Les processus
Un processus est un programme en cours d'exécution.
Un programme est donc un élément passif (un ensemble d'octets sur le disque) tandis qu'un processus est un élément actif (un programme en cours d'exécution).
Que comporte un processus ?
- Le code du programme
- Le program counter (à quel instruction on est dans le programme, qui permet de savoir quelle sera la suivante) et les registres
- La pile (stack) et les données du programme
Informations concernant le processus
- PID (process ID) qui est l'identifiant du processus
- PPID (parent process id) qui est l'identifiant du processus parent
- Priorité du processus
- Temps CPU : temps consommé au CPU
- Tables des fichiers
- Etat du processus
Etat
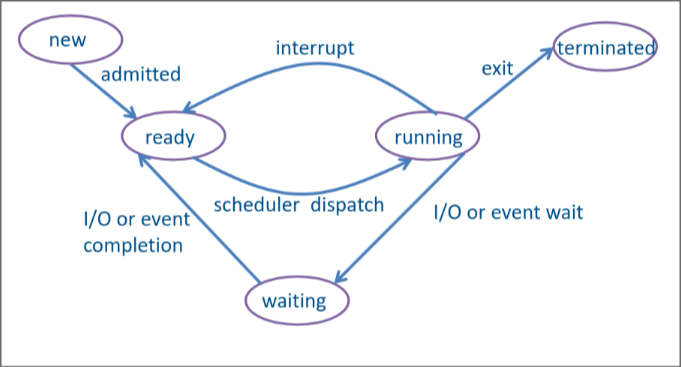
- new correspond à un programme qui a été sélectionné pour être démarré, ses instructions ont été recopiées en mémoire par l’OS et un nouveau processus y a été attaché mais pas encore exécuté, son contexte d’exécution et ses détails n’ont pas encore été préparés.
- ready le processus a été créé et dispose de toutes les ressources pour effectuer ses opérations
- running le processus a été choisi par le scheduler pour tourner, il va donc exécuter ses instruction jusqu’a écoulement du temps imparti. Si il a besoin de plus de ressource, il passe dans l’état waiting, si il a terminé son exécution il passe en état terminated sinon il peut encore passé en ready si un processus de plus haute priorité arrive.
- waiting le processus est en attente d’un évènement (exemple appui d’un bouton ou écoulement d’un certain temps) ou de ressources (exemple lecture de disque). Le processus ne peut rien faire pour l’instant.
- terminated une fois que le processus est terminé (ou a été tué), il libère la totalité des ressources qu’il a déténues.
Vous pouvez avoir plus d’information sur ce sujet en consultant ce site.
Pour exécuter plusieurs processus
Le système alterne très vite entre les différents états pour donner l'illusion que plusieurs processus s'exécutent en même temps.
En somme on garde en mémoire les processus, le scheduler va choisir les processus à exécuter; lorsqu'un processus est en attente un autre processus va être sélectionné pour être exécuté. Le but du scheduler est de maximiser l'utilisation du CPU.
Le scheduler
Le scheduler va sélectionner le processus à exécuter, c'est lui qui va alterner entre les différents états de chaques processus.
Le scheduler utilise un algorithme précis et il doit être le plus rapide possible.
Le scheduler classifie les processus selon leur type :
- Processus CPU (calculs)
- Processus E/S (I/O, entrée sortie)
On va toujours vouloir priviléger les processus entrée-sorties, qui sont ceux qui dialogues avec l'utilisateur et qui vont donner l'illusion que les choses d'exécutent en même temps.
Changement de contexte
Pour changer de processus on doit pouvoir sauvegarder le contexte (les données) du processus précédent.
Le système va donc sauvegarder toutes les informations du processus pour pouvoir le redémarrer plus tard.
Ensuite le scheduler va sélectionner un autre processus et en charger les informations/contexte pour le démarrer.
Il va ainsi faire cela tout le temps pour alterner entre tous les processus en attente, prêts et en cours pour maximiser l'utilisation du CPU et donner l'illusion que tout fonctionne en même temps.
