Couche de transport (UDP, transport fiable et TCP)
La couche applicative repose sur la couche de transport. Cette dernière s'en fout du type de donnée utilisée, cette couche a seulement pour but de transférer les données.
Il existe deux protocoles, le TCP (Transmission Control Protocol) qui permet d'envoyer des informations de manière fiables (en vérifiant la bonne réception des "paquets" de données), et l'UDP (User Datagram protocol) est un protocole qui envoie les paquets sans se soucier de la bonne réception. Ce dernier, bien que moins fiable, est beaucoup plus rapide.
Il faut donc connaitre le port du programme à contacter, pour cela le système maintient un annuaire liant un numéro de port à une application.
L'UDP (User Datagram Protocol)

Avec l'UDP on va simplement transmettre les données sans se soucier de leur bonne réception. Ainsi pour chaque message (TPDU, Transport Protocol Data Unit) il faut connaitre le numéro de port source (et destination ainsi que la longueur du message et éventuellement un "checksum" permettant de vérifier l'intégrité des informations.
Le protocole UDP est très utilisé pour les applications qui ont besoin d'aller vite, même si cela veut dire de potentiellement perdre des informations. Par exemple pour les jeux massivement multijoueurs, les diffusions en direct de vidéo ou audio, etc.
Le TCP (Transmission Control Protocol)
Le problème avec l'UDP est qu'il n'y a aucune vérification de la bonne réception des paquets ou encore de leur ordre ou de leur intégrité.
Le but du protocole TCP est de garantir l'intégrité des données.
Transfert fiable
TCP est donc un protocole qui implémente le "transfert fiable", nous allons voir ici en quoi consiste le transfert fiable.
Le transfert fiable est une façon de transférer l'information entre un émetteur et un récepteur de telle sorte à pouvoir palier à des pertes, des duplications, des altérations ou un désordre parmi les informations.
Pour cela, chaque TPDU (Transport Protocol Data Unit) contient un "checksum" permettant de vérifier que l'information n'est pas corrompue → protection contre l'altération.
Et lors de chaque réception d'information, le récepteur doit confirmer la bonne réception, si l'émetteur ne recoit aucun acquis de bonne réception avant un certain temps (timer), il considère que l'information est perdue et la renvoi → protection contre la perte d'information.
Si l'acquis lui-même est perdu, l'émetteur va renvoyer l'information et le récepteur va réenvoyer son acquis, car ce dernier a déjà reçu l'information → protection contre la duplication et la perte d'acquis.
Chaque acquis et chaque envoi d'information est donc numéroté, il est ainsi possible de savoir pour chaque acquis à quoi il fait référence. Si un acquis est donc envoyé deux fois, l'émetteur pourra savoir à quelle information chaque acquis fait référence et agir en fonction. S'il envoie une information 1, reçois l'acquis pour 1, puis envois une information 2 et reçois de nouveau un acquis pour 1, il ne prendra pas compte du deuxième acquis → protection contre la duplication d'acquis.
Les acquis et les informations étant ainsi numérotées et allant dans un ordre de croissant. Et puis ce que l'émetteur attend toujours d'avoir reçu une confirmation de bonne réception de chaque partie de l'information, ce protocole assure donc que les informations sont reçues dans le bon ordre → protection contre le désordre.
Fenêtre glissante
Les performances de TCP sont bien plus mauvaises que UDP car si le ping est élevé le round-trip time (temps allé-retour) va être très élevé aussi, cela sera donc très lent de tout transmettre. Pour résoudre ce problème, on peut alors utiliser un système de "fenêtre glissante", on va envoyer plus d'information avant d'attendre un acquis (donc moins d'acquis et pas d'envois de trop de données).
La fenêtre défini une série de numéros de séquences qui peuvent être envoyés sans devoir attendre un acquis. Une fois cette fenêtre épuisée, il faut attendre un acquis (pour toute la fenêtre) pour pouvoir recommencer.
Perte d'information
Lorsqu'une perte d'information survient, il y a plusieurs manières de palier à une perte.
