporaire ou permanent, etc.
Sécurité et mécanismes dans le SE
Les mécanismes de sécurité consistent à protéger le système contre le vol d'information, la modification ou destruction non autorisée d'information et la surveillance de l'utilisation du système. Le but est de ralentir les violations du système le plus possible pour rendre le cout de pénétrer un système plus important que le gain à en retirer.
Il y a plusieurs niveaux de protection différents, le niveau physique (protection du matériel), humain (surveillance de l'accès au matériel), réseau (via des firewalls), et système d'exploitation.
Des informations volées ou perdues peuvent conduire à la faillite d'une entreprise.
Identifications des utilisateur·ice·s
Les systèmes actuels ne fonctionnent que lorsque les utilisateur·ice·s sont authentifié·e·s. Il y a différentes méthodes d'identifier les personnes,
Identification par mot de passe
L'identification par mot de passe qui est l'une des plus courantes, mais qui a beaucoup de problèmes. Les mots de passes peuvent être découvert par espionnage (keylogger, network sniffing), force brute (dictionnaire, rainbow table, brute force), ou encore par déduction (le nom du chien, date de naissance, etc) ou encore par arnaque (fishing). Beaucoup de vulnérabilités des mots de passes sont dans le fait que beaucoup de gens utilisent des mots de passes faibles et les réutilisent partout.
Les mots de passes peuvent être stocké de plusieurs manières, mais seules certaines sont sûres,
- Si on stocke les mots de passes en clair, cela signifie que quiconque a accès à la base de donnée a accès à la vie en ligne de presque tous les utilisateur·ice·s
- Si on chiffre les mots de passes, cela pose un problème si quelqu'un découvre la clé, ou si plusieurs personnes utilisent le même mot de passe, on pourra également le voir, car les mots de passes chiffrés seront les mêmes.
- Si on les hash (faire passer les mots de passe dans une fonction à sens unique pour créer une "empreinte" des mots de passes), plusieurs personnes avec le même mot de passe auront le même hash. Par ailleurs, cette méthode est vulnérable au rainbow table attack qui consiste à utiliser des tables de hash pré calculés pour ne pas avoir à calculer les hash un à un, ce qui rend l'attaque plus rapide qu'une attaque par dictionnaire.
- Si on les hash avec salt qui consiste à utiliser la méthode précédente, mais en ajoutant une chaine de caractère aléatoire au mot de passe (le salt est ensuite simplement mis à côté du mot de passe). Cela règle tous les problèmes cités précédemment.
La méthode de stockage des mots de passes recommandée est le hash avec salt en utilisant une fonction de hashage lente pour ralentir le plus possible les attaques.
Ne pas stocker les mots de passes et le gérer l'identification par un tiers de confiance peut être une bonne idée si le stockage des mots de passes est une trop lourde responsabilité.
Identification a plusieurs facteurs
L'identification à plusieurs facteurs consiste à utiliser d'autres systèmes en conjonction avec les mots de passe afin de sécuriser le mécanisme. On peut par exemple utiliser des codes à usages uniques (tel que le TOTP) qui peuvent être généré sur base de chaines de hash (hashage n fois d'une valeur de départ, à chaque utilisation, on fait un hash en moins = codes à usage unique) ou sur base du temps (hashage du temps actuel + d'un token partagé avec le serveur = code à usage unique). L'identification peut aussi être faite via des appareils externes tels qu'une clé FIDO2.
Ce mécanisme (TOTP) est par exemple utilisé pour des digipass de banques.
Identification password-less (+ biométrique)
On peut aussi utiliser des mécanismes vu précédemment, tel que celui de clé FIDO2 qui peut être utilisé pour SSH, permettant de se connecter sans utiliser de mot de passe.
Sinon, on peut aussi utiliser l'identification biométrique qui se fait en scannant des propriétés de l'utilisateur·ice·s tel qu'une empreinte digitale ou la forme du visage. Ces informations scannées deviennent ensuite une sorte de mot de passe.
Le problème avec cela cependant est que ces données sont très personnelles et confidentielles, le stockage est donc primordial, car on ne peut pas changer notre empreinte digitale.
Sécurité des applications
Écrire un code sans erreurs est difficile et les erreurs peuvent conduire à des vulnérabilités qui permettent d'attaquer le programme. L'attaque peut permettre d'obtenir des droits non-accordés au départ, faire planter l'application, introduire des données incorrectes, etc.
Comme attaques courantes, on trouve :
- La Remote Code Execution (RCE), l'exécution de code à distance en soumettant des données précise à l'application (exemple log4shell)
- La SQL Injection, injection de code SQL dans la base de donnée en injectant des données précises.
- Les Format String vulnerabilities qui consiste à soumettre du code
qui sera compris comme des commandes par l'application (par exemple
via des
%sou%d). - Cross-Site Scripting (XSS), ajout de code HTML en soumettant des données incorrectes (et donc potentiellemnet Javascript), exécuté par tous les visiteurs de la page.