Création d'un processus (fork)
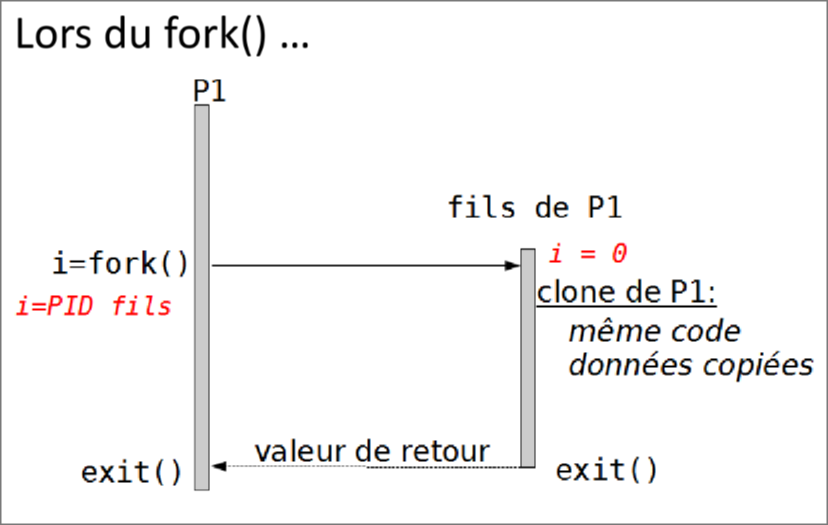
Pour créer un processus on utilise l'appel système fork. Le processus créé par un fork est appelé le processus fils, et le processus qui a créé le fils est appelé le père.
Le processus fils est un clone de son père, toutes les données du premier sont recopiées dans le fils.
La fonction fork() en C va retourner un entier :
-
-1si une erreur est survenue (comme souvent en C, une valeur négative veut dire qu'une merde s'est passée) -
0pour le processus fils - Le PID du fils pour le processus père
Exemples en C
Exemple simple
Voici un autre exemple :
#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>
#include <stdlib.h>
int main (void)
{
/* Variable pour stoquer la réponse du fork */
pid_t pid;
/* Fork et mise du résultat dans la variable */
pid = fork();
/* Si le pid est 0, alors c'est le fils qui lit l'info */
if (pid == 0) {
printf("Je suis le processus fils\n");
/* Si le pid est autre chose, alors c'est le père qui lit l'info */
} else {
printf("Je suis le processus père et mon fils est le : %d\n", pid);
}
/* Fin des deux processus */
return EXIT_SUCCESS;
}
Va retourner quelque chose comme :
Je suis le processus père et mon fils est le : 243328
Je suis le processus fils
Exemple plus complexe
#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>
#include <stdlib.h>
int main (void) {
/* La valeur de i par défault est 5 */
int i=5;
pid_t ret;
/* Ce code sera exécuté uniquement sur le père */
printf("Avant le fork() ... \n");
/* La valeur de retour sera 0 sur le processus fils, et le pid du fils sur le processus père */
ret = fork();
/* Le code à partir d'ici sera exécuté sur les deux processus */
printf("Après le fork() ... \n");
/* Sur le processus fils, i sera multiplié par 5 */
if(ret == 0) {
i*=5;
/* Sur le processus père, i sera additioné de 5 */
} else {
i+=5;
}
/* Le code ici sera exécuté sur les deux processus */
printf("La valeur de i est: %d\n", i);
/* On retourne la valeur de succès d'exécution ce qui va tuer les deux processus */
return EXIT_SUCCESS;
}
Va retourner :
Avant le fork() ...
Après le fork() ...
La valeur de i est: 10
Après le fork() ...
La valeur de i est: 25
Fin d'un processus
Un processus se termine quand il n'y a plus aucune instruction à
exécuter ou lorsque l'appel système exit(int) est appellé (cette
fonction permet de renvoyer une valeur entière au processus père).
wait et waidpid
Un processus père peut attendre la mort de son fils à l'aide des
fonctions wait() et waitpid() et peut ainsi récupérer l'entier
retourné par le exit(int) du fils.
La fonction wait() va simplement attendre la mort d'un fils (peu
importe lequel) tandis que la méthode waitpid() va attendre la mort
d'un processus fils déterminé.