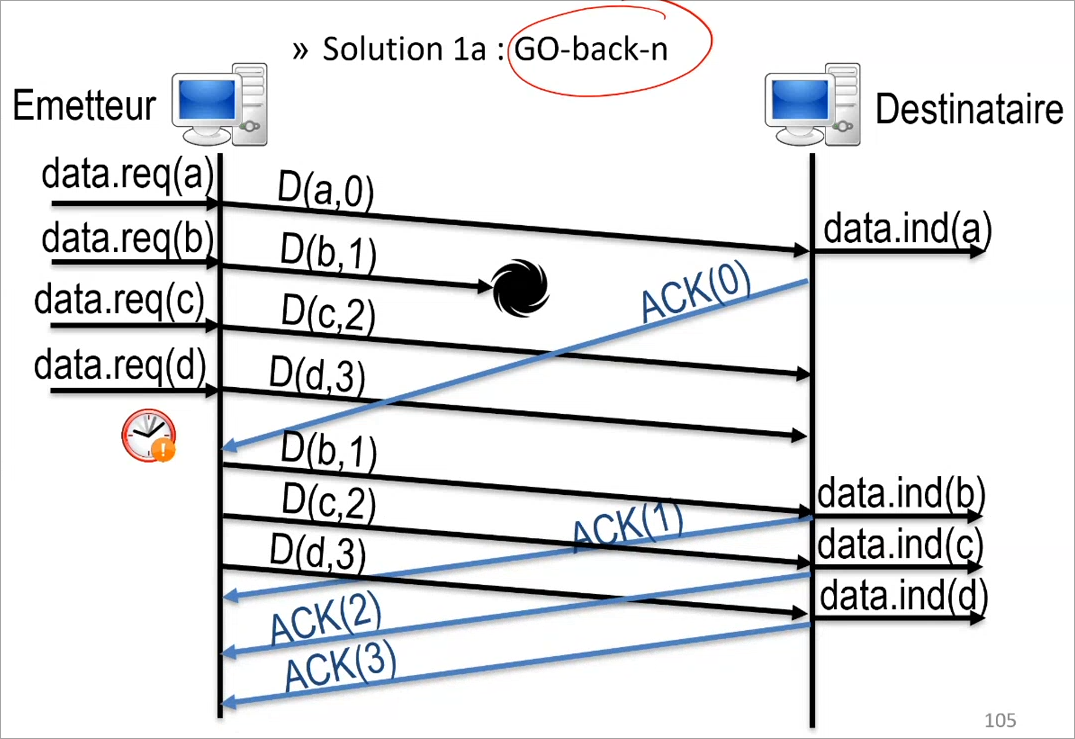
La première, c'est le go-back-n dans lequel le destinataire oublie tous les TPDU reçus hors séquence, ainsi s'il doit recevoir 0, 1, 2, 3, mais ne reçois pas 1, il ne va pas tenir compte de 2 et 3 et va dire à l'émetteur par un acquis : "J'ai seulement reçu le TPDU 0". L'émetteur devra alors re-envoyer les TPDU 1, 2 et 3 qui seront alors acquittés par le destinataire.
Cette méthode est avantageuse pour le destinataire, car il n'a pas besoin de retenir les TPDU hors-séquence, mais peu avantageuse pour l'émetteur qui doit tout réenvoyer.
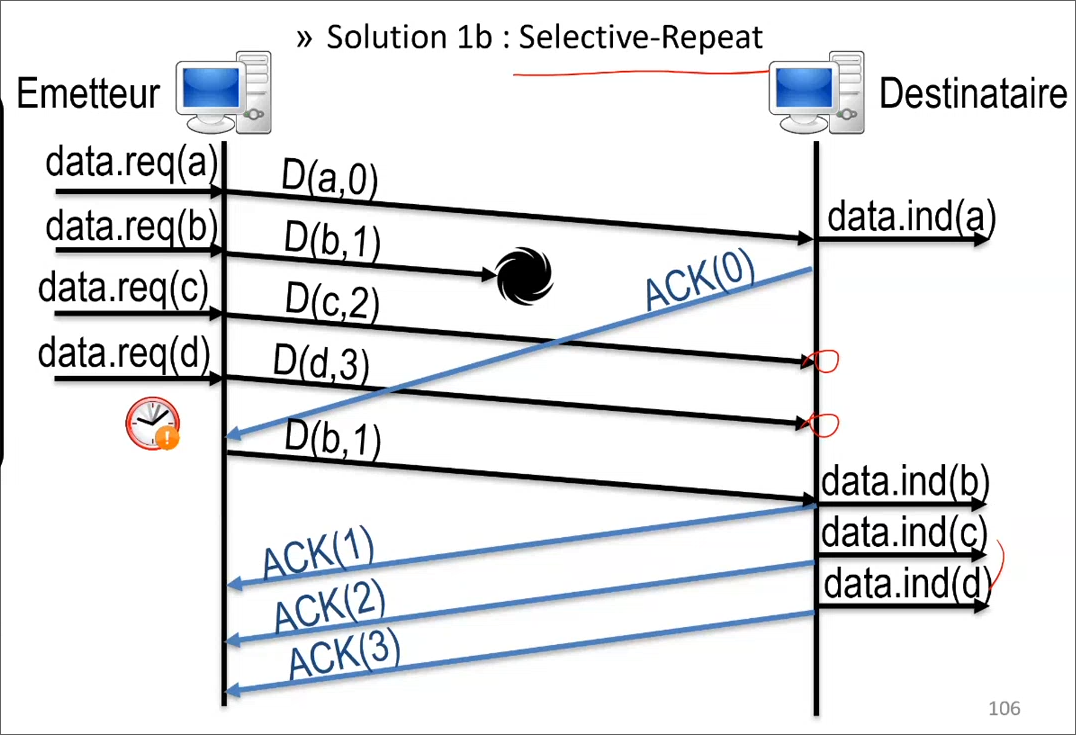
La deuxième méthode est le Selective Repeat (plus courante aujourd'hui) qui consiste à garder en mémoire les données hors séquence, si on reprend l'exemple précédent, si on attend de recevoir 0, 1, 2 et 3 et que l'on ne reçoit pas 1, alors on acquitte 0 qui a bien été reçu, l'émetteur envois alors la donnée suivate, 1. Le destinataire va ensuite acquitter tous les autres paquets reçus (1, 2 et 3) qui ne seront donc pas ré-envoyés.