- Username enumeration consiste à tester plusieurs noms d'utilisateur·ice·s pour savoir lesquels sont présents sur le système.
- Stack/Buffer Overflow, soumet des caractères spécifiques de façon à faire déborder la pile du programme, le code exécuté devient alors celui de l'attaquant qui peut prendre le contrôle de l'application.
-
Déni de Service (DoS), rendre inaccessible un système en le
bombardant de requêtes.
- Déni de Service Distribué (DDoS), un DoS exécuté depuis pleins de machines différentes (machines zombies) qui font partie d'un ensemble de machine appelé botnet.
Comme programmes malveillants, on trouve :
- Le cheval de troie (trojan) qui est un programme qui se fait passer pour un autre afin de déclencher des actions hostiles (exemple, faux anti-virus)
- La porte dérobée (backdoor), le programme installe une porte d'accès à l'utilisateur qui permet d'exécuter des commandes à distance (ce qui peut transformer la machine en zombie faisant partie d'un botnet)
- Les vers informatiques (WORMS) se propagent par le réseau via des vulnérabilités des machines qui en font partie.
- Les virus informatiques sont des ensembles d'instructions qui
utilisent un programme pour se reproduire. Utilisent des techniques
pour se cacher, ont pour principal but de se reproduire et peuvent
avoir une charge active qui attaque le système à un moment déterminé.
- Les virus script sont des virus écrit dans un langage interprété qui utilise un environnement tiers (ex Microsoft Word) pour s'exécuter (par exemple via une macro).
Pour se protéger contre les attaques, il est important de protéger le périmètre (tout ce qui est autour des machines, par exemple le réseau), en installant un firewall réseau. Ainsi que de protéger les machines en installant un firewall sur les machines et un anti-virus. Il faut également faire attention à ne jamais travailler en compte administrateur.
Pour assurer la sécurité d'un parc informatique, on peut utiliser divers outils, tel que des scanners de vulnérabilités qui vont regarder si le système est vulnérable à certaines attaques afin de mettre à jour les composants qui en ont besoin.
Ou encore une sauvegarde des empreintes de tous les programmes dans le but de vérifier celles-ci lors du lancement pour vérifier que des programmes n'aient pas de virus. Il faut cependant faire attention à les garder à jour.
Utiliser un système de détection d'intrusion (IDS) qui va repérer
les activités anormales sur un système en se basant sur des plans
d'attaques connus, comportements anormaux, en observant l'activité et
les journaux systèmes (par exemple fail2ban qui banni les IP qui font
des tentatives trop fréquentes)
Enfin, on peut utiliser des systèmes d'analyse de fichiers journaux tels que Splunk ou Grafana Loki.
Question 9 (sécurité)
Décrivez le fonctionnement de la cryptographie (historique et domestique) et le fonctionnement de la signature numérique.
Fonctionnement de la cryptographie
La cryptographie consiste à cacher des informations en utilisant des algorithmes. Le texte non chiffré est appelé texte en clair, le texte chiffré est appelé cryptogramme.
Le niveau de chiffrement utilisé dépend des personnes contre lesquels on désire se protéger. On ne va pas utiliser le même niveau de chiffrement si on souhaite se protéger contre la NSA ou contre ses concurrents.
C'est aussi une question de longueur de clé, plus la clé est longue, plus ce sera sécurisé.
L'algorithme qu'on utilise est également déterminant, un bon algorithme doit être public (vérifiable), sûr (éprouvé et approuvé) et indépendant (pas de lien avec des groupes tel que la NSA).
Un algorithme est sûr s'il est impossible qu'un espion ayant un texte chiffré, un texte chiffré et un texte en clair ou une infinité de textes chiffrés et en clair ne puisse déterminer la clé de l'algorithme ou déchiffrer les éléments.
Histoire de la cryptographie
La cryptographie existe depuis des siècles, mais était avant pratiqué par des militaires, des diplomates et des amants. Avant l'informatique, la cryptographie était limitée aux capacités du cerveau humain.
Deux méthodes catégories d'anciens chiffrements (datés et qui ne doivent plus être utilisés aujourd'hui) sont la substitution (remplacement de symboles par d'autres, comme le code de césar) et la transposition (mélange de symboles).
On peut aussi utiliser l'opération XOR comme base, car c'est une opération très simple à effectuer pour le CPU. On fait donc texte en clair XOR clé pour obtenir le cryptogramme, puis on fait cryptogramme XOR clé pour obtenir le texte en clair.
Un premier problème est que l'on peut retrouver la clé en faisant cryptogramme XOR texte en clair et donc déchiffrer toutes les autres communications.
Un autre problème est que si la clé se répète, on peut arriver à identifier la clé en faisant de l'analyse de fréquence.
Si la clé en revanche est complètement aléatoire et de la même longueur que le message, il s'agit alors d'un masque jetable qui est théoriquement un code incassable.
