Les processus
Un processus est un programme en cours d'exécution.
Un programme est donc un élément passif (un ensemble d'octets sur le disque) tandis qu'un processus est un élément actif (un programme en cours d'exécution).
Que comporte un processus ?
- Le code du programme
- Le program counter (à quel instruction on est dans le programme, qui permet de savoir quelle sera la suivante) et les registres
- La pile (stack) et les données du programme
Informations concernant le processus
- PID (process ID) qui est l'identifiant du processus
- PPID (parent process id) qui est l'identifiant du processus parent
- Priorité du processus
- Temps CPU : temps consommé au CPU
- Tables des fichiers
- Etat du processus
Etat
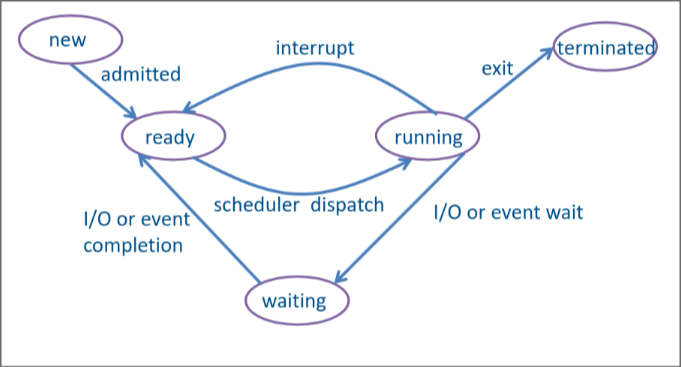
- new correspond à un programme qui a été sélectionné pour être démarré, ses instructions ont été recopiées en mémoire par l’OS et un nouveau processus y a été attaché mais pas encore exécuté, son contexte d’exécution et ses détails n’ont pas encore été préparés.
- ready le processus a été créé et dispose de toutes les ressources pour effectuer ses opérations
- running le processus a été choisi par le scheduler pour tourner, il va donc exécuter ses instruction jusqu’a écoulement du temps imparti. Si il a besoin de plus de ressource, il passe dans l’état waiting, si il a terminé son exécution il passe en état terminated sinon il peut encore passé en ready si un processus de plus haute priorité arrive.
- waiting le processus est en attente d’un évènement (exemple appui d’un bouton ou écoulement d’un certain temps) ou de ressources (exemple lecture de disque). Le processus ne peut rien faire pour l’instant.
- terminated une fois que le processus est terminé (ou a été tué), il libère la totalité des ressources qu’il a déténues.
Vous pouvez avoir plus d’information sur ce sujet en consultant ce site.
Pour exécuter plusieurs processus
Le système alterne très vite entre les différents états pour donner l'illusion que plusieurs processus s'exécutent en même temps.
En somme on garde en mémoire les processus, le scheduler va choisir les processus à exécuter; lorsqu'un processus est en attente un autre processus va être sélectionné pour être exécuté. Le but du scheduler est de maximiser l'utilisation du CPU.
Le scheduler
Le scheduler va sélectionner le processus à exécuter, c'est lui qui va alterner entre les différents états de chaques processus.
Le scheduler utilise un algorithme précis et il doit être le plus rapide possible.
Le scheduler classifie les processus selon leur type :
- Processus CPU (calculs)
- Processus E/S (I/O, entrée sortie)
On va toujours vouloir priviléger les processus entrée-sorties, qui sont ceux qui dialogues avec l'utilisateur et qui vont donner l'illusion que les choses d'exécutent en même temps.
Changement de contexte
Pour changer de processus on doit pouvoir sauvegarder le contexte (les données) du processus précédent.
Le système va donc sauvegarder toutes les informations du processus pour pouvoir le redémarrer plus tard.
Ensuite le scheduler va sélectionner un autre processus et en charger les informations/contexte pour le démarrer.
Il va ainsi faire cela tout le temps pour alterner entre tous les processus en attente, prêts et en cours pour maximiser l'utilisation du CPU et donner l'illusion que tout fonctionne en même temps.
Création d'un processus (fork)
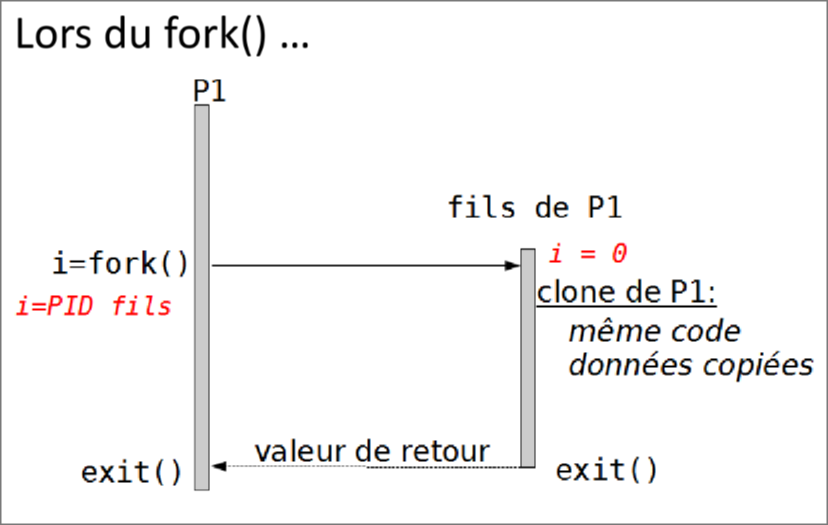
Pour créer un processus on utilise l'appel système fork. Le processus créé par un fork est appelé le processus fils, et le processus qui a créé le fils est appelé le père.
Le processus fils est un clone de son père, toutes les données du premier sont recopiées dans le fils.
La fonction fork() en C va retourner un entier :
-
-1si une erreur est survenue (comme souvent en C, une valeur négative veut dire qu'une merde s'est passée) -
0pour le processus fils - Le PID du fils pour le processus père
Exemples en C
Exemple simple
Voici un autre exemple :
#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>
#include <stdlib.h>
int main (void)
{
/* Variable pour stoquer la réponse du fork */
pid_t pid;
/* Fork et mise du résultat dans la variable */
pid = fork();
/* Si le pid est 0, alors c'est le fils qui lit l'info */
if (pid == 0) {
printf("Je suis le processus fils\n");
/* Si le pid est autre chose, alors c'est le père qui lit l'info */
} else {
printf("Je suis le processus père et mon fils est le : %d\n", pid);
}
/* Fin des deux processus */
return EXIT_SUCCESS;
}
Va retourner quelque chose comme :
Je suis le processus père et mon fils est le : 243328
Je suis le processus fils
Exemple plus complexe
#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>
#include <stdlib.h>
int main (void) {
/* La valeur de i par défault est 5 */
int i=5;
pid_t ret;
/* Ce code sera exécuté uniquement sur le père */
printf("Avant le fork() ... \n");
/* La valeur de retour sera 0 sur le processus fils, et le pid du fils sur le processus père */
ret = fork();
/* Le code à partir d'ici sera exécuté sur les deux processus */
printf("Après le fork() ... \n");
/* Sur le processus fils, i sera multiplié par 5 */
if(ret == 0) {
i*=5;
/* Sur le processus père, i sera additioné de 5 */
} else {
i+=5;
}
/* Le code ici sera exécuté sur les deux processus */
printf("La valeur de i est: %d\n", i);
/* On retourne la valeur de succès d'exécution ce qui va tuer les deux processus */
return EXIT_SUCCESS;
}
Va retourner :
Avant le fork() ...
Après le fork() ...
La valeur de i est: 10
Après le fork() ...
La valeur de i est: 25