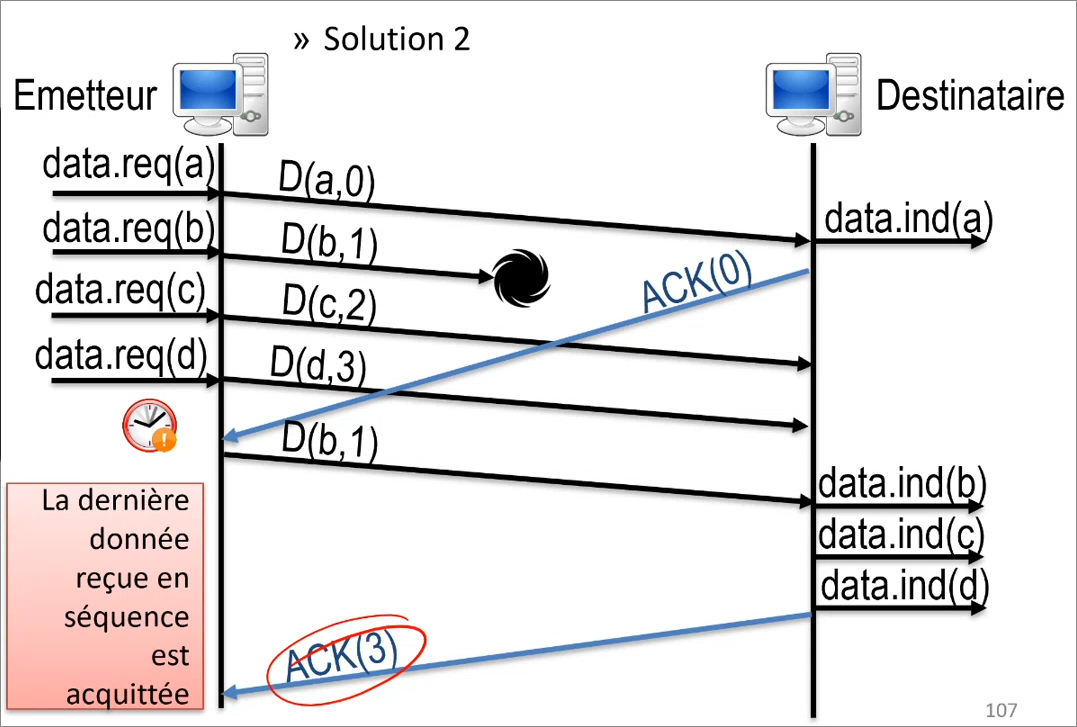
Pour ne pas avoir à acquitter tout un par un, on peut également acquitter la dernière information reçue en séquence (dans ce cas 3), ce qui équivaut à acquitter 1, 2 et 3 d'un coup, ce qui est donc plus efficace.
Capacité de traitement variable
Seulement, la capacité de traitement du destinataire peut varier, c'est pourquoi il va préciser dans ses acquis la taille actuelle de la fenêtre, plus la capacité de traitement du destinataire est grande, plus la fenêtre sera grande, et inversement.
À savoir qu'étant donné que les numéros de séquence sont réutilisés, il est possible d'avoir une duplication d'un acquis avec un certain numéro de séquence avec beaucoup de retard. Cela pourrait poser un problème si par hasard le numéro de séquence actuel est justement celui-là. C'est pourquoi la couche réseau (IP) s'occupe de faire un "timeout" sur les paquets, ainsi les paquets trop anciens sont juste oubliés, ce qui règle donc ce problème.
Connexion et déconnexion
Pour pouvoir commencer à transférer des données, il faut d'abord établir une connexion pour partager des informations initiales. Pour ce faire, on utilise un three-way handshake.