Les fonctions wait et waitpid retourne le pid du fils, il faut donc
passer le pointeur d'une variable en argument pour récupérer les
valeurs. Voici un exemple :
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/wait.h>
#include <string.h>
int main(void) {
char chaine[100+1];
int compteur = 0;
pid_t pid_fils;
/* On crée un nouveau processus */
switch (fork()){
/* Si le résultat est -1 c'est qu'il y a eu un problème */
case -1:
printf("Le processus n'a pas été créé.");
exit(-1);
/* Si on est le processus fils, on demande d'entrer une chaine de caractères */
case 0:
printf("Entrez une chaine de caractères : ");
scanf("%100[^\n]%*c", chaine);
/* On retourne la longueur de la dite chaine en exit */
exit(strlen(chaine));
/* Si on est le processus père, on attends la mort du fils et on récupère la sortie du exit dans une variable */
default:
/* On stoque le retour du exit dans une variable ainsi que le PID du fils */
pid_fils = wait(&compteur);
/* On extrait la longueur de la chaine depuis la sortie du wait avec WEXITSTATUS */
printf("Enfant %d est mort. Compteur = %d", pid_fils, WEXITSTATUS(compteur));
}
return EXIT_SUCCESS;
}
execl
execl permet d'avoir de charger un autre dans le processus, une fois
cette fonction execl exécuté le code du processus remplacé est perdu.
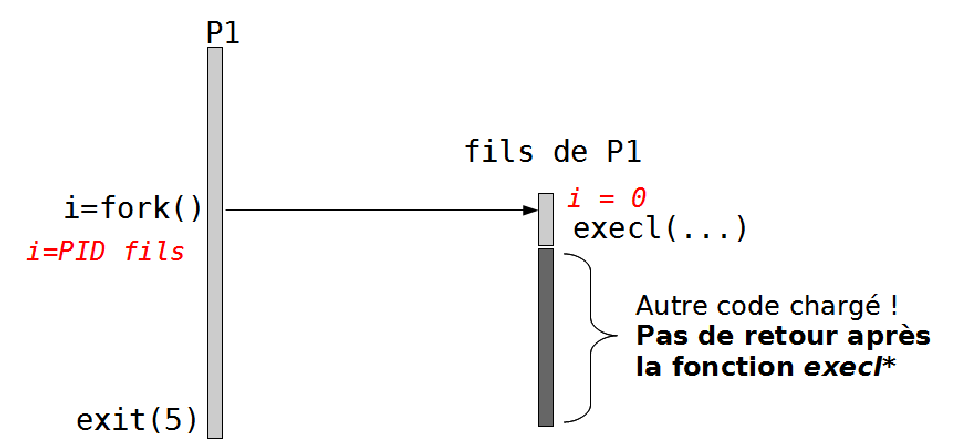
La fonction prends en paramètre, deux choses :
- Le chemin vers le programme
- Les arguments du programme ce qui commence par le chemin du programme (une deuxième fois) et qui termine par un NULL
Voici un exemple d'execl :
#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>
#include <stdlib.h>
#include <sys/wait.h>
int main(void) {
/* On crée un nouveau processus avec fork() */
switch(fork()) {
/* Si fork retourne -1 c'est qu'il y a eu un problème */
case -1: printf("Erreur fork()\n");
exit(-1);
/* Si fork retourne 0 c'est que c'est le processus fils, on va donc exécuter la commande ls avec execl */
case 0: printf("Je suis le fils\n");
/* Execl va lançer la commande "ls -l" */
/* Le premier paramètre est le chemin vers le programme */
/* Le deuxième paramètre est le chemin vers le programme qui va être passé en argument */
/* Le troisième paramètre est le flag "-l" qui sera passé en argument */
/* Le NULL termine la liste des arguments */
if(execl("/run/current-system/sw/bin/ls", "/run/current-system/sw/bin/ls", "-l", NULL)) {
/* Si le execl retourne -1, c'est qu'il y a eu une merde */
printf("Erreur execl()\n");
exit(-2);
}
printf("Ce code ne sera jamais exécuté car il est après le execl");
/* Pour le processus père, on va simplement attendre que le fils ai terminé */
default: wait(NULL);
printf("Mon fils a terminé\n");
}
return EXIT_SUCCESS;
/* Le switch n'a pas besoin de break car dans tous les cas, cela se fini par un exit, il ne peut donc rien y avoir après */
}
Choix des processus
Le scheduler du système d'exploitation doit sélectionner les processus à démarrer pour maximiser l'utilisation du CPU (généralement entre 40% et 90%) pour avoir un débit important.