Le masque jetable est une technique de chiffrement se basant sur une longue liste non répétitive et aléatoire de lettres, chaque lettre est utilisée pour coder une lettre du texte clair. On peut par exemple additionner le rang de la lettre du masque avec celui de la lettre du texte clair. Cette technique est donc théoriquement incassable, mais peu pratique, car les clés sont très longues.
Cryptographie à clé secrète (symétrique)
Dans les crypto systèmes à clé secrète, une clé sert à la fois à déchiffrer et à chiffrer (on dit qu'elle est symétrique). Les systèmes historiques sont dans cette catégorie, mais il y en a aujourd'hui des versions plus sécurisées telles que AES (Advanced Encryption Standard).
Le problème avec ce crypto système est qu'il faut garder en mémoire énormément de clés différentes par paire d'utilisateur, ce qui fait beaucoup de clés. De plus, ces clés doivent être distribuées et gardées de manière sûre, car si elle est compromise tous les messages sont compromis.
Cryptogrpahie à clé publique/privée (asymétrique)
À la place d'avoir une clé, on va avoir deux clés, une clé pour chiffrer et une clé pour déchiffrer. Ainsi, la clé pour chiffrer peut-être distribuée publiquement tandis que la clé pour déchiffrer reste secrète.
Cela fait qu'il n'y a maintenant plus besoin que d'une seule clé pour qu'un nombre infini d'utilisateurs puissent chiffrer des messages.
Également, on peut partager les clés facilement et sans risque puis ce qu'elles sont publiques.
Pour pouvoir assurer qu'une clé appartient bien à quelqu'un cependant, on peut utiliser des tiers de confiance tel que Let's Encrypt qui vont certifier les clés.
RSA
La sécurité de RSA se base sur la factorisation de grands nombres composés de grands nombres premiers, car la factorisation est un problème qui devient toujours plus complexe quand les nombres grandissent.
Et pour avoir un processus qui fonctionne dans un sens, mais pas dans l'autre sans avoir une information supplémentaire, RSA utilise l'exponentiation modulaire, c'est-à-dire que si on a $ m^e \mod n = c $, et que l'on connait, n, e, et c, il est très complexe de trouver m sauf si on a un autre exposant qui permettrait de renverser l'opération. On peut ensuite utiliser le théorème d'Euler pour trouver des exposants e (pour chiffrer) et d (pour déchiffrer).
- Trouver deux nombres premiers (par exemple, $ p = 11 $ et $ q = 17 $)
- Multiplier les deux nombres pour donner n (soit ici, $ n = p * q = 187 $)
- Trouver l'indicateur d'Euler (fonction phi) en faisant $ \Phi (n) = (p - 1) * (q - 1) = 160 $
- Trouver un entier e qui soit premier avec la fonction phi (indicateur d'Euler), par exemple 13
- Trouver d dans $ ed \mod \Phi (n) = 1 $, soit $ ed + k \Phi (n) = 1 $. En appliquant le théorème d'Euclide étendu ou celui de Bachet-Bézout (e et $ \Phi (n) $ étant premiers entre eux)
- Clé publique : $ { e, n } $, clé privée $ { d, n } $
Pour chiffrer (ou vérifier une signature) on peut alors faire $ m^e \mod n = c $ et pour déchiffrer (ou signer) on peut faire $ c^d \mod n = m $. À savoir que m doit être plus petit que n.
Signatures cryptographiques
Une signature permet d'identifier que quelqu'un a bien écrit quelque chose, une signature doit être authentique, non falsifiable, non réutilisable. Un document signé ne peut pas être modifié et une signature ne peut pas être reniée. Le but des signatures cryptographiques est d'avoir toutes ces propriétés.
Avec un crypto système à clé secrète, il faut avoir un tiers de confiance qui connait deux clés secrètes (une pour le signataire, et une pour le destinataire) permettant d'assurer que le document est authentique. Toute la sécurité est donc dans le tiers de confiance.
Avec un crypto système à clé publique, le tiers de confiance est facultatif (il peut toutefois être utilisé pour valider une clé). Le signataire signe ("décrypte un message en clair") avec sa clé privée, ensuite le destinataire peut vérifier ("chiffrer la signature" en quelque sorte) pour retrouver le message.
Les systèmes de confiances tels que les certificats TLS utilisés pour le HTTPS (certificats X509) lient une clé publique à une identité en utilisant une signature cryptographique d'un tiers de confiance. Les navigateurs ont ainsi une liste de tiers de confiance qui leur permet de vérifier les certificats.
Certains tiers de confiances sont gratuits (Let's Encrypt) cependant ils n'offrent pas le même niveau d'assurance et de confiance que des tiers de confiances payant (qui vont aller manuellement faire la vérification).
La confiance dans le système PGP (Pretty Good Privacy) en revanche fonctionne très différemment. L'identité des personnes est garantie de manière transitive ; Alice peut signer la clé de Bob pour annoncer à tous ses amis que Bob est de confiance. Les amis d'Alice pourront ainsi vérifier cela en vérifiant la signature d'Alice.