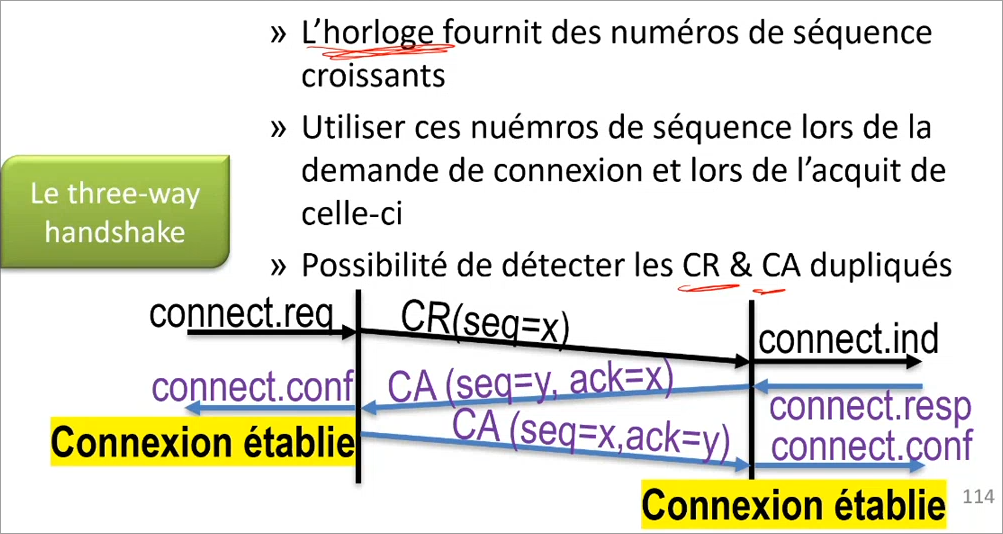
Le client va générer un numéro de séquence (x) et envoyer une demande de connexion au serveur avec ce dernier.
Le serveur va ensuite également générer un numéro de séquence (y) et acquitter la requête, la connexion est alors établie pour le client.
Enfin, le client va acquitter aussi, la connexion est alors établie pour le serveur.
Si une requête est dupliquée, le serveur va envoyer un acquis, mais le
client répondra par un REJECT pour indiquer que la connexion est
refusée, car il n'a pas fait de requête.
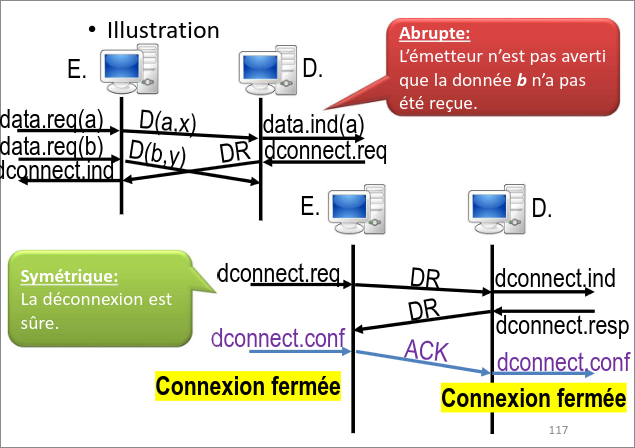
Pour ce qui est de la déconnexion, elle peut se faire soit de manière abrupte, c'est-à-dire que l'un des deux indique à l'autre "je me casse" et se déconnecte. Le problème, c'est que des données peuvent alors être perdues ou perdre l'information sur la déconnexion.
L'autre méthode est de se déconnecter de manière symétrique,
autrement dit de manière similaire au three-way handshake. A envois à
B une requête de déconnexion, B envois à A une requête de
déconnexion, A acquitte la requête à B et se déconnecte (et B fait
de même).
Communication bidirectionnelle
Souvent, il arrive que le client et le serveur doivent tous les deux transférer des données, ce qui complique donc un peu les choses.
Ainsi, on peut soit ouvrir deux connexions (une pour client → serveur et une pour serveur → client) mais cela ajoute donc beaucoup de trafic de contrôle et ralenti les choses.
Sinon, on peut utiliser le piggyback qui consiste à fusionner les TPDU de contrôle (acquis) et les TPDU de réponse en un seul TPDU ce qui diminue drastiquement donc la quantité de trafic de contrôle.
Implémentation protocole TCP
TCP est un protocole qui implémente le transfert fiable dont on a parlé juste avant. Il comprend 3 phases,
- La phase de connexion qui utilise un three-way handshake
- Le transfert d'informations en utilisant des acquits comme vu précédemment
- La fermeture de connexion
TCP fonctionne également en unicast, c'est-à-dire d'un destinataire à un autre et pas à un groupe de destinataire (pas multicast).
Une connexion dans TCP est identifié par quatre informations, le port source, le port de destination, l'IP source et l'IP destination.