Algorithmes
- FCFS (First-Come, First-Served), la file ici est une FIFO (first in, first out), c'est l'algorithme le plus simple à implémenter mais il peut être très long, car si le premier processus est long, il ralenti tous les processus qui suivent
- SJF (Shortest-Job First Scheduling), est une amélioration du précédent, il ordonne les processus selon leur durée, ainsi les processus les plus rapides viennent au début et les plus lents à la fin. Cet algorithme est seulement possible si on sait à l'avance la durée du processus, mais aujourd'hui c'est rarement le cas.
- Priorité, on tient compte de la priorité d'un processus, ainsi les
processus avec la priorité la plus élevée (nombre le plus petit) sont
exécutés avant.
- Cet algorithme peut être préemptif ce qui signifie qu'un processus qui tourne (running) peut être mis sur pause (en état ready) si un processus de plus haute priorité arrivé.
- Cependant cela peut mener à de la famine car les si il y a
continuellement des processus de plus haute priorité qui arrive.
- Ce problème peut être résolu en combinant l'age et la priorité (ainsi les processus ayant attendu trop longtemps passe avant)
- Round-Robin Scheduling (Tourniquet), les processus sont servi dans
l'ordre d'arrivée et chaque processus reçoit le CPU pour un temps
déterminé (appelé quantum), ainsi on va alterner entre chaque
processus avec un temps donné (c'est donc un algorithme préemptif)
- Si le quantum est grand, l'utilisateur·ice aura l'impression que le système lag car rien ne pourra être fait tant que le processus en cours est n'a pas fini son quantum
- Si le quantum est petit, alors on va perdre en efficacité du CPU car beaucoup de l'énergie de calcul sera mise dans le fait d'échanger tous les processus tout le temps.
Communication IPC
Il est nécessaire que le sprocessus communiquent entre-eux (pour le partage d'information, la répartition des calculs, la modularité et la facilité). La communication inter-process sont très courrant sous UNIX et servent à résoudre ce problème.
Différentes options
- Fichiers, cependant c'est très lent et difficile à synchroniser
- Tube nommé ou non-nommé
- Files de messages
- Mémoire partagée, qui a l'avantage d'être très rapide
- Socket (échanges via le réseau) qui est universel
Les tubes
Les tubes sont des petits fichiers géré en file circulaire, ils sont si petit qu'ils sont souvent en cache (ce qui est donc très efficace). Si le message devient trop grand, il sera alors découpé en blocs.
Tubes non-nommés
Les tubes non-nommés sont des tubes temporaires, ils sont alloué via
l'appel système pipe()
Il existe différents tubes standards :
-
stdintube de lecture (via le clavier, genrescanf) -
stdouttube de sortie (affichage à l'écran, genreprintf) -
stderrest un tube de sortie pour les messages d'erreurs
Il est ainsi possible de rediriger ces tubes.
Opérations
- Ecriture dans le tube avec appel système
write(int h, char* b, int s)(h étant le tube, s les premiers octets, et b le buffer) - Lecture dans le tube avec appel système
read(int h, char* b, int s) - Fermeture du tube via
close(int h)
Note les fonctions read et write retournent 0 si on tente d'écrire
ou de lire un tube sans qu'il n'y a pas de processus à l'autre bout du
tube.
Exemple
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/wait.h>
int main(void) {
int tube[2];
char buffer[255];
/* On crée le tube et on note les identifiant entrée et sortie dans le tableau */
pipe(tube);
/* On crée un nouveau processus */
switch(fork()) {
case -1:
printf("Erreur fork()\n");
exit(-1);
/* Pour le processus fils */
/* Le processus fils va lire le processus tube[0] pour avoir la lecture en écriture */
/* Le buffer va être la variable où les données vont être écrites */
/* Et enfin 's' est la taille que l'on va récupérer */
case 0:
/* Si le tube est vide, read va attendre que le tube soit rempli */
read(tube[0], buffer, 254);
printf("Message: %s\n", buffer);
break;
/* Pour le processus père : */
/* Ici on écrit "salut à toi" dans le tube en écriture (tube[1]), le buffer va donc contenir le message */
/* Le 's' va contenir la longueur du buffer */
/* Ainsi le message va être envoyé au fils */
default:
strncpy(buffer, "salut a toi", 12);
write(tube[1], buffer, strlen(buffer));
/* Ici on attends que le processus fils meurt, sinon le read du fils retournera 0 car il n'y aura plus le processus à l'autre bout car le programme sera terminé */
wait(NULL);
}
return EXIT_SUCCESS;
}
Redirections
Par défault les 3 tubes standard sont dirigé vers le stdout (ou stderr si configuré autremenet).