TCP définit aussi un MSS (Maximum Segment Size) qui indique la taille maximum des données qui peuvent être dans un TPDU, cela dépends souvent de la couche réseau et de liaison utilisée, par exemple 1500 octets pour Ethernet.
Il y a par ailleurs une extension à TCP qui est utilisée dans la plupart des systèmes d'exploitations qui est le multipath TCP qui consiste à utiliser plusieurs accès réseaux simultanés pour transférer des données plus rapidement (par exemple utiliser la 4G et le Wifi en même temps).
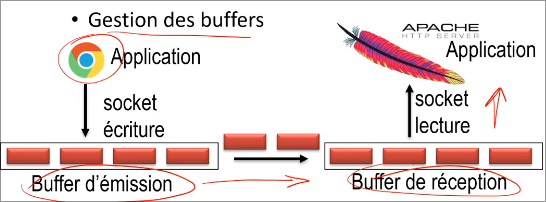
Pour ne pas tout le temps envoyer des choses sur le réseau en permanence, TCP utilise des buffers. Ainsi, lorsque qu'une application veut envoyer des TPDU, il les place dans un buffer d'écriture, une fois plein, les informations sont envoyées. Lors de la réception, les données sont placées dans un buffer de destination, une fois toutes les données reçues, les données sont envoyées à l'application.
TPDU TCP
Un TPDU TCP est composé de plusieurs informations :
- Port source
- Port destination
- Numéro de séquence
- Numéro d'acquittement
- Taille de l'entête
- Des indicateurs (ACK pour acquis, SYN pour demander une connexion, FIN pour terminer une connexion, etc)
- La taille de la fenêtre glissante
- Le "checksum" pour vérifier les données
- Le pointeur de donnée urgente et les options, qui ne servent à rien ou sont facultatives
- Données
Ce système permet donc de faire de la communication bidirectionnelle étant donné qu'il est possible de mettre des données et un acquit dans un même TPDU. On considère en TCP que l'acquit est toujours le prochain numéro de séquence attendu.
Temporisateur TCP
TCP doit également définir un temporisateur, c'est-à-dire mettre un "timeout" au bout duquel, si aucun acquit a été reçu, le(s) TPDU sont considérés comme perdu et doivent être renvoyé.
Ce délai doit donc être plus grand que le RTT (Round-Trip Time) qui est le temps de faire un aller-retour entre un émetteur et une destination. Aussi, si le RTT est très variable, le délai du temporisateur sera plus grand.
La valeur du temporisateur est alors $ RTTmoyen + 4 * RTTvariation $.
Envois des acquits
Il y a plusieurs cas différents d'envois d'acquits en TCP, lors de la réception d'un nouveau TPDU :
- SI on reçoit un TPDU ayant le numéro de séquence attendu ET que toutes les données ont été acquittées jusque-là, ALORS on attend jusqu'à 500 ms ET si aucun TPDU n'arrive au bout de ce délai, ALORS on acquitte le TPDU
- SI on reçoit un TPDU ayant le numéro de séquence attendu MAIS que toutes les données n'ont pas été acquittées jusque-là, ALORS on envoie un acquit pour tous
- SI on reçoit un TPDU ayant un numéro de séquence plus grand que prévu, ALORS on re-duplique l'acquit précédent pour demander le TPDU manquant
- SI on reçoit un TPDU couvrant un trou dans la séquence, ALORS on envoie acquit pour demander le prochain TPDU de la séquence
Fast retransmit
Une amélioration de TCP est le Fast Retransmit qui permet de ne pas avoir à attendre le timeout du temporisateur pour renvoyer un ou des TPDU.
Pour ce faire, le destinataire va envoyer des acquits pour tous les TPDU de la séquence, même ceux qui sont perdus. Ensuite, le destinataire va envoyer trois acquits identiques pour le TPDU perdu.
La réception de ces trois acquits est vue comme une demande de ré-envois de ces données par l'émetteur qui n'a ainsi pas besoin d'utiliser son temporisateur dans ce cas. Cela permet donc d'aller beaucoup plus vite.
Gestion des pertes avec TCP
TCP retient uniquement les TPDU qui arrivent en séquence (donc avec les numéros de séquence attendus à chaque fois).
Mais TCP sauvegarde tout de même les TPDU qui arrive hors séquence afin de ne pas avoir à les redemander plus tard.
La fast-retransmit vu plus tôt permet à TCP d'aller plus vite pour demander les données perdues à l'émetteur.
Algorithme de Nagle pour l'émission de TPDU
Il serait fort peu pratique d'émettre des TPDU pour chaque petite donnée, car avoir beaucoup de petit TPDU causerait des problèmes de congestion du réseau.