On peut également rediriger ces tubes, ainis ce qui était affiché à l'écran est alors dirigé automatiquement dans le tube ou peut être lu à partir d'un tube.
Utilisation en shell
# On liste les fichiers et on récupère toutes les lignes contenant "dia"
# grep prends comme entrée le résultat du ls
# C'est le shell qui va automatiquement rediriger le stdout du ls comme le stdin du grep
ls | grep "dia"
Fonctionnement
Voici un exemple de redirection :
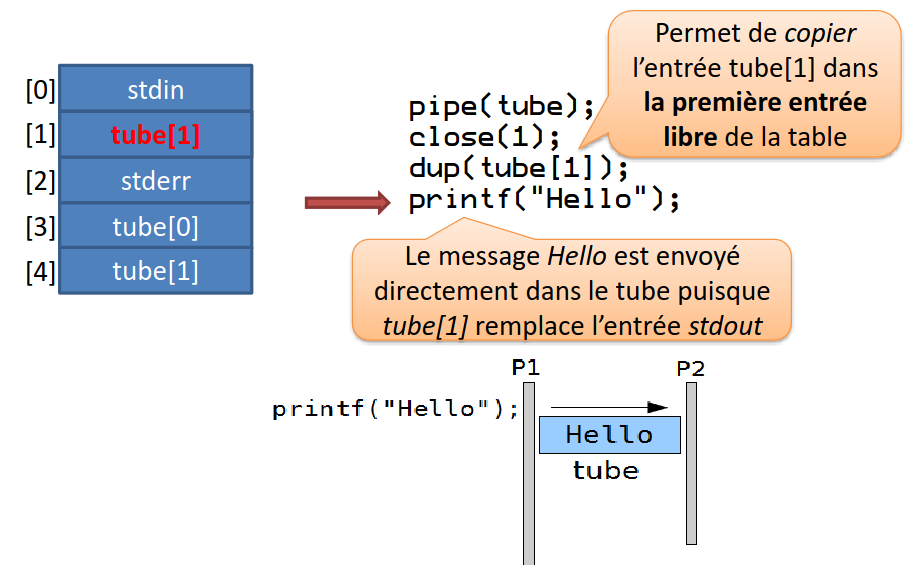
Dans cet exemple :
- On crée un tube
- On ferme le stdout
- On copie notre sortie de tube comme étant le stdout
- On écrit dans le stdout → donc dans notre tube
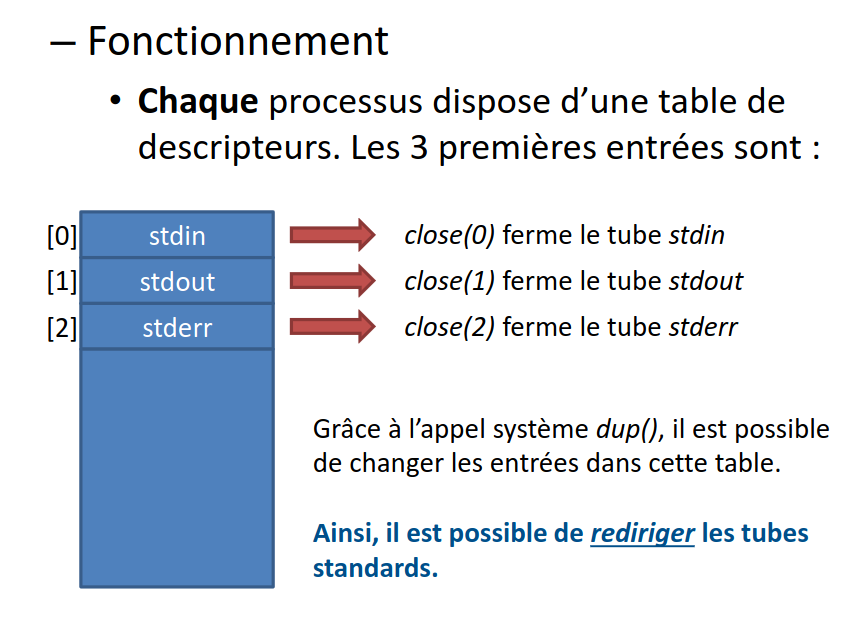
Exemple en C
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/wait.h>
int main(void) {
int tube[2];
char buffer[255];
/* On crée notre nouveau tube */
pipe(tube);
switch(fork()) {
case -1:
printf("Erreur fork()\n");
exit(-1);
/* Pour le processus fils */
case 0:
/* On ferme le stdin */
close(0);
/* On copie l'entrée du nouveau tube pour remplacer le stdin */
dup(tube[0]);
/* On lit depuis le stdin (on lit donc depuis le tube) */
scanf("%[^\n]%*c", buffer);
/* On affiche le message stdout */
printf("Message: %s\n", buffer);
break;
/* Pour le processus père */
default:
/* On ferme le stdout */
close(1);
/* On copie la sortie du tube dans le stdout */
dup(tube[1]);
/* On print un message vers le stdout, qui a été redirigé vers le nouveau tube */
printf("salut a toi\n");
/* On force le printf a se faire maintenant */
fflush(stdout);
/* On attends que le processus fils meurre pour éviter de causer une erreur de lecture du tube */
wait(NULL);
}
return EXIT_SUCCESS;
}
Autre exemple (avec execl)
Lorsque l'on redirige un pipe, le pipe reste redirigé si on exécute un
autre programme par après avec execl, on peut donc passer l'output
d'un programme dans un autre programme. Voici un exemple de pipe qui
prends le résultat du ls et compte le nombre de lignes, c'est
l'équivalent de ls | wc -l. Notez cependant que les path de ls et wc
sont très certainement différent sur votre système, pour connaitre
le PATH réel faites la commande whereis ls et whereis wc.
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/wait.h>
#include <sys/types.h>