L'idée est alors de combiner plusieurs TPDU dans un seul, plus gros TPDU. Le fonctionnement de cet algorithme est celui-ci :
- Le premier octet est envoyé immédiatement
- Tant que l'accusé de réception n'est pas reçu, on accumule toutes les données suivantes dans un seul TPDU (tampon ou buffer). Lorsque l'acquittent arrive, on envoie le TPDU.
- On répète la deuxième étape.
Contrôle de flux et de la fenêtre
Le destinataire doit indiquer la taille de sa fenêtre (qui symbolise sa capacité de traitement) au fur et à mesure afin de ne pas être submergé de données.
L'émetteur de son côté est obligé d'attendre la réception d'un acquit lorsque la fenêtre est vide avant de recommencer à transmettre.
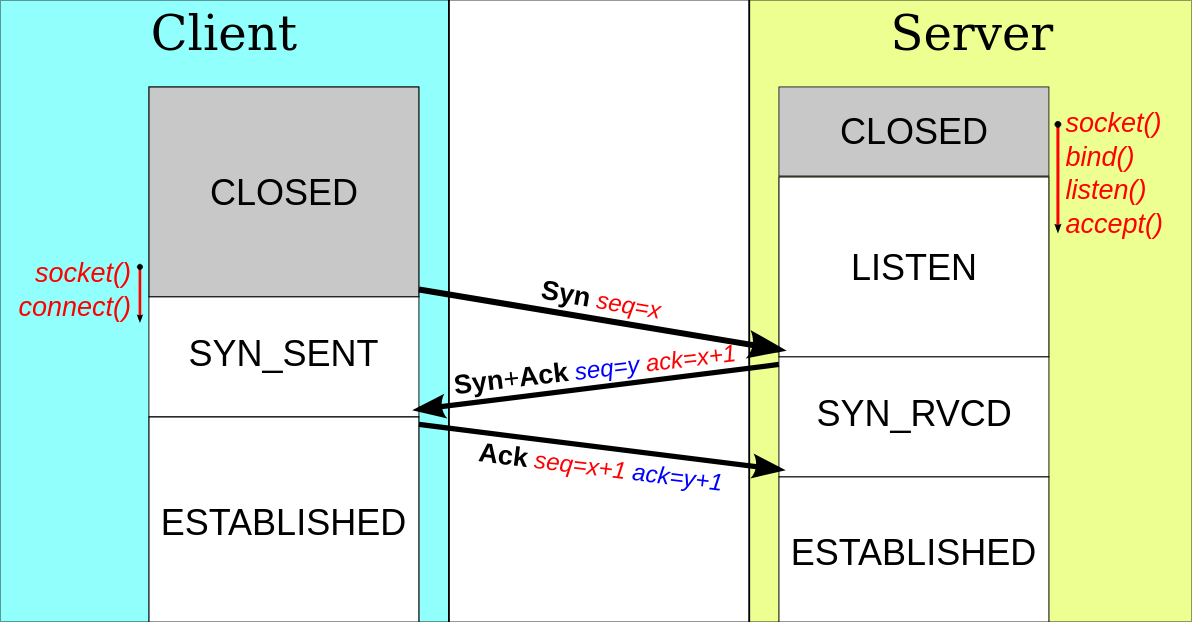
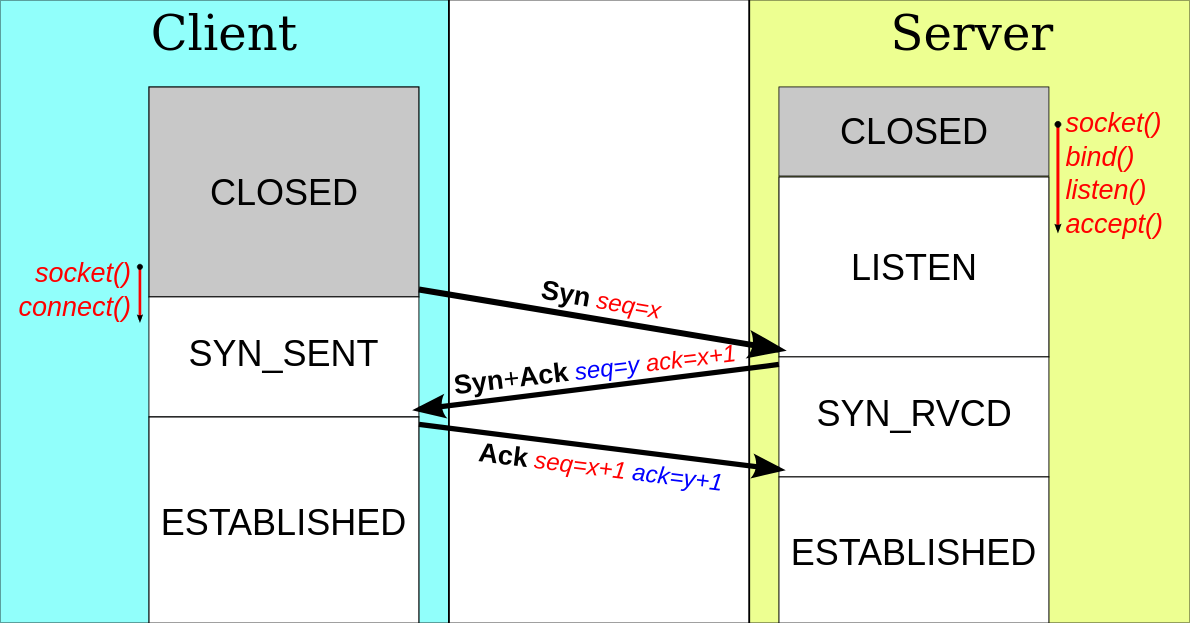
Connexion et déconnexion TCP
Une requête de connexion en TCP se fait avec le flag SYN. Le serveur
peut ensuite soit accepter en utilisant les flags SYN et ACK, ou
refuser avec RST et ACK. Si la connexion est acceptée par le
serveur, le client envois un ACK pour signaler qu'il est prêt à
commencer l'échange de données, ou un RST et ACK pour refuser et
annuler la connexion.
Voici ce qu'il se passe lorsque la connexion est acceptée par le serveur :
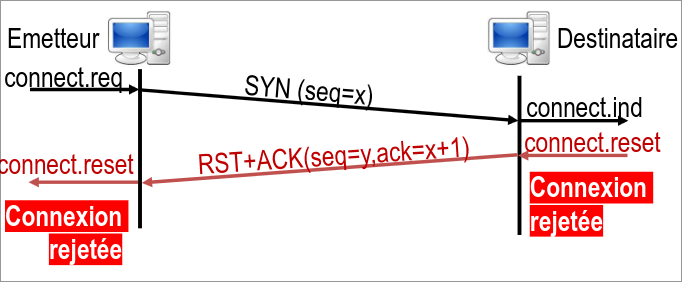
Voici ce qu'il se passe lorsque la connexion est refusée par le serveur :
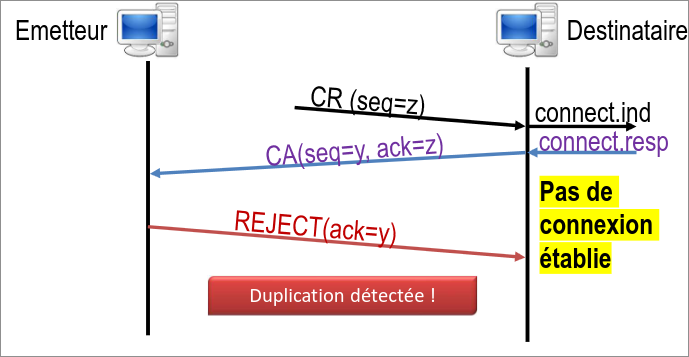
Et voici ce qu'il se passe lorsque la connexion est invalide et est
refusée par le client (compter que REJECT serait en TCP SYN+ACK) :
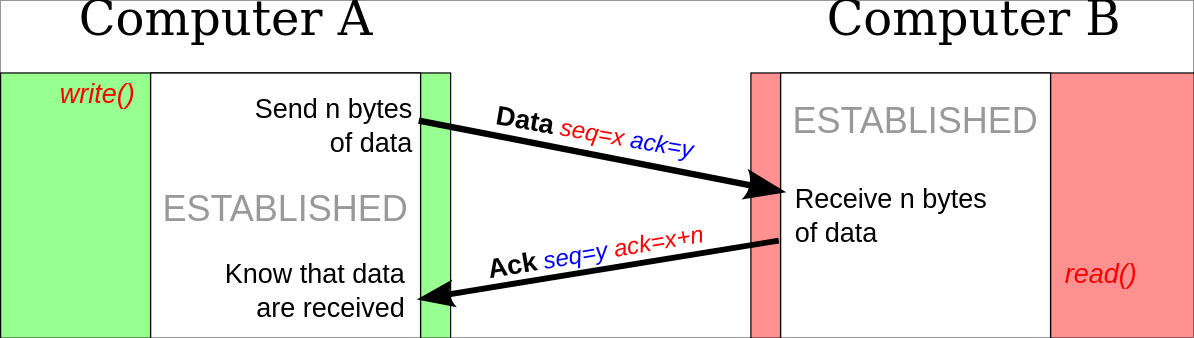
Une fois la connexion établie, un échange de donnée peut donc s'opérer :
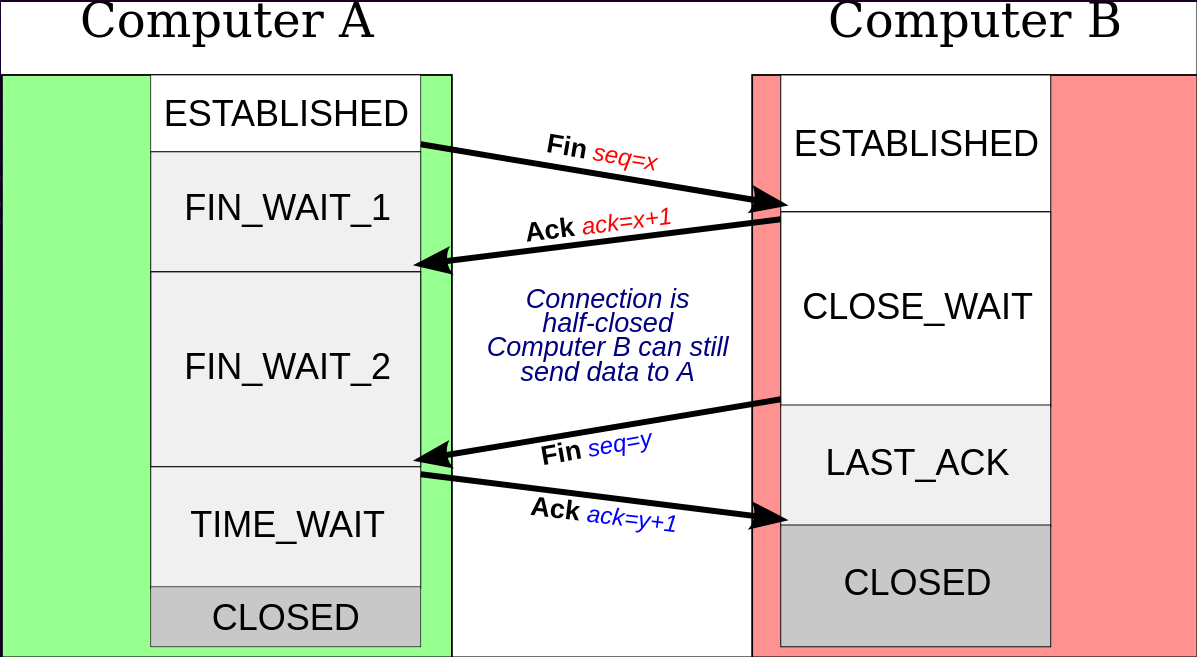
Une fois l'échange de donnée terminé, la connexion peut être fermée
correctement en utilisant une méthode similaire au three-way handshake
utilisé pour la connexion. On envoie un TPDU avec un flag FIN pour
demander la déconnexion, l'autre partie renvois donc un ACK transfert
également quelques dernières données, puis envois un FIN à son tour
qui a une réponse par un ACK. La connexion est alors fermée.
Il est aussi possible d'avoir une connexion abrupte, si un FIN est
envoyé sans attendre d'acquit. Vous pouvez avoir plus de détail en
lisant la partie plus tôt sur la déconnexion dans le transfert fiable.
Contrôle de la congestion
Tous les réseaux sur internet ne sont pas égaux, certains sont donc beaucoup plus lents que d'autres. Pour éviter de surcharger ces réseaux avec beaucoup de données, il est donc important de mettre en place un système permettant de limiter cette congestion.
Pour cela, l'émetteur va retenir une "fenêtre de congestion" (qui n'a rien à voir avec la fenêtre glissante).
Cette fenêtre de congestion indique la quantité de donnée qui peut être
transmise, elle est mesurée en MSS (maximum segment size, c'est-à-dire
la taille maximale d'un TPDU). Au départ, elle est à 1, et à chaque
ACK reçu, elle augmente de 1. Cette donnée va donc grandir de manière
exponentielle. Cette phase est appelée le slow-start.
Ensuite, une fois que la fenêtre atteint un certain maximum prédéfini, elle va ensuite grandir de manière linéaire en augmentant de 1 à chaque RTT (Round-Trip Time, donc il faudra attendre que toutes les données envoyées soient acquittées). Cette phase est appelée le AIMD (Adaptative Increase Multiplicative Decrease).
Ce qui est fait lorsque des données sont perdues dépends de comment on sait que les données sont perdues :
- Soit, on reçoit un Fast-Retransmit (3 acquits dupliqués), la congestion est alors définie comme légère et on définit le maximum de la fenêtre à la valeur actuelle de la fenêtre divisée par 2. Et on définit la valeur de la fenêtre au seuil. On reprend alors en mode linéaire (AIMD).
- Soit, il y a un timeout du temporisateur, la congestion est alors définie comme forte et on définit le maximum de la fenêtre à la valeur actuelle de la fenêtre divisée par 2. Et on met la valeur de la fenêtre à un et on recommence en slow-start (exponentiel).