int main(void) {
int tube[2];
/* On crée un nouveau tube */
pipe(tube);
/* On crée un premier enfant */
if (fork() == 0) {
/* On ferme le stdout */
close(1);
/* On redirige la sortie du tube dans le stdout */
dup(tube[1]);
/* On ferme les tubes pour laisser uniquement le stdin et stdout */
close(tube[0]);
close(tube[1]);
/* On exécute le ls */
execl("/run/current-system/sw/bin/ls", "/run/current-system/sw/bin/ls", NULL);
/* Puis ce que rien n'arrive après un execl le reste du code ne s'exécutera pas */
}
/* On crée un deuxième enfant */
if (fork() == 0) {
/* On ferme le stdin */
close(0);
/* On remplace le stdin par le tube[0] */
dup(tube[0]);
/* On ferme les tubes pour laisser uniquement les stdin et stdout */
close(tube[0]);
close(tube[1]);
/* On exécute wc -l ça récupère le stdin du ls */
execl("/run/current-system/sw/bin/wc", "/run/current-system/sw/bin/wc", "-l", NULL);
}
/* On ferme le tube[0] et tube[1] pour laisser uniquement le stdin et stdout */
close(tube[0]);
close(tube[1]);
/* On attends la mort des fils pour mourrir aussi */
wait(NULL);
wait(NULL);
return EXIT_SUCCESS;
}
Tubes nommés
Les tubes nommés sont permanent via des fichiers spéciaux dans le filesystem.
On peut en créer un en utilisant mkfifo(const char* nom, mode_t mode)
(le nom préise le nom du tube et le mode précise les permissions).
Les processus non-només sont liés entre père et fils, tandis qu'ici les processus nommés peuvent être utilisé par des processus qui bien que sont complètement indépendant l'un de l'autre.
Un processus peut ouvrir un tube en utilisant
open(const char* nom, int flags) (qui est bloquant par défaut tant que
le tube n'est pas ouvert des deux cotés), les flags définissent le mode
d'ouverture (écriture, lecture ou les deux bien que cela ne soit pas
recommandé).
On peut écrire dans un pipe avec write(int fd, char* buf, int size) et
lire avec read(int fd, char* buf, int size)
On peut enfin fermer un tube avec close(int fd)
Mémoire partagée
La mémoire partagée est un moyen très commun pour partager des informations entre processus, la zone de mémoire est commune à plusieurs processus. La taille est complètement configurable (comme avec malloc) et après un fork, le processus fils hérite de la mémoire partagée.
Allocation
L'allocation se fait via int shmget(key_t key, int s, int fl) où
- La clé est l'identifiant de la mémoire partagée
-
sest la taille en octets -
flest le flag de permission sur la zone
Petite note sur les permissions

Les permissions se font via un code tel que 0664 :
- Le premier
0indique que le nombre est en octal et non pas en décimal. Ainsi0644c'est110 110 100en binaire, et777est1 100 001 001en binaire. - Premier
6→ est le propriétaire signifie que le propriétaire peut lire et écrire(read (1) write (1) execute (0) = 110 = 6) - Deuxème
6→ est le groupe qui peut lire et écrire également (read (1) write (1) execute (0) = 110 = 6) - Enfin le
4→ les autres utilisateurs peuvent seulement lire (read (1) write (0) execute (0) = 100 = 4)
Shmat - Récupération de pointeur
L'appel shmat permet de récupérer un pointeur vers la zone mémoire
partagée. Sa signature de méthode est la suivante :
char* shmat(int shmid, char* addr, int flags) où
-
char*est le pointeur retourné -
int shmidest l'identifiant retourné par shmget -
char* addrest l'addresse souhaitée (généralement positionnée à 0 pour laisser le système choisir) -
int flagspour les paramètres de restriction (par exemple SHMRDONLY donne un pointeur en lecture seule)
Shmdt - Détacher la zone
L'appel shmdt (qui prends en argument le pointeur) va détacher la zone
mémoire sans pour autant la libérer.
Shmctl - Gérer la zone
L'appel int shmctl(int shmid, int cmd, struct shmid_ds* ds) permet de
gérer la zone de mémoire.
-
shmidest le descripteur de la zone retourné par shmget -
cmddétermine l'opération souhaitée (pour supprimer on utiliseIPC_RMIDmais il existe également IPCSTAT pour avoir des informations, IPCSET pour modifier les valeurs associées, etc) -
dscontient les données en rapport avec les commandes STAT et SET
Exemple
Disons que l'on veut faire 2 programme, 1 premier écrit dans la zone mémoire et le deuxième la lit :
- Premier programme :
#include <stdlib.h>
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/shm.h>
#include <string.h>
#define SHM_KEY 2324
#define K 1024
int main(void) {
int shmid;
char* ptr;
/* On alloue une zone de mémoire partagée avec l'identifiant 2324, une taille de 1024 octets, et une permission totale pour tout le monde */
shmid = shmget(SHM_KEY, K, 0777|IPC_CREAT);
/* Récupère un pointeur vers la zone de mémoire partagée */
ptr = shmat(shmid,NULL,0);
/* On copie une chaine de caractère dans la mémoire partagée */
strcpy(ptr, "Hello !\n");
/* On détache la zone mémoire (ce qui ne la libère pas mais permet qu'un autre processus l'utilise) */
shmdt(ptr);
/* On ferme le programme */
return EXIT_SUCCESS;
}
- Deuxième programme :
#include <sys/ipc.h>
#include <sys/shm.h>
#include <sys/types.h>
#include <string.h>
#include <stdlib.h>
#include <sys/msg.h>
#include <stdio.h>
#define SHM_KEY 2324
#define K 1024
int main(void) {
int shmid;
char *ptr;
/* On récupère la zone mémoire avec l'identifiant, la taille et le flag */
shmid = shmget(SHM_KEY, K, 0777);
/* Si le shmid retourné est < 0 alors c'est que la zone n'a pas été trouvée */
if (shmid < 0) {
printf("Erreur SHM\n");
exit(-1);
}
/* On récupère le pointeur de la mémoire partagée */
ptr = shmat(shmid, NULL, 0);
/* On print le contenu de la mémoire partagée */
printf("sa %d", IPC_CREAT);
printf("Contenu : %s\n", ptr);
/* On détache la mémoire du programme */
shmdt(ptr);
/* Le shmctl IPC_RMID va détruire la zone mémoire */
shmctl(shmid, IPC_RMID, NULL);
return EXIT_SUCCESS;
}
Commande ipcs pour lister les mémoires partagées
Si vous souhaitez voir la liste des zones partagées on peut utiliser la
commande ipcs.
[snowcode@snowcode:~]$ gcc mempar.c
[snowcode@snowcode:~]$ ./a.out
[snowcode@snowcode:~]$ ipcs
------ Message Queues --------
key msqid owner perms used-bytes messages
------ Shared Memory Segments --------
key shmid owner perms bytes nattch status
0x00000914 4 snowcode 777 1024 0
------ Semaphore Arrays --------
key semid owner perms